2021年1月に、Dropbox では機械学習(ML)の予測能力によって、ドキュメント プレビューの生成およびキャッシュ方法を最適化し、年間で 170 万 US ドルのインフラストラクチャ コストを削減しました。Dropbox の機械学習はすでに、検索や、ファイルとフォルダの提案、OCR によるドキュメントのスキャンなど、一般的な機能に搭載されています。ML のアプリケーションは、すべてがユーザーの目に触れるわけではありませんが、さまざまな方法でビジネスにプラスの効果をもたらしています。
1. プレビューとは?
Dropbox プレビュー機能とは、ファイルをダウンロードせずにその内容を表示できる機能です。Dropbox では、サムネイルのプレビュー以外にも、コメントや他のユーザーへのタグ付けなど、共有や共同作業を可能にするインタラクティブなプレビュー画面を利用できます。
Dropbox 社内には、ファイルのプレビューを安全に生成する「Riviera」という名前のシステムがあります。Riviera では、サポート対象としている何百ものファイル形式のプレビューを生成しています。生成には、さまざまなコンテンツ変換操作を組み合わせ、対象のファイル形式に適したプレビュー アセットを作成するという方法を用いています。たとえば、Riviera では、複数ページの PDF ドキュメントを 1 ページにラスタライズし、Dropbox のウェブ画面に高解像度のプレビューを表示します。このコンテンツ全体をプレビューできる機能により、コメントや共有などの操作が可能となります。サイズが大きい画像アセットは、検索結果やファイル ブラウザの画面など、さまざまな場面でユーザーに表示されるよう、後でサムネイル画像に変換されます。
Dropbox では毎日、Riviera で数十 PB ものデータを処理しています。特定の種類の大容量ファイルでプレビュー処理を高速化するため、Riviera ではプレビュー アセットを事前生成し、キャッシュに保存します(この処理を「プレウォーム」と呼んでいます)。Dropbox がサポートする大量のファイルをプレウォームすると、CPU とストレージのコストは相当な金額に上ります。
 ファイル閲覧時のサムネイルのプレビュー。プレビューは拡大可能で、アプリケーション ファイルの代わりに操作することができます。
ファイル閲覧時のサムネイルのプレビュー。プレビューは拡大可能で、アプリケーション ファイルの代わりに操作することができます。
私たちは、機械学習を利用してこのコストを削減できるのではないかと考えました。というのも、事前生成されたコンテンツには、1 回も表示されないものがあったからです。プレビューが利用されるかどうかを効果的に予測できれば、確実にプレビューされるファイルだけをプレウォームすることで、コンピューティングとストレージのコストを節約できます。このプロジェクトを「Cannes(カンヌ)」と名付けました。これは、国際映画祭で世界各国の映画の試写会(プレビュー)が行われる、フレンチリヴィエラの街、カンヌにちなんでいます。
2. 機械学習におけるトレードオフ
プレビューの最適化では、その指針を規定する 2 つのトレードオフがありました。
ML によるインフラストラクチャの節約には費用便益のトレードオフがあり、それを調整することが 1 つ目の課題となりました。プレウォームするファイルが少なければコストは節約されます。コスト削減自体は望ましいことですが、本来プレウォームすべきファイルを誤って除外してしまうと、ユーザー エクスペリエンスを損なってしまいます。キャッシュにヒットしなければ、Riviera はその場でプレビューを生成する必要があり、ユーザーは結果が表示されるまで待つことになります。私たちは、プレビュー チームと共同でユーザー エクスペリエンスの低下を防ぐガードレール(予防策)を策定し、そのガードレールによってモデルをチューニングし、妥当な節約額が得られるようにしました。
もう 1 つのトレードオフは、複雑性およびモデルのパフォーマンスと、解釈可能性と導入コストとの間に発生するトレードオフでした。一般的に、ML には複雑性と解釈可能性との間にトレードオフがあります。つまり、モデルが複雑なほど予測精度は高まりますが、特定の予測が行われた理由を「解釈」することは難しくなります。また、開発においても複雑性が増すことになります。このプロジェクトの最初のイテレーションでは、解釈可能な ML ソリューションをできるだけ速く提供することを目標にしました。
よりシンプルで解釈可能性の高いモデルを採用することで、複雑性を高める前に、モデルを動作させることや、指標とレポートに注力できました。これは、Cannes が既存システムに新たに組み込む ML アプリケーションだったためです。問題が発生した場合や、Riviera が予想外の挙動を示した場合には、ML チームが簡単にデバッグし、原因が Cannes にあるのか、別の機能にあるのかを把握できました。1 日に約 5 億件近くのリクエストを処理するために、ソリューションは比較的簡単に低コストで導入できるようにする必要がありました。現行のシステムは、プレビュー可能な全ファイルを単にプレウォームするだけでしたので、その点を少しでも改善すれば節約につながります。善は急げということで、さっそく改善に取り組みました。
3. Cannes v1
上記のトレードオフを念頭に置いて、Cannes ではシンプルで、すぐにトレーニングできる、解釈性の高いモデルを実現することを目指しました。v1 のモデルは、ファイル拡張子、ファイルが保存されている Dropbox アカウントのタイプ、そのアカウントにおける最近 30 日間のアクティビティなどの入力特徴でトレーニングした勾配ブースト分類子です。オフラインのホールドアウト セットではこのモデルが、プレウォーム後の最大 60 日間に 70 % を超える精度でプレビューを予測できることがわかりました。このモデルでは、ホールドアウト内の約 40 % のプレウォーム リクエストが拒否され、パフォーマンスは当初設定したガードレール指標の範囲内となりました。偽陰性(閲覧されないだろうと予測したが、その後 60 日以内に閲覧されたファイル)が少数あり、プレビュー アセットをその場で作成するコストが発生しました。私たちは、「拒否された割合」という指標から偽陰性を差し引いて、年間の合計節約額が 170 万 US ドルであると概算しました。
プレビューの最適化という課題に着手する以前からも、潜在的な節約額が ML ソリューションを構築するコストを上回るようにしたいと考えていました。私たちは、Cannes で目標とする予想節約額を概算で見積りました。大規模な分散システムで ML システムを設計、導入する場合、システムへの変更を受け入れると、長期的には見積額に影響を及ぼします。最初のモデルをシンプルに保つことで、将来的に隣接するシステムに小規模な変更があったとしても、コストに対する効果を十分に価値あるものにしたいと考えました。トレーニングしたモデルを分析すると、v1 で実際に節約される金額がよくわかり、この投資には依然として価値があることが確認できました。
社内の機能ゲーティング サービス Stormcrow を使用し、Dropbox トラフィックの 1 % をランダムに選択したサンプルに対して、モデルの A/B テストを実施しました。このテストでは、モデルの精度とプレウォームされた「保存済みファイル」が、オフラインでの分析結果と一致することが立証されました。まさに朗報でした。Cannes v1 では、対象のファイルを一律でプレウォームしないので、キャッシュ ヒット率が下がると予想しました。実際に、A/B テストのホールドアウト母集団よりもキャッシュ ヒット率が 2 ポイントほど低いことが確認されました。この低下にもかかわらず、全体的なプレビュー レイテンシに大きな変化はありませんでした。
特に関心を持ったのはテイル レイテンシ(90 パーセンタイルよりも上のリクエストに対するレイテンシ)でした。というのも、キャッシュにヒットしなければテイル レイテンシが上昇し、プレビュー機能を使うユーザーにより深刻な影響を与えるからです。結果として、プレビューのテイル レイテンシと全体的なレイテンシのどちらにも悪化は確認されず、とても勇気づけられました。この実際のテストによって、v1 モデルを、より大きな Dropbox トラフィックに導入していくことに自信を深めました。
4. 大規模なライブ環境での予測
任意のファイルがプレウォーム パスを通る際に、そのファイルをプレウォームするかどうかについて、リアルタイムでの予測を Riviera に提供する方法が必要でした。この問題を解決するために、予測パイプラインとして Cannes を構築しました。Cannes では、ファイルに関連するシグナルを取得し、将来プレビューが利用される確率を予測するモデルにそれらのシグナルを提供します。
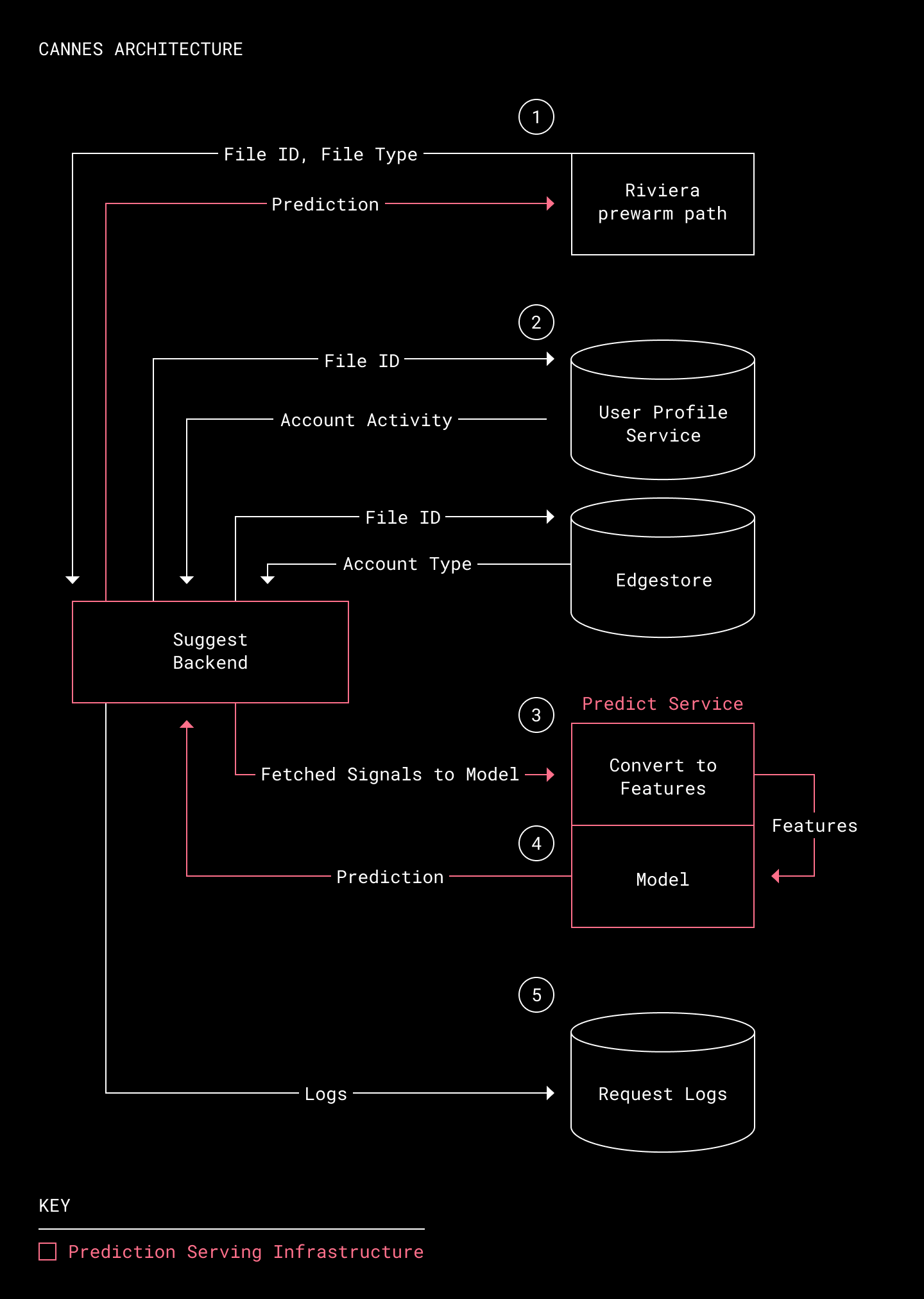 Cannes アーキテクチャの図
Cannes アーキテクチャの図
- Riviera プレウォーム パスからファイル ID を受信する:Riviera は、プレウォームの対象となるすべてのファイル ID を収集します(Riviera は Dropbox に保存されているファイルの約 98 % をプレビューできます。サポートされていないファイル形式と、サポートされているがプレビューできないファイルは少数です)。Riviera は、予測リクエストを送信し、予測対象となるファイルの ID とタイプを伝えます。
- ライブでのシグナルを取得する:予測時に、ファイルに関する最近のアクティビティのシグナルを収集するために、提案バックエンドという内部サービスを使用します。このサービスは、予測リクエストを検証し、そのファイルに関連する適切なシグナルを取得するためにクエリを送信します。シグナルは、Edgestore(Dropbox の主要メタデータ ストレージ システム)またはユーザー プロファイル サービス(Dropbox アクティビティのシグナルを集約する RocksDB データ ストア)のいずれかに保存されます。
- 機能ベクトルにシグナルをエンコードする:収集されたシグナルは、予測サービスに送信されます。このサービスでは未加工のシグナルを、ファイルのすべての関連情報を表す機能ベクトルにエンコードします。その後、評価のためにこのベクトルをモデルに送信します。
- 予測を生成する:モデルは、機能ベクトルを使用して、ファイル プレビューが利用される予測確率を返します。この予測は Riviera に戻され、Riviera は今後 60 日間でプレビューされる可能性が高いファイルをプレウォームします。
- リクエストに関する情報をログに記録する:提案バックエンドでは、機能ベクトル、予測結果、リクエストの統計をログに記録します。これらの情報は、パフォーマンスの低下およびレイテンシに関する問題のトラブルシューティングのために不可欠です。
追加の検討事項
上記のパイプラインは Riviera のプレウォーム機能にとってのクリティカル パスにあるため、予測レイテンシの低減が重要となります。たとえば、トラフィックの 25 % に対して導入した場合には、提案バックエンドの可用性を、社内の SLA 未満にまで低下させるエッジ ケースが確認されました。さらに調査すると、これらのケースはステップ 3 でタイムアウトしていることがわかりました。私たちは、機能をエンコーディングするステップを改善し、その他の最適化を予測パスにいくつか組み込むことで、これらのエッジ ケースでのテイル レイテンシを低減しました。
5. ML の操作
導入プロセスとその後の期間では、安定性と、プレビュー画面でユーザー エクスペリエンスに悪影響を与えないことを重視しました。複数レベルでのモニタリングとアラートは、ML 導入のプロセスにおける重要な要素です。
Cannes v1 の指標
インフラストラクチャ関連の予測指標:共有システムに対しては、アップタイムと可用性に関する社内独自の SLA があります。リアルタイムでのモニタリングとアラートには、Grafana のような既存のツールを利用しています。以下は、指標の例です。
- 提案バックエンドと予測サービスの可用性
- ユーザー プロファイル サービス(Dropbox のアクティビティ データ ストア)のデータの新しさ
プレビュー指標:プレビューのパフォーマンスを計る重要指標として、プレビュー レイテンシ分布を設けています。Cannes を使用した場合と使用しない場合のプレビュー指標を比較するために、3 % のホールドアウトを残しました。また、モデルのパフォーマンスを低下させる可能性があるモデル ドリフトや予期しないシステム変更が行われないようにしました。Grafana もアプリケーション レベルの指標に対する一般的なソリューションです。以下は、指標の例です。
- プレビュー レイテンシ分布(Cannes と Cannes なしのホールドアウト):特に 90 パーセンタイルより上のレイテンシに注目
- キャッシュ ヒット率 (Cannes と Cannes なしのホールドアウト):合計キャッシュ ヒット数/コンテンツのプレビューに対するリクエストの合計
モデル パフォーマンス指標:私たちには、ML チームが利用する Cannes v1 のモデル指標があります。この指標を計算するために、独自のパイプラインを構築しました。次に示すのは、注目すべき指標です。
- 混同行列:特に偽陰性の割合の変化に注目
- ROC 曲線下面積:混同行列の統計を直接監視する一方で、将来のモデルのパフォーマンスと比較できるよう ROC 曲線下面積(AUROC)も計算
上記のモデル パフォーマンス指標は、1 時間ごとに計算されて、Hive に保存されます。私たちは重要指標の可視化や、Cannes の経時的なパフォーマンスを示すライブダッシュボードの作成のために、Superset を使用しています。基盤となるモデルの挙動が変わると、指標テーブルから作成される Superset のアラートが事前に通知されます(ユーザーに影響が出ないよう、十分な猶予をもって送信されると理想的です)。
しかし、監視とアラートだけでは、システムを良好な状態に保つには不十分です。責任の所在とエスカレーション プロセスを明確にすることも必要です。たとえば、モデルの結果に影響を与える可能性がある、ML システム上流の依存関係について文書化しました。また、オンコールのエンジニアのために手順書も作成し、問題の発生箇所が Cannes なのか別の部分なのかを切り分けるトラブルシューティングのステップと、根本原因が ML モデルにある場合のエスカレーション パスを詳述しました。ML チームと他のチームとの間で密接に協力することで、Cannes は引き続きスムーズに稼働しています。
6. 現在の状態と今後の探求
現在、Cannes はほぼすべての Dropbox トラフィックに対して導入されています。結果として、年間 9,000 US ドルの ML インフラストラクチャ投資(提案バックエンドと予測サービスへのトラフィックが増加したことが主な要因)に対して、1 年間で推定 170 万 US ドルのプレウォーム コストを削減しました。
このプロジェクトの次回のイテレーションでは、心が躍るような多数の方法を探求していきます。より複雑なモデル タイプを試すことができるのは、Cannes システムのその他の部分が本番で運用されるようになったためです。また、モデルの基となる費用と使用量に関する詳細な社内データが増えれば、さらに微調整したコスト機能を開発することもできます。他にも、ML を活用した新しいプレビュー アプリケーションも検討しています。これは、ファイルごとにプレウォームするかしないかを二者択一で選ぶのではなく、より精度の高い判断を実現するしくみです。予測に基づくプレウォームに一段と工夫を凝らすことで、ファイル プレビュー時のユーザー エクスペリエンスを損なわずに、さらなる節約を実現できる可能性があります。
Cannes から得られた教訓や作成したツールを Dropbox における他のインフラストラクチャ プロジェクトにも広めていこうと考えています。インフラストラクチャ最適化のための ML は、期待の大きな投資分野です。
Cannes で協力してくれたプレビュー チームと ML プラットフォーム チームに感謝いたします。特に、ML チームのジーナ・ヒラ、ジョンミン・バク、ジェイソン・ブリセーノ、ニラジュ・クマール、クリス・コンセプシオン、プレビュー チームのアナガ・ムディゴンダ、ダニエル・ワグナー、ロバート・ハラス、そして ML プラットフォーム チームのイアン・ベイカー、ショーン・チャン、アディティア・ジャヤラマン、マイク・ローにこの場を借りてお礼を申し上げます。
執筆:ウィン・スエン
※本記事はこちらの英語ブログを翻訳したものです。