この数か月間、Dropbox のサーチ インフラストラクチャ エンジニアリング チームは、これまでの検索エンジンに代わる Nautilus という新しい全文検索エンジンのリリースに取り組んできました。
膨大なコンテンツを擁する桁外れのスケールに加え、5 億を超える登録ユーザーの 1 人ひとりに合った検索体験を提供しなければならない Dropbox にとって検索は特別な課題です。Dropbox の検索は複数の方法でカスタマイズされています。ユーザーはそれぞれアクセス権を持つドキュメントが異なるだけでなく、検索時の好みや行動も異なるからです。これは、ウェブの検索エンジンとは大きく異なります。ウェブの検索エンジンは、ユーザーの好みや行動にカスタマイズの焦点を当てていて、各ユーザーの検索対象は地域差を除けばほぼ同じドキュメント コーパスであるためです。
さらに、Dropbox が検索用にインデックスを作成するコンテンツには、かなり頻繁に変更されるものがあります。たとえば、レポートまたはプレゼンテーションを作成中のユーザー(またはユーザーのグループ)について考えてみてください。彼らは時間の経過とともに複数のバージョンを保存します。各バージョンで、そのドキュメントを検索するための検索語句が変わるかもしれません。
一般的に言えば、ユーザーが入力するクエリ(検索ワード)に対して、まさにそのタイミングでもっとも関連性の高いドキュメントを、可能な限りもっとも効率的な方法で検索できるようにしたいと考えています。そのためには、コンテンツに特化した機械学習(画像認識システムなど)から、検索結果をよりユーザーの好みに合わせてランク付けする学習システムまで、検索処理の複数の段階において人工知能を活用できることが求められます。
加えて、こうしたシステムは最適な動作を得るために一連の開発工程を何度も繰り返す必要があるため、さまざまなアルゴリズムやサブシステムを試行し、時間をかけて少しずつシステムを改善していけることが非常に重要です。そのため、Nautilus プロジェクトを開始する際に、主な目標を次のように4つ設定しました。
Nautilus プロジェクトの 4 つの目標
- Dropbox のデータ スケールに対して、業界最高水準のパフォーマンス、拡張性、信頼性を実現する
- ドキュメントのインテリジェントなランキングおよび検索機能を実装する基礎を提供する
- ドキュメントのインデックス作成とクエリ処理パイプラインをエンジニアが実験のために簡単にカスタマイズできるよう、フレキシブルなシステムを構築する
- ユーザー コンテンツを管理するすべてのシステム同様、検索システムも、これらの目標を速やかに、かつ確実に、そしてユーザー データのプライバシーをしっかりと保護できるように実現する必要がある
このブログ記事では、Nautilus システムのアーキテクチャとその主な特性、技術的な選択やデザインに対するアプローチに関する詳細、システムのさまざまな段階で機械学習(ML)を活用している方法を説明します。
目次
- アーキテクチャの概要
- インデックス作成
- サービング
- 検索インデックスの「オフライン」ビルドを定期的に生成する(平均して 3 日ごと)
- ファイルの編集や他のユーザーとのファイル共有など、ユーザーがファイルやユーザー同士とやり取りする際、「インデックス ミューテーション」を生成して、ほぼリアルタイムに近いタイミング(数秒間の差)でライブ インデックスと永続的な保存ドキュメントの両方に適用する
1-2. データのシャード化
2-1. ドキュメントの抽出と認識
2-2. オフライン ビルド
3-1. 検索エンジン
3-2. 検索オーケストレーター
3-3. 機械学習によるランキング
1. アーキテクチャの概要
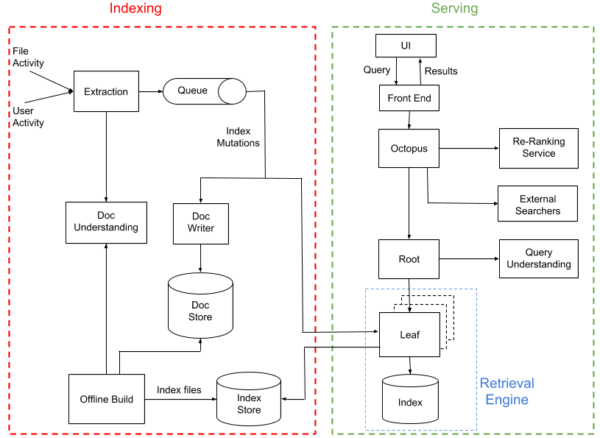
Nautilus は、インデックス作成とサービングという、2 つのほぼ独立したサブシステムから構成されています。
システム アーキテクチャ
インデックス作成パイプラインの役割は、ファイルとユーザーのアクティビティを処理し、そこからコンテンツとメタデータを抽出し、検索インデックスを作成することです。その後、サービング システムがこの検索インデックスを使い、ユーザーのクエリに対して検索結果を返します。このシステム全体は複数拠点に位置する Dropbox のデータ センターにわたり、1,000 以上の物理的ホストで、何万もの処理を実行します。
インデックスを構築するもっともシンプルな方法は、定期的に Dropbox のファイルすべてを反復し、それらをインデックスに追加して、サービング システムがリクエストに応答できるようにすることです。しかし、そのシステムでは Dropbox が必要とする、リアルタイムに近い状態でドキュメントの変化に対応することができません。そのため、スケールの大きな検索システムではわりと一般的な、ハイブリッドな次の2つのアプローチを取りました。
その他、ML を活用した「ドキュメント認識」などの各種コンテンツをインデックスする方法、ML に基づいたランキング サービスを使って取得した検索結果(その他の検索インデックスから取得したものも含む)をランク付けする方法といった、システムの主要な機能について取り上げます。
1-2. データのシャード化
Nautilus のサブシステムについて具体的に話す前に、必要なレベルのスケールを達成する方法について手短にお話しします。Dropbox は膨大なコンテンツを擁し、インデックスを作成する必要のあるデータの量も桁外れです。私たちはこのデータを複数のマシンに分け、「シャード化」しています。シャード化するに当たっては、各ユーザーの検索リクエストを迅速に応答しつつ、マシン間の負荷を比較的均等にできる方法を探る必要があります。
Dropbox にはすでに「名前空間(namespace)」という、ファイルをグループ化する枠組みがあります。これは、1 名以上のユーザーがアクセスできるフォルダと考えることができます。このアプローチが持つメリットの 1 つは、ユーザーがアクセス権を持つファイルの検索結果だけを表示できることであり、それが Dropbox が共有フォルダを許可している方法です。たとえば、共有フォルダは共有する人とされる人の両方がアクセスできる、新しい名前空間になります。Dropbox ユーザーがアクセスできるファイルは、そのユーザーがアクセス権を持つ名前空間によって完全に定義されています。 こうした名前空間の特性を踏まえると、ユーザーがある語句を検索する時、そのユーザーがアクセス権を持つ名前空間すべてを検索し、マッチするすべての結果をまとめる必要があります。これは、名前空間を検索システムに渡すことによって、検索するユーザーが、検索が実行されたタイミングでアクセスできるコンテンツだけを検索する、ということも意味しています。
Dropbox は複数の名前空間を 1 つの「パーティション」としてグループ化します。これは Dropbox がデータを保管し、インデックス化し、供給する、論理上の単位です。ニーズの変化に応じて名前空間の再パーティションを簡単に行えるパーティション スキームを使用しています。現時点で、2,048 のパーティションがあります。
2. インデックス作成
2-1. ドキュメントの抽出と認識
ユーザーはどのようなものを検索したいのでしょうか?その 1 つはもちろん各ドキュメントのコンテンツ、つまりファイル内のテキストです。しかし、それ以外にも、関連するデータやメタデータの種類は数えきれないほどあります。
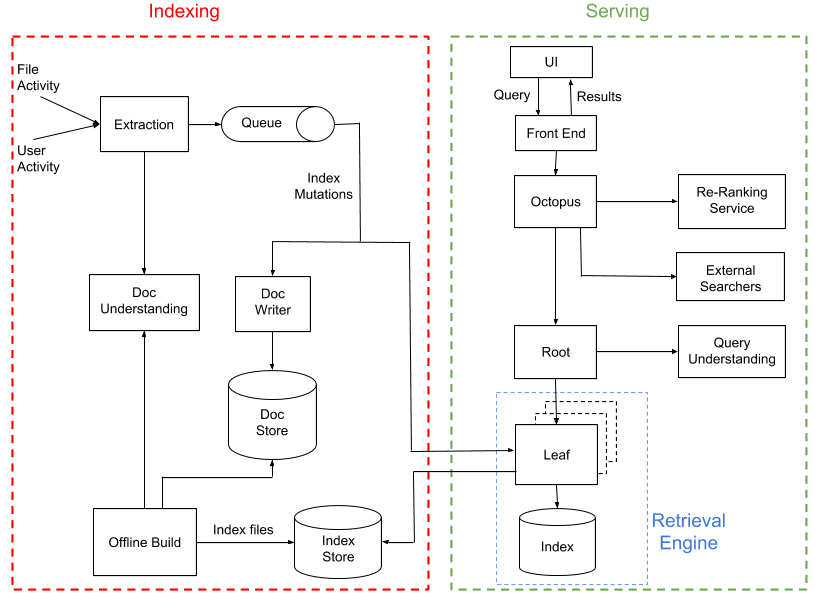
Nautilus はこうした情報やそれ以上のものに、複数の「エクストラクター」を定義する機能を通して柔軟に対応できるよう設計されています。このエクストラクターはそれぞれ、インプット ファイルから何らかのアウトプットを抽出し、「ドキュメント ストア」の列に入力します。ストアの基盤となる技術は HBase で、さらにアクセス制御とデータの暗号化を行う独自のレイヤーも追加しています。1 つのファイルあたり 1 行で、各列には特定のエクストラクターからのアウトプットが含まれています。この仕組みの大きなメリットの 1 つは、エクストラクターがその他のエクストラクターに干渉することを心配せずに、特定の行の複数列を同時に更新できる点です。
ほぼすべてのドキュメントで、オリジナルのドキュメントを標準的な HTML 表現に変換するために Apache Tika を利用しています。次に HTML 表現を解析して、「トークン」(単語など)とその「属性」(フォーマットや位置情報など)のリストが抽出されます。
トークンの抽出後、「ドキュメント認識」パイプラインを使ってさまざまな方法でデータを拡張します。このパイプラインは、任意のメタデータやシグナルの抽出を実験するのに適しています。インプットとしては、ドキュメントそのものから抽出されたデータを使用し、「アノテーション」と呼ばれる一連の追加データをアウトプットします。「アノテーター」という組み込み可能なモジュールがアノテーションの生成を行います。シンプルなアノテーターの一例として、未加工のトークンからトークンの語幹を生成する語幹モジュールがあります。また、よりフレキシブルな検索ができるようトークンを分散表現に変換するモジュールもあります。
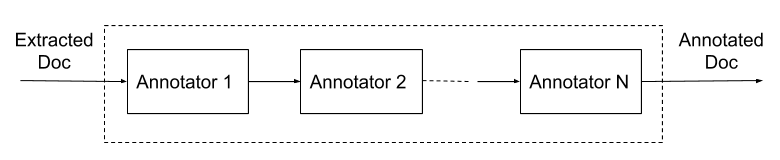
ドキュメント認識パイプライン
2-2. オフライン ビルド
ドキュメント ストアにはすべての検索コーパスが含まれていますが、検索を実行するのには適していません。これは、ドキュメント ストアに格納されているのが、抽出されたコンテンツおよび対応するドキュメント ID という構成だからです。検索を実行するためには、検索語句とドキュメント一覧のマッピングである、転置インデックスが必要です。オフライン ビルド システムの役割は、ドキュメント ストアの検索インデックスを定期的にリビルドすることです。このシステムは、クエリを非常に高速で処理できる検索インデックスをビルドするために、ドキュメント ストア上で MapReduce ジョブと同等の働きをします。各パーティションは最終的に、HDFS がサポートする「インデックス ストア」内に保管される一連のインデックス ファイルになります。
ドキュメント抽出プロセスとインデックス作成プロセスを分けることで、以下の4つの実験のために高い柔軟性を得ることができました。
2-2-1. インデックス自体の内部フォーマットを変更する
これには検索パフォーマンスを向上させ、ストレージのコストを減らす新しいインデックス フォーマットを試す機能が含まれます。
2-2-2. コーパス全体に新しいドキュメント アノテーターを適用する
アノテーターがインスタント インデックス作成パイプラインに入ってくる新しいドキュメントに適用され、効果が確認できると、それをオフライン ビルド パイプラインに追加するだけで数日以内にコーパス全体のドキュメントに適用できます。そのため、ドキュメント ストア内のデータ コーパスを更新するために多量のバックフィル スクリプトを実行する場合と比較して、実験の速度が上がります。
2-2-3. インデックス化されるデータのフィルタリングに使用するヒューリスティクスを改善する
当然のことですが、膨大のコンテンツを取り扱う場合、正確性やパフォーマンスを劣化させる原因になり得るエッジ ケースからシステムを保護する必要があります。たとえば、一部の極端に大きいドキュメントや、不適切に解析されてトークンが文字化けしているドキュメントなどが当てはまります。こうしたドキュメントをインデックスから除外するヒューリスティクスがいくつかあり、こうしたヒューリスティクスは、毎回ソース ドキュメントを再処理する必要なく、徐々にかつ簡単に更新できます。
2-2-4. 新しい実験によって発生する、予期しない問題を軽減する機能
インデックス作成プロセスにて何らかのエラーが発生した場合は、前のバージョンのインデックスに簡単にロールバックできます。この対策は、実験時のリスク耐性と反復の速度を高めます。
3. サービング
サービング システムは、ユーザーの検索クエリを受け入れて転送するフロントエンド、各クエリに対してマッチする膨大なドキュメントのリストを検索する検索エンジン、機械学習を使って複数のバックエンドからの結果をランク付けする Octopus というランキング システムから構成されています。フロントエンドは Dropbox の全クライアント(ウェブ、デスクトップ、モバイル)が使用する比較的シンプルな API なので、ここでは後者 2 つについて説明します。
3-1. 検索エンジン
検索エンジンは検索クエリにマッチするドキュメントを取得する分散システムです。このエンジンは、パフォーマンスと高い再現率のために最適化され、与えられた時間内に可能な限り多くの候補を返すことを目的としています。結果は検索統合レイヤーである Octopus によってランク付けされ、高い精度の達成、つまりもっとも関連性の高い結果がリストの上位に表示されるようになります。検索エンジンは、1 つの「ルート」と複数の「リーフ」に分けられます。
「ルート」
ルートは入力されるクエリを、データを保持する一連のリーフまで広げ、リーフから結果を受け取り、統合してから Octopus に返します。また、ルートには、前述のドキュメント認識パイプラインに非常によく似た「クエリ認識」パイプラインが含まれています。これは、クエリの変換またはクエリにアノテーションを行って検索結果を向上させることを目的としています。
「複数のリーフ」
各リーフは、名前空間のグループで実際のドキュメント検索を行います。リーフは、転置およびフォワード ドキュメント インデックスを管理します。基盤となるインデックス用データ ストアには、RocksDB を使用しています。このインデックスはオンライン ビルド プロセスからビルドをダウンロードすることによって定期的に分散され、Kafka のキューによって処理されたミューテーションを適用することで、継続的に更新されます。
3-2. 検索オーケストレーター
Dropbox の検索オーケストレーション レイヤーは Octopus といいます。ユーザーからのクエリを受け取って Octopus が最初に実行するタスクは、Dropbox のアクセス制御サービスを呼び出して、ユーザーが読み取りアクセス権を持つ正確な名前空間を判断することです。このセットは、下流の検索エンジンが実行するクエリの「範囲」を定義し、ユーザーがアクセスできるコンテンツのみを検索するようにします。
Nautilus 検索エンジンから結果を取得することに加えて、ユーザーに最終的な結果を返す前にいくつか行わなければいけないことが次のようにあります。
「統合」
主要なドキュメント ストアと検索エンジン(前述)の他に、特定の種類のコンテンツを検索するためにクエリを実行する必要がある、独立した補助的なバックエンド システムがいくつかあります。コンテンツの種類の例として、現在は別のスタックで実行されている Dropbox Paper のドキュメントが挙げられます。Octopus は複数のバックエンド検索エンジンに検索クエリを送信し、結果を統合する柔軟性があります。
「シャドウ エンジン」
複数のバックエンドから結果を供給する機能は、主要な検索エンジン バックエンドのアップデートをテストするのにも非常に便利です。検証フェーズ中は、検索クエリを本番システムとテスト中の新しいシステムの両方に送信できます。これはよく「シャドウ」トラフィックと呼ばれます。ユーザーには本番システムからの結果だけが返されますが、さらなる分析のために、両方のシステムからの検索結果やパフォーマンス測定の差異といったデータのログが作成されます。
「ランキング」
Octopus は、検索バックエンドから候補となるドキュメントを集めた後、必要に応じてさらなるシグナルとメタデータを取得してから、その情報を別のランキング サービスに送信します。その後、ランキング サービスは、スコアを算出してユーザーに返される最終的な結果のリストを選択します。
「アクセス コントロール(ACL)チェック」
検索エンジンが検索をクエリの範囲内で定義した名前空間に限定することに加え、Octopus レイヤーは、クエリを実行したユーザーが検索エンジンから返される結果にアクセスできることを再確認してから結果を返し、さらなる保護策を提供します。
すべてのステップは速やかに行われる必要があります。検索の 95 パーセンタイルに対して 500 ミリ秒という目標を設定しています(検索のうち 500 ミリ秒を超えてよいのは 5 % のみ)。それを実現する方法については、今後のブログ記事で説明します。
3-3. 機械学習によるランキング
すでに述べたとおり、Dropbox の検索エンジンは、それぞれのドキュメントがユーザーにどれだけ関連しているかをさほど考慮に入れず、マッチするドキュメントを大量に返すように作られています。ランキングのステップでは正反対の視点に立ち、ユーザーが今すぐ必要としている可能性が高いドキュメントを選んでいます(専門用語で言うと、検索エンジンは再現率、ランク付けは適合率に焦点を合わせています)。
ランキング エンジンは、それぞれのドキュメントに対して各種のシグナルに基づいたスコアを出力する ML モデルによって動いています。ドキュメントのクエリに対する関連性を測定するシグナル(例:BM25)もあれば、その時点でのドキュメントとユーザーとの関連性(例:ユーザーがやり取りを行った相手やユーザーが作業をしていたファイルの種類)を測定するシグナルもあります。
このモデルは、フロントエンドで取得され個人を特定可能なデータを除いて匿名化された「クリック」データによってトレーニングされます。過去の検索と、どの結果がクリックされたかに基づいて、大まかな関連性のパターンが学習できます。さらに、このモデルは頻繁に再トレーニングまたは更新を行うことで、徐々に一般的なユーザーの行動に適応し、学習していきます。
ランキングに ML ベースのソリューションを使用する主なメリットは、大量のシグナルが使えること、そして新しいシグナルを自動的に取り扱えることです。たとえば、利用できるシグナルの種類それぞれに対して、ユーザーが最近どのドキュメントを使ったか、ドキュメントには検索語句が何回含まれているかなどの「重要性」を手動で定義付けることを想像してみてください。シグナルの量が少なければできるかもしれませんが、何十、何百、あるいは何千といったシグナルを追加するとなると、適切に行うことは不可能になります。ML は、まさにこの点において役立ちます。適切な「重要性のレベル」を自動的に学習し、ドキュメントのランク付けに活用するため、もっとも関連性の高いドキュメントがユーザーに表示されます。たとえば、新しさに関連するシグナルが、結果の関連性を高めることに大幅に貢献することが、実験によってわかりました。
まとめ
Nautilus は、シャドウ モードで実行されていた適正判断期間を経て、現在では Dropbox の主要な検索エンジンになっています。すでに、新規コンテンツおよび更新されたコンテンツのインデックス作成時間は大きく改善されており、今後もさらなる改善が続きます。
強固な基盤ができた今、Dropbox のチームは Nautilus プラットフォームに追加する新しい機能の開発と検索クオリティの向上に取り組んでいます。既存のポスティングリスト検索アルゴリズムを分散スペースにおける距離ベース検索によって拡張する、自動タグ付けを使って画像、動画、オーディオ ファイルの検索を可能にする、より多くのユーザー アクティビティのシグナルを活用してさらにカスタマイズするなど、新しい機能を検討しています。
Nautilus は、Dropbox のエンジニアが取り組んでいる、データ検索と機械学習を使ったいくつかの大規模プロジェクトの中でも最たるものです。Dropbox では、こうした分野に関心がある方を募集しています。