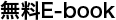この 4 年間、Dropbox では、デスクトップ クライアントの同期エンジンを白紙の状態から再構築しようと懸命に取り組んできました。同期エンジンは、デスクトップ パソコン上の Dropbox フォルダの陰に隠れた魔法です。これは、Dropbox で最も長く使われているコード部分であり、最も重要なコード部分の 1 つでもあります。今回、新しい同期エンジン(コードネーム「Nucleus」)をすべての Dropbox ユーザー向けにリリースさせていただくことを、ここに発表いたします。
同期エンジンの書き換えは本当に大変な作業で、多くの環境でマイナスともなりうる構想であったことに鑑みると、手放しで祝う気持ちにはなれません。結果的には Dropbox にとって素晴らしいアイデアであったわけですが、それは、私たちがこのプロセスにどのように取り組むべきかを熟考したからこそ、たどり着けたのです。ここでは特に、主要なソフトウェアの再構築についての考え方を紹介し、プロジェクトを成功に導いた主要なイニシアチブ(非常に簡潔なデータ モデル)にスポットを当てていきたいと思います。
それでは、時計を 2008 年に戻しましょう。Dropbox の同期機能が最初にベータ版に組み込まれた年です。一見すると、Dropbox の同期の多くは現在と同じように見えます。ユーザーが Dropbox アプリをインストールすると、パソコン上に魔法のフォルダが作成されます。そのフォルダにファイルを入れると、Dropbox サーバーや他のデバイスのファイルと同期されます。ファイルは、Dropbox サーバーに永続的かつ安全に保存され、インターネット接続があればどこからでも、これらのファイルにアクセスできます。
同期エンジンとは、パソコン上で動作し、リモート ファイル システムとのファイルのアップロードとダウンロードを調整するものです。
それ以来、ファイル同期は進化を続けました。当初は、ユーザーが個人利用で自分のデバイスにあるファイルを同期するものでした。現在、ユーザーは Dropbox を仕事に取り入れており、職場の共有階層で構造化された数百万ものファイルを利用しています。これらのファイルの内容は、多くの場合、パソコンのローカル ディスク容量をはるかに超えており、Dropbox スマート シンクを使用することで、必要なときにだけファイルをダウンロードできるようになりました。Dropbox には、数千億ものファイル、数兆ものファイル改訂履歴、および数エクサバイトもの顧客データがあります。ユーザーは何億ものデバイスからファイルにアクセスしており、すべてが巨大な分散システムでネットワーク化されています。
目次
-
- 大規模な同期は難しい
1-1. 分散システムは難しい
1-2. ファイル同期のテストは難しい
1-3. 同期動作の指定は難しい - なぜ書き換えるのか?
- 書き換えチェックリスト
3-1. 段階的な改善のために手を尽くしたか?
3-2. 書き換えを成功させることができるか?
3-3. 方向性を把握できているか? - 結果として、構築されたものは何か?
- 大規模な同期は難しい
1. 大規模な同期は難しい
ファイルの同期は大規模になるほど困難になります。それを理解することが、Dropbox がエンジン書き換えを決断した理由を理解する際に重要となります。「Sync Engine Classic」と呼ばれる最初の同期エンジンには、データ モデルに根本的な問題がありました。これらの問題は、大規模の場合にしか発生しなかったため、段階的に改善することができませんでした。
1-1. 分散システムは難しい
Dropbox 自体の規模も、システム エンジニアリング上の難しい課題です。しかし、物理的な規模を無視すれば、ファイル同期は分散システム固有の問題になります。なぜなら、クライアントが長期間オフラインになっても、オンラインに戻ったときに変更を調整できるからです。ネットワークの分断は、多くの分散システム アルゴリズムにとっては異常な状態ですが、私たちにとっては標準の動作です。
ユーザーの皆様は最も貴重なコンテンツを Dropbox に託しているわけですから、コンテンツを安全に保管することは絶対条件です。双方向の同期では多くの想定外の状況が発生しますが、サーバー上のデータを削除または破損しないようにすることよりも、データを保持し続ける「耐久性」のほうが難しい課題です。たとえば、Sync Engine Classic では、移動は、元の場所での削除と新しい場所での追加のペアとして表されます。一時的なネットワーク障害により、削除は通過しても、ペアとなる追加が通過しない場合を考えてみましょう。ユーザーはローカルにファイルを移動しただけなのに、サーバーにも他のデバイスにもファイルがなくなっていることに気づくでしょう。
場所を問わない耐久性実現は難しい
Dropbox は、ユーザーの設定に関係なく、ユーザーのパソコンで「とにかく使える」ことも目指しています。Dropbox は、Windows、macOS、Linux をサポートしていますが、それぞれのプラットフォームにはさまざまなファイル システムがあり、それらがすべて微妙に異なる動作をしています。ハードウェアは多岐にわたるため、OS 下では、OS 内の動作を変更するためのさまざまなカーネル拡張機能やドライバーのインストールが必要です。また、Dropbox 上では、アプリケーションはすべて、さまざまな形でファイル システムを使用しており、実際には仕様の一部ではない可能性のある動作に依存しています。
特定の環境での耐久性を保証するには、その実装を理解し、バグを減らし、場合によっては本番環境での問題をデバッグするときにリバース エンジニアリングを行う必要もあります。これらの問題は多くの場合、大規模な集団でのみ発生します。なぜなら、まれに起こるファイル システムのバグが影響を及ぼす可能性があるのは、ごく一部のユーザーに対してのみだからです。したがって、大規模環境では、多くの環境で「とにかく使える」ことと、強力な耐久性を保証することは、根本的に相反しています。
1-2. ファイル同期のテストは難しい
多数のユーザーを抱えている場合、理論的に起こり得ることは、ほとんどすべて本番環境で発生するでしょう。本番環境で発生する問題のデバッグは、開発環境で見つけるよりもはるかにコストがかかります(ユーザーのデバイスで実行されているソフトウェアの場合は特に)。したがって、大規模環境においては、本番環境にリリースする前に自動テストで新たな不具合を見つけることが非常に重要です。
とはいえ、ファイルの状態とユーザーの操作の可能な組み合わせは天文学的な数になるため、同期エンジンを十分にテストするということは困難です。共有フォルダのメンバーが数千も存在し、同期エンジンへの接続方法もさまざま、しかも、Dropbox ファイル システムの表示もそれぞれ更新されていない、といった可能性があるわけです。ユーザーごとにまだアップロードされていないローカルでの変更があるかもしれませんし、サーバーからのファイル ダウンロードの進行状況も部分的に異なっていることも考えられます。したがって、システムには多くの考えられる「スナップショット」があり、それらをすべてテストする必要があります。
システムの状態から取り得る有効な操作数も膨大になります。ファイルの同期は、大量の同時処理であり、ユーザーは同時に多くのファイルをアップロードおよびダウンロードできます。個々のファイルを同期させるには、コンテンツの塊を並行して転送し、ディスクにコンテンツを書き込み、ローカル ファイル システムから読み込む必要があります。包括的なテストでは、これらの操作のさまざまな並びでテストして、同時処理によるバグがシステムにないことを確認する必要があります。
1-3. 同期動作の指定は難しい
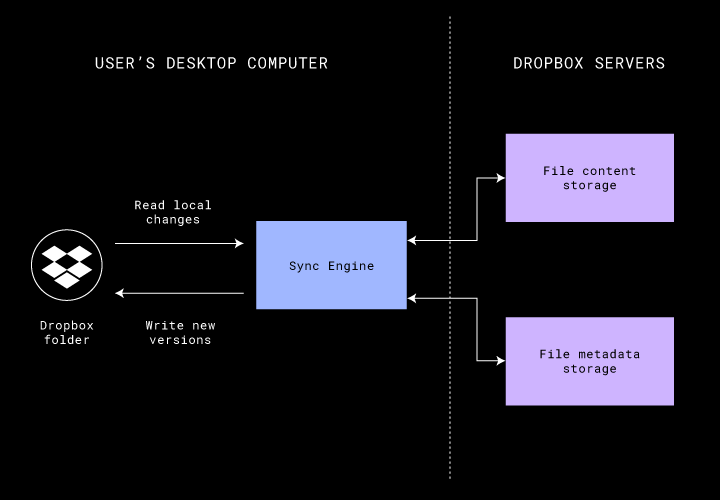
最後に、状態空間が大きいことが問題ではなかったとしても、同期エンジンの正しい動作を正確に定義することが困難な場合はよくあります。たとえば、3 つのフォルダがあり、1 つが別のフォルダの配下にある場合を考えてみましょう。
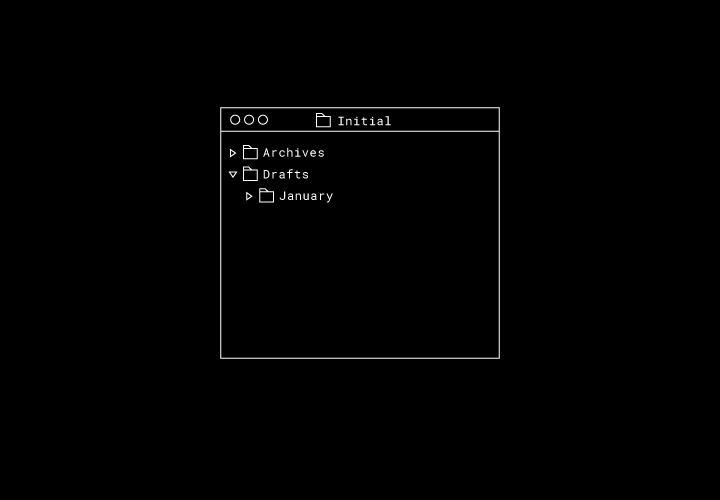
そして、このフォルダ内でオフラインで作業している 2 人のユーザー(Alberto さんと Beatrice さん)がいるとします。Alberto さんは「Archives」フォルダを「January」フォルダに移動し、Beatrice さんは「Drafts」フォルダを「Archives」フォルダに移動します。
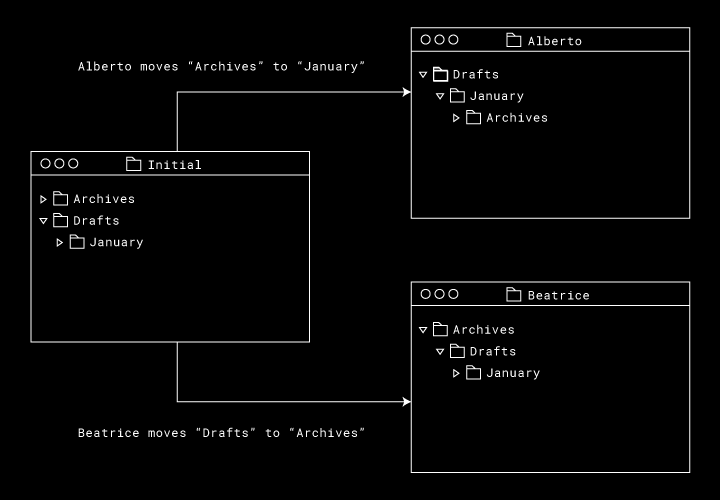
2 人がオンラインに戻ったらどうなるでしょうか。これらの動きを直接当てはめてみると、ファイル システムの図に循環が生じます。「Archives」フォルダは「Drafts」フォルダの親、「Drafts」フォルダは「January」フォルダの親、「January」フォルダは「Archives」フォルダの親です。
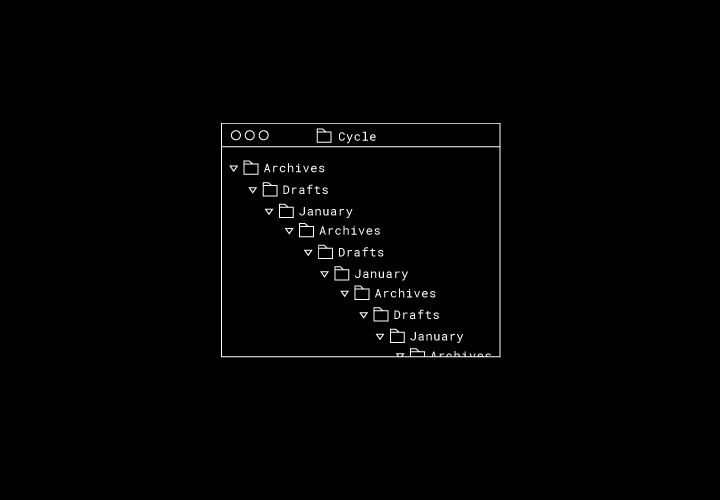
この状況で、正しい最終システムの状態はどうなるでしょうか。Sync Engine Classic では、各ディレクトリを複製し、Alberto さんのディレクトリ ツリーと Beatrice さんのディレクトリ ツリーをマージします。Nucleus では元のディレクトリが保持され、最終的な順序としては、どの同期エンジンが最初にディレクトリの移動をアップロードしたのかにより異なります。
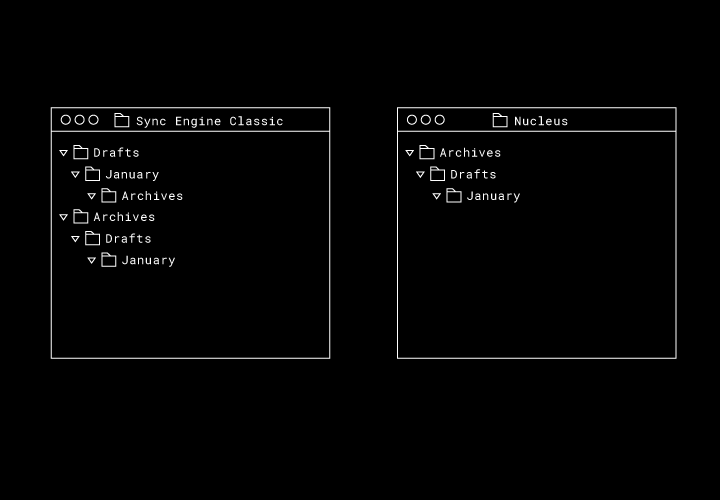
この例は 3 つのフォルダと 2 つの移動というこの単純なものですが、Nucleus では最終的な状態は満足のいくものになります。とはいえ、「例外リスト」の海で溺れないようにしながら、一般的な同期動作を指定するにはどうすればよいのでしょうか?
2. なぜ書き換えるのか?
前述のように、大規模なファイル同期は困難です。2016 年当時は、この問題はほとんど解決したように思えました。数億人のユーザーを抱え、スマート シンクといった新製品の機能もリリースを控え、同期に関する強力な専門家チームもいました。Sync Engine Classic では、何年にもわたり本番環境で鍛えられ、非常にまれなバグでさえも見つけ出して修正することに時間を費やしていました。
ジョエル・スポルスキ氏は、コードを一から書き換えることは「ソフトウェア開発会社が犯す可能性のある最悪の戦略的ミスの 1 つ」であると述べています。書き換えを成功させるには、多くの場合、機能開発を遅らせる必要があります。なぜなら、従来のシステムに織り込まれた機能向上を新しいシステムに移植する必要があるからです。そしてもちろん、同期エンジニアが取り組むことができたであろうユーザー向けのプロジェクトはたくさんありました。
しかし、こうした成功とは裏腹に、Sync Engine Classic は非常に不健全な状態でした。スマート シンクを構築する過程で、醜いコードを一掃し、インターフェースをリファクタリングし、さらには Python 型注釈を追加するなど、システムの多くの部分を段階的に改善していきました。大量のテレメトリを追加し、メンテナンスを安全かつ容易に行うことができるようなプロセスを構築しました。しかし、これらの段階的な改善だけでは不十分でした。
同期動作に何らかの変更を加えるには、根気のいるロールアウトが必要でしたが、本番環境では依然として複雑な矛盾が見られました。チームは何もかも中断して、問題を診断、修正し、アプリを良好な状態に戻すのに時間を費やさなければなりませんでした。私たちには強力な専門家チームがいましたが、新しいエンジニアをこのシステムに参加させるのに何年もかかりました。最後に、段階的なパフォーマンスの向上にも時間をかけましたが、同期エンジンが管理できるファイルの総数を大幅に増やすことはできませんでした。
これらの問題にはいくつかの根本的な原因がありましたが、最も重要な原因は Sync Engine Classic のデータ モデルでした。データ モデルは、共有のないシンプルな世界を対象として設計されており、移動の間に保持される安定した識別子がファイルに欠けていました。一貫性の保証はほとんどありませんでした。理論的には可能性はあるけれども「極めてまれにしか起こらない」ことが本番環境で発生するという問題のデバッグに何時間も費やしていました。システムの基本構成単位を細かく分割して変更することは不可能であることが多く、効果的かつ段階的な改善策はすぐに尽きてしまいました。
もう 1 つは、テストが容易になるようにシステムが設計されていないという点でした。私たちは、自動化されたプレリリース テストではなく、時間をかけたロールアウトとフィールドでの問題のデバッグに頼らざるを得ませんでした。Sync Engine Classic の寛容なデータ モデルでは、ストレス テストでのチェックがあまりできませんでした。断言はできませんが、望ましいとはいえないまでも正しさが証明された成果が大量にあったからです。システムが有効な状態にあるかどうかを常に容易にチェックできるため、タイトな不変条件を持った強力なデータ モデルがあると、テストには非常に役立ちます。
先に書いたように、同期はまさに同時性の問題であり、同時性のコードのテストやデバッグが困難であることはよく知られています。Sync Engine Classic のスレッドベースのアーキテクチャは、スケジューリングの決定をすべて OS に委ねてしまい、統合テストを再現できないものにしてしまいました。実際には、結局、長期間保持された非常に粒度の粗いロックを使用することになりました。このアーキテクチャでは、システムの推論容易性実現のために、並列処理の利点が犠牲になってしまいました。
3. 書き換えチェックリスト
書き換えると決断した理由を「書き換えチェックリスト」に書き出してみましょう。これは、他のシステムに対する同様の決断にも役立ちます。
3-1. 段階的な改善のために手を尽くしたか?
□コードをより良いモジュールにリファクタリングしてみたか?
コードの品質が低いというだけでは、システムを書き換えるもっともな理由にはなりません。変数の名前の変更や絡み合ったモジュールのもつれの解消は、すべて段階的に行うことができます。Sync Engine Classic では、この対処に多くの時間を費やしました。Python のダイナミズムが、この対処を難しくしてしまう可能性があるため、MyPy 注釈を追加して、コンパイル時に、少しずつ、そして、より多くのバグが見つかるようにしました。しかし、システムのコア プリミティブは同じままでした。なぜなら、リファクタリングだけでは根本的なデータ モデルを変更できないからです。
□ホットスポットを最適化することでパフォーマンスを改善しようとしたか?
ソフトウェアでは、多くの場合、コードのごく一部のためにほとんどの時間を費やします。パフォーマンスの問題の多くは根本的なものではありません。プロファイラーによって特定されたホットスポットの最適化は、パフォーマンスを段階的に強化する優れた方法です。私たちのチームは数か月間、パフォーマンスと規模拡大に取り組んでいましたが、ファイル コンテンツの転送パフォーマンス改善に大きな成果を上げていました。しかし、システムで管理可能なファイルの数を増やすといったメモリ フットプリントの改善には至っていませんでした。
□段階的に価値を提供できているか?
書き換えの実行を決めたとしても、中間的な価値を提供することでリスクを軽減できるでしょうか? 答えはイエスです。そうすることで、初期段階で技術的決定の検証ができ、プロジェクトの勢いの維持につながります。また、書き換えることで機能開発が遅れてしまうという心理的なダメージも軽減できます。
3-2. 書き換えを成功させることができるか?
□現行システムを深く理解し、尊重しているか?
既存のコードを完全に理解するよりも、新しいコードを記述するほうがはるかに簡単です。したがって、書き換えを開始する前に、「Classic」システムを深く理解し、尊重しなくてはなりません。それがチームやビジネスが今、ここに存在しうる理由のすべてであり、本番環境での稼働を通じて長年蓄積された知恵がここにあります。考古学者になったつもりで、なぜそのようになっているのかを掘り下げてみましょう。
□エンジニアリングに費やす時間があるか?
システムを一から書き換えるのは大変な作業です。機能を完全に網羅するには多くの時間が必要です。そのためのリソースがありますか?現行システムを理解しているドメインの専門家はいますか?組織はこの規模のプロジェクトを維持するのに十分な「体力」がありますか?
□機能開発のペースが遅くなることを許容できるか?
Sync Engine Classic での機能開発を完全に中断することはありませんでしたが、旧システムの変更のたびに、新システムのゴールはさらに遠くなりました。いくつかのプロジェクトの立ち上げを決定しましたが、書き換えチームを停滞させることなくロールアウトへと導くために、非常に強く意識してリソースを割り当てる必要がありました。Sync Engine Classic に関するテレメトリにも多額の投資を行って、定常状態のメンテナンス コストを最小限に抑えました。
3-3. 方向性を把握できているか?
□なぜ 2 度目のほうが良いのか?
ここまで来れば、旧システムと学ぶべき教訓について十分に理解できているはずです。とはいえ、書き換えは、要件やビジネス ニーズの変化も動機になっているはずです。先ほどファイル同期がどのように変化したかを説明しましたが、書き換えを行うという決断も将来を考慮したものでした。Dropbox は、職場での共同作業ユーザーのニーズが高まっていることを理解しており、これらのユーザー向けに新しい機能を組み込むには、柔軟かつ堅牢な同期エンジンが必要です。
□新しいシステムに対する方針は何か?
一から始めることは、チームにとっての技術文化をリセットする絶好の機会です。Sync Engine Classic の運用経験から、テスト、正確性、デバッグ容易性の 3 点を当初から重視してきました。 これらの方針をすべてデータ モデルに適用します。 これらの方針をプロジェクトの存続期間の早い段階で書き出すことで、何度となく報われたのです。
4. 結果として、構築されたものは何か?
Nucleus で達成したことをまとめてみました。それぞれの詳細については、今後のブログ記事でご紹介します。どうぞお楽しみに!
- Nucleus は Rust で記述しました。Rust は私たちのチームにとって大きな力となっており、Rust に賭けたことは私たちが下した最高の決断の 1 つでした。パフォーマンス以上に、高レベルのエルゴノミクスと正確性が、同期の複雑さを緩和してくれました。システムに関する複雑な不変条件を、型システムでエンコードでき、コンパイラでチェックできました。
- コードはほとんどすべて単一スレッド(「制御スレッド」)で実行され、Rust の futures ライブラリを使用して、この単一スレッドで多数の同時操作をスケジューリングしています。ネットワーク I/O はイベント ループに、ハッシュのような計算量の多い作業はスレッド プールに、ファイル システム I/O は専用スレッドに、といったように、必要に応じて他のスレッドに作業をオフロードしています。これにより、新機能を追加するときに開発者が考慮しなければならない範囲および煩雑さが大幅に削減されます。
- 制御スレッドは、制御スレッドの入力とスケジューリングの決定が修正されたとき、完全に決定となるよう設計されています。この性質を利用して、擬似ランダム シミュレーション テストでファジングします。乱数発生器のシードを使用して、初期ファイル システムの状態、スケジュール、システムの摂動をランダムに生成し、エンジンを最後まで動作させることができます。結果として、何らかの同期の正確性のチェックに失敗した場合は、いつでも元のシードからバグを再現できます。私たちはテスト インフラストラクチャで毎日何百万ものシナリオを実行しています。
- クライアント サーバー プロトコルを再設計することで、強力な一貫性が確保されました。このプロトコルでは、異変が確認される前と同一のリモート ファイル システムのビューが、サーバーとクライアントに存在することが保証されています。共有フォルダおよびファイルにはグローバルに一意の識別子があり、クライアントでそれらが、一時的に重複した状態や欠落した状態で表示されることはありません。最後に、フォルダおよびファイルは、サブツリーのサイズに関係なく、O(1) の ATOMIC_MOVE をサポートしています。これで、クライアントのリモート ファイル システムのビューとサーバーのリモート ファイル システムのビューの間で強力な一貫性チェックが実現しました。矛盾があるとすれば、それはバグです。
コア同期チームでは人材を募集しています。システムでの難問を Rust で解決することにご興味のある方、ご連絡をお待ちしております!