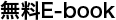DBXi を紹介するブログ投稿で説明したように、Dropbox は、ユーザーが重要な仕事に集中できるようにするための機能を開発しています。必要なコンテンツを膨大な情報の中から探し出すのは煩わしい作業でもあることを考慮し、必要なファイルが必要なタイミングで見つけやすくなるよう、コンテンツの提案機能を開発しました。
この機能には最先端の機械学習(ML)技術が採用されていますが、これは「人はどうやってファイルを探しているのか」という単純な疑問から始まりました。
最も一般的な行動パターンとはどのようなものでしょうか。私たちは、次の 2 つのカテゴリが最も一般的であるという仮説を立てました。
1. 最新ファイル
必要なファイルとは多くの場合、最近使ったファイルです。これはもちろん時と共に変化しますが、「最近の過去」は「近い将来」の良い指標となります。
これには、本人だけでなく他のユーザーが最近編集しファイルも含まれます。
たとえば、同僚がレポートの初稿を書き終えたあと、自分にファイルが共有されて編集できるようになった場合などです。まだファイル自体は開いていなくても、最近共有されたという事実は、すぐにでも編集する可能性があるという有力な手掛かりになります。
2. よく使うファイル
ファイルのもう一つの分類として、「何度も使うファイル」というのもあります。たとえば、個人の To-Do リストや、毎週の定例会議メモ、チーム ディレクトリが考えられます。このカテゴリには前述のカテゴリと重複する部分があり、例えば来週が期限のレポートに集中して作業すれば、そのレポートは頻繁に開くファイルであり、かつ最近アクセスしたファイルともなります。
目次
1. ヒューリスティック法
ユーザーがアクセスするファイルの種類についての基本的な理解に基づき、一連のシンプルなヒューリスティック(前述のような行動を把握するために定義したルール)を用いてシステムを構築しました。
最も効果的だったものは以下の 3 つです。
1. 最近(リーセンシー)
ファイルを新しい順に、つまり最も新しいファイルを最初に表示します。
このような表示はすでに dropbox.com で行われており、改良を加える基準として適しています。
2. 頻度(フリークエンシー)
過去 1 週間に頻繁に使ったファイルは、過去 1 年間に頻繁に使ったファイルとは異なるでしょう。そこで話を単純にするために、中間として 1 か月をとり、過去 1 か月における各ファイルのアクセス回数をカウントし、回数が最も多いファイルを表示します。
3. フレーセンシー
前述の 2 つを組み合わせたものが、フレーセンシーと呼ばれるヒューリスティックです。最近アクティビティがあったファイル、または頻繁にアクセスされたファイル、あるいはその両方に該当するファイルを探し、両方の基準に合致するファイルには、より高いランクを付けます。個々のアクセスがどれぐらい前であるかに基づいて、アクセスに与えられる重み付けを減らします。過去 1 週間に 5 回アクセスしたファイルは、数か月前に 10 回アクセスしたファイルと比べて、近いうちに再び使う可能性が高いと考えられます。
ヒューリスティックの導入と改善
ヒューリスティックを取り入れると、とてもシンプルな実装から開始して、理解可能な行動に基づきユーザーの反応を記録できるようになります。
Dropbox では、これらのシンプルなヒューリスティックを使って、コンテンツのおすすめ機能の初期バージョンを導入することができました。
つまり、設計、フロントエンド コード、バックエンド コード、ユーザーごとの候補ファイルのリストを取得するコード、各ファイルのアクセス時刻に関するメタデータを取得するコードなど、この機能の構築に必要な他の要素に注力することができたのです。
この初期バージョンで重要だったのはログの記録でした。Dropbox では機能ゲーティング システム Stormcrow を用いてごく少数のユーザーに初期テストを実施することが多くあります。機能を一部のユーザーに提供したあと、おすすめのファイルがユーザーにとってどのぐらいの頻度で有効だったかを確認し、次にどうするべきかの判断に役立てることができました。
また、さまざまなバリアント(異なるヒューリスティック)を比較して、相対的なパフォーマンスを確認することもできます。
最初にユーザーにテストを依頼したとき、これらのヒューリスティックには多くの問題があることが判明しました。たとえば、最近使ったファイルは 1 つのみで、それまで長い間他のファイルを使っていない場合もあります。
Dropbox では常に上位 3 個の候補を表示していたため、このような場合でも最新ファイルと一緒に無関係のファイルが表示されてしまい、混乱の元となっていました。しかしこの問題は、ヒューリスティックにしきい値を設け、スコアがしきい値よりも高い場合にのみファイルを表示することで解決しました。
しきい値は、表示された候補のデータセット、各候補のスコア、ユーザーがクリックした候補を参照することで設定できます。さまざまなしきい値をオフラインで設定することによって、適合率(表示された結果のうちクリックされた割合)と再現率(クリックされた結果のうち表示された割合)のバランスをとることができます。Dropbox では、偽陽性を避けるために適合率を上げる必要があったため、しきい値をかなり高く設定しました。ヒューリスティック スコアがこの値より低いファイルは、おすすめとして表示されません。
また別の問題として、ユーザー自身は直接操作していなくても、ユーザーのパソコンにインストールされたプログラム(ウイルス スキャンや一時ファイルなど)がアクセスしているファイルがおすすめに表示されることもありました。
そこで、これらのファイルをおすすめリストから除外するフィルターを作成しました。さらに、当初ヒューリスティックでは予定していなかった、別のユーザー行動も判明しました。特に、定期的にアクセスされるファイルのうち、四半期ごとの報告や毎月の会議文書など、設定したヒューリスティックでは確認できなかったものがありました。
当初は、ヒューリスティックにロジックを追加することでこうした問題に対処できましたが、コードが複雑になり始めたところで、初期バージョンの ML モデル構築に着手することに決めました。機械学習を用いることで、ユーザーの行動パターンから直接学習できるため、増え続けるルール リストを維持する必要がなくなります。
2. 機械学習モデル v1
ML システムの設計方法の 1 つに、予測時点でシステムをどのように動作させたいかを起点に逆算するやり方があります。
私たちは、ごく標準的な予測パイプラインを求めていました。
「コンテンツの提案」システム向けの ML 予測パイプライン
ステップは次の 4 つです。
1. 候補となるファイルの収集
ユーザーごとに、ランクを付ける候補ファイルが複数必要です。Dropbox ユーザーのファイルは数千個から数百万個にもなる可能性があるため、そのすべてにランクを付けるのは非常に高いコストがかかります。しかも、その大半はほとんどアクセスされないため、あまり有効でもありません。代わりに、ユーザーが最近操作したファイルに限定すれば、正確性を大きく損なうことはありません。
2. シグナルの取得
それぞれの候補ファイルについて、関連性の高い未加工のシグナルを取得する必要があります。これには、ファイルの作業履歴(開く、編集、共有など)、作業したユーザー、ファイルの種類やサイズなどのファイル プロパティがあります。
また、ユーザーごとに個別のモデルをトレーニングしなくても結果がさらにカスタマイズされるように、現在のユーザーと「コンテキスト」(現在の時刻、ユーザーが使用しているデバイス種別など)に関するシグナルも含めます。
このモデルは、多数のユーザーのアクティビティによってトレーニングされ、特定のユーザーのアクションを示す(行動を暴露する)バイアスがかからないようにします。初期バージョンでは、アクティビティに基づくシグナル(アクセス履歴など)のみを使用し、コンテンツに基づくシグナル(ドキュメント内のキーワードなど)は使用しませんでした。その利点は、ファイル種別に応じて異なる種類のシグナルを計算する必要がなく、すべてのファイルを等しく扱えることです。将来的には、必要であればコンテンツに基づくシグナルも追加できます。
3. 特徴ベクトルのエンコード
ほとんどの ML アルゴリズムは、浮動小数点数ベクトルなど非常に単純な形式の入力にしか作用しないため、未加工のシグナルを、いわゆる特徴ベクトルと呼ばれるものにエンコードします。さまざまな種類の入力について標準的なエンコードの方法があり、必要に応じて修正しました。
4. スコアリング
これでようやく実際のランク付けの準備が整います。各ファイルの特徴ベクトルをランク付けアルゴリズムに渡し、ファイルごとのスコアを受け取って、そのスコアで並べ替えます。上位ランクの結果については、ユーザーに表示する前にもう一度権限のチェックが行われます。
もちろん、ユーザーはページが読み込まれるのを待っているので、このすべての処理が各ユーザーとそのファイルについて一瞬で行われなければなりません。
Dropbox では、このパイプラインのさまざまな部分を最適化するのに多くの時間を費やしました。幸い、これらのステップが個々の候補ファイルとは独立して実行可能であることを活用してプロセス全体を並列処理できたのに加え、最新ファイルとそのシグナルのリストを取得する(ステップ 1 と 2)ための高速なデータベースもすでにありました。このため、ステップ 3 と 4 を大幅に最適化しなくても、遅延を許容範囲内に収めるのに十分であることがわかりました。
モデルのトレーニング
システムが本番環境でどのように実行されるのかが明確になった次は、このモデルをどのようにトレーニングするのかを考える必要があります。
当初は、この問題を二項分類ととらえていました。つまり、特定のファイルを今すぐ開く(陽性)または開かない(陰性)のどちらかに決定すると考えました。このイベントの予測確率は、結果にランク付けするためのスコアとして使用できます。トレーニング パイプラインに関する一般的な指針は、トレーニング シナリオをできるだけ予測シナリオに近づけることです。このようにして、予測パイプラインと厳密に一致するように、以下の 4 つのステップを決定しました。
1. 候補となるファイルの取得
システム全体への入力として、このステップを適切に進めることが最終的な正確性に不可欠です。一見すると単純そうであるにもかかわらず、多くの理由で最も困難な作業の 1 つでした。
1-1. 陽性の例をどこから得るか
ファイル オープン履歴のリストはログから取得できます。
しかし、ファイル オープンのうちのどれを、陽性の例としてカウントするべきでしょうか。ヒューリスティック法を用いたバージョンの機能で得られたデータなのか、または Dropbox の一般的なファイル オープンのデータなのか。前者のデータは、より関連性の高い候補といえます。なぜなら、ユーザーがそのファイルを開いたのは、私たちがこのモデルを展開しようとするコンテキストそのものであるからです。
しかし、1 つのコンテキストからのデータのみを使用してトレーニングしたモデルは、より広いコンテキストで使われたときに、視野の狭さが問題になる可能性があります。それに対し、より一般的なファイル履歴は、あらゆる種類のユーザーの行動を反映する度合いが高い一方で、含まれるノイズも多くなります。ログのほうが処理が簡単であることから、当初は前者の方法を使用していましたが、トレーニング パイプラインを導入してからは、両方を組み合わせた結果がはるかに良好であったため、(後者への重み付けを大きくしたうえで)切り替えました。
1-2. 陰性の例をどこから得るか
理論上は、ユーザーの Dropbox にあるファイルのうち、開かれなかったものはすべて陰性です。しかし、指針(トレーニング シナリオをできるだけ予測シナリオに近づける)を念頭に置き、陽性のファイル オープン時点での最新ファイルのリストが、予測時点で表示されるものに最も類似していることから、これを陰性の可能性があるセットとして使用しています。陰性のリストは陽性のリストよりもはるかに大きくなり、ML システムで良好な結果が得られないことが多いため、陽性の数倍ほどの陰性をサブサンプリングしています。
2. シグナルの取得
これは予測シナリオの場合と同様ですが、個々のトレーニング例の時点で現れるシグナルが必要なため履歴データへのアクセスが必要になる点が異なります。
これを簡単にするために履歴データを扱える Spark クラスターを用意しました。たとえば、シグナルの 1 つに「最新ランク」がありますが、これは最終アクセス時刻で並べ替えた、最近開いたファイルのリストにおけるファイルのランクです。履歴データの場合、これは、正しいランクを計算できるように特定時点のこのリストの表示を再構成することを意味します。
3. 特徴のエンコード
ここでも、本番環境とまったく同じ状態を維持します。反復的なトレーニング プロセスの中で、データのエンコードをとてもシンプルな形から始めて、必要に応じてさらに高度なものにしました。
4. トレーニング
ここでの大きな決定事項は、どの ML アルゴリズムを使用するかでした。
まず非常にシンプルな選択から始めました。線形サポート ベクトル マシン(SVM)です。これには、トレーニングが極めて素早く、成熟かつ最適化された、わかりやすい実装例が数多くあるという利点があります。
このプロセスの出力は、トレーニング済みモデルであり、特徴次元ごとの重み係数を含むベクトル(float 型)です。このプロジェクトの間、私たちは多数の異なるモデルをテストしました。これらのモデルは、異なる入力データ、異なるシグナルのセット、多様なエンコード方法、異なる分類器トレーニング パラメーターを使用してトレーニングしたものです。
この初期バージョンでは、すべてのユーザーに対して 1 つのグローバルな分類器をトレーニングしました。線形分類器を使うことで、ファイル使用の最新度合いや頻度といった一般的な行動をとらえるのに十分な性能が得られますが、個別ユーザーの好みに適応する能力はありません。後ほど、この ML システムの、精度が向上するであろう次の主要なイテレーションについて説明します。
3. 測定基準とイテレーション
トレーニングと予測のパイプラインに関するステップを完了したあとは、最善のシステムをユーザーに提供する方法を考える必要があります。
しかし、「最善」とは実際には何を意味するのでしょうか。Dropbox での ML の取り組みは、製品主導型です。何よりもユーザーにとっての製品の操作性を高めることが主目的であり、私たちが構築する ML はその目的に沿うものです。
つまり、私たちがシステムの改善について話すときは、最終的にユーザーにとってのメリットを測定できることが望ましいのです。
私たちはまず、製品の測定基準を定義することから始めました。コンテンツの提案機能の場合、第一の目標はエンゲージメントです。これを追跡するために複数の測定基準を使い、まずシンプルな形で始めることにしました。提案機能が有用なら、ユーザーがクリックする回数が増えると予想します。
これは、ユーザーが候補をクリックした回数を、ユーザーに候補が表示された回数で割ることで簡単に測定できます。これはクリック率(CTR)とも呼ばれます。統計的に有意となるよう、一部のユーザーに対し、1~2 週間にわたって異なるモデルによる候補を表示してから、異なるバリアントの CTR を比較します。
理論上は、数週間ごとにモデルをローンチし、長期にわたってゆるやかにエンゲージメントを改善できるはずです。
実際には、2~3 の大きな問題(そしていくつかの小さな問題)が発生しました。まず、CTR の上昇(または下降)が、製品設計の変更によるものか、ML モデルの変更によるものかを判断する方法です。大規模な調査と業界のケーススタディによれば、ユーザー エクスペリエンス(UX)に対する、ごくわずかと思われる変更でも、ユーザーの行動に大きな変化を引き起こす可能性があります(A/B テストが広く行われているのはそのためです)。エンジニア チームが ML モデルの改善に取り組むと同時に、エンジニア、設計者、プロダクト マネージャーで構成される別のチームが機能の設計改善に取り組みます。このような設計のイテレーションに関する概要レベルの例を図で示します。
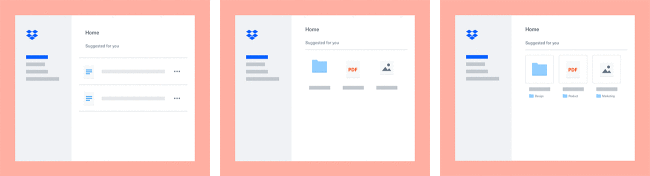
新バージョンで UX と ML モデルの両方を変更する場合、どの変更が CTR に影響したのか(そしてどの程度影響したのか)、どうしたらわかるでしょうか。
実際には、この問題への対応は当初考えていた以上に複雑でした。私たちは早い段階で、かなりのケースで正しいファイルが候補としてユーザーに表示されることを把握していましたが、ユーザーは候補セクションからファイルをクリックするのではなく、他の方法でファイルを選択して開いていました。考えられる理由はたくさんあります。従来の方法でファイルにアクセスするほうが慣れている、重要なコンテキスト情報(親フォルダ名など、後に設計のイテレーションの一環で追加)が欠けている、などです。最終的な結果として、モデルの正確性を測定する方法として CTR 数のみには頼れないということになりました。より直接的にモデルの正確性をとらえることができ、できるだけ UX から独立したような測定基準を見つける必要がありました。
こうした代わりの測定基準に切り替えることには、他にもやむを得ない理由がありました。イテレーションのスピードです。A/B テストの実施に 2~3 週間かけるのはそれほど長いように感じませんが、それは個々のテストを完全に実施するのに必要な時間でしかありません。その後で結果の分析、改善案のリスト作成と実装、そして最後に新しいモデルのトレーニングを行う必要があります。つまり、新バージョンのリリースには 1 か月以上はかかるということになります。大きく前進するには、この時間を大幅に短縮する必要があり、さらに言えば、ユーザーにリリースせずに「オフライン」で測定できる基準が理想的でした。
ヒット率
トレーニング プロセスでは、提供されたトレーニング データのセットに対して、(前述した)適合率と再現率、または分類器の正解率など、さまざまな数量を測定しましたが、これらの測定基準と CTR の間に強い相関は見られませんでした。その代わりとして、私たちの基準をすべて満たす「ヒット率」という測定基準を使うことにしました。提案されたあらゆるファイルについて、ユーザーがどのようにそのファイルにアクセスしたかに関係なく、その後 1 時間以内にそのファイルにアクセスしたかどうかをチェックしました。アクセスした場合は、それを「ヒット」としてカウントします。さらに、候補ごとのヒット率(ヒットとなった候補のパーセンテージ)と、セッションごとのヒット率(少なくとも 1 つの候補がヒットとなったセッションのパーセンテージ)の両方を計算します。これをオンラインと、(ユーザーの行動の履歴ログを参照することにより)オフラインの両方で測定します。
この測定基準は、より迅速な ML のイテレーションのためだけでなく、UX の問題を診断するためにも、非常に有用であることがわかりました。たとえば、当初は「コンテンツのおすすめ」の表示形式をファイルのリストから一連のサムネイルに移行したとき、CTR が上がると予想していました。ファイルを表示するのに縦方向のスペースが少なくて済むだけでなく、サムネイルを表示することでユーザーがファイルを識別しやすくなります。しかし実際には CTR は下がりました。いくつかの異なる設計のイテレーションを試し、ヒット率の測定基準を使って、候補の質が原因ではないことを突き止めました。前述したように、フォルダ名が不足しているなど、多くの修正点が見つかったのです。
本番の測定基準と代わりの測定基準を使ってモデルの正解率を測定することでシステムの観点から UX と ML の両方の改善を迅速に進められるようになりました。ただし、すべての改善が、これらの測定基準を参考にして加えられたわけではありません。測定基準を広く浅いパフォーマンス測定と考えているのであれば、補完的な情報源として、深く狭い測定に目を向けるのも有用です。これは、この場合、自分自身のチーム メンバーを対象とした非常に少量のデータについて、候補を詳しく調べることを意味します。
詳細な内部テストによって、使用するべきデータなど、パイプラインのまさに初めの部分に影響するその他多くの問題が明らかになりました。興味深い例をいくつか示します。
ショート クリック
私たちが使用したトレーニング データには、ユーザーがフォルダ内のファイルを開いてから、そのあと左矢印キーと右矢印キーを使ってそのフォルダ内の別のファイル間をスクロールした例が含まれていました。一度に数枚の画像のみ表示されるホーム ページ上では、このような行動は当てはまらないにもかかわらず、これらはすべて、結局は陽性のトレーニング サンプルとしてカウントされます。このため、これらのショート クリックにラベルを付ける方法を考案し、トレーニング データから除外しました。
直近のファイル アクティビティ
よく使われる Dropbox の機能の 1 つに、Dropbox へのスクリーンショットの自動保存があります。ホーム ページにアクセスするユーザーは、スクリーンショットがすぐに表示されることを期待しますが、私たちの機能パイプラインには、それだけの即応性がありませんでした。さまざまなコンポーネントの遅延を調整することでこれらのスクリーンショットも結果に含めることができるようになりました。
新規作成されたフォルダ
同じように、ユーザーはファイルを移動させるためにフォルダを新規作成することが多いため、そのフォルダがホーム ページに表示されることを期待します。この場合、フォルダについて得られるこの種のシグナルは、はるかに限定的であり、ファイルとは異なっているため、ヒューリスティックを一時的に使用し、そのようなフォルダを検出して候補に加える必要がありました。
4. 機械学習モデル v2
現行システムで整備されていない部分についての新たな知識も得て、トレーニング パイプライン全体に対する大幅な改善に着手しました。ショート クリックの他にユーザーに誤って候補として表示されるファイルのクラスもトレーニング データから除外したのに加え、ヒット率の測定基準に影響する可能性がある他の種類のシグナルをトレーニング プロセスに統合するようにしました。また、未加工のシグナルから関連性の高い情報を効率的に取り出せるように、特徴のエンコードのステップを手直ししました。
コンテンツの提案機能の改善にとって、Dropbox が ML に投資する別の大きな分野が非常に重要であることが明らかになりました。一般的なタイプのエンティティについての埋め込みの学習です。
埋め込みは、個々の Dropbox ユーザーやファイルのような、オブジェクトの離散集合をコンパクトな浮動小数点数ベクトルとして表現する方法です。これらは高次元空間のベクトルとして扱われ、コサインやユークリッド距離のような一般的に使用される距離尺度で、オブジェクトの意味的類似性がとらえられます。たとえば、類似する行動をとるユーザーや、類似するアクティビティ パターンを持つファイルに関する埋め込みは、埋め込み空間での距離が近いことが予測されます。これらの埋め込みは、Dropbox で入手できるさまざまなシグナルから学習でき、任意の ML システムに入力として適用されます。コンテンツのおすすめ機能については、これらの埋め込みによって正解率が顕著に上昇します。
最後に、分類器をニューラル ネットワークにアップグレードしました。Dropbox のネットワークは現在はそれほどディープではありませんが、入力特徴の組み合わせに対して非線形で作用できるだけでも、線形分類器と比べて大きな優位性があります。たとえば、特定のユーザーが午前中にスマートフォンで PDF ファイルを開き、午後にはデスクトップで PowerPoint ファイルを開く傾向がある場合、線形モデルでそれをとらえることは(広範な特徴の組み合わせまたは拡大なしでは)困難ですが、ニューラル ネットワークでは容易に拾い上げることができます。
トレーニングの問題をどのようにとらえるかも、若干変更しました。二項分類に代わって、ランク学習(LTR)の定式に切り替えました。Dropbox での問題のシナリオには、このクラスのメソッドが、より適しています。LTR は、他の予測とはまったく関係なく、ファイルがクリックされるかどうかに応じて最適化するのではなく、クリックされたファイルをクリックされなかったファイルよりも高くランク付けするように最適化します。これには、最終結果を改善する形で出力スコアを再配分する効果があります。
これらの改善により、ヒット率を大幅に向上させ、総合的な CTR を改善すると共に、将来的にさらに改善するための基礎作りもできました。
謝辞
このプロジェクトは、プロダクト、インフラストラクチャ、機械学習の各チーム間で多くの共同作業が必要となる、チームをまたぐ取り組みでした。個別に名前を挙げるにはあまりに多くの人が関わっていますが、システムの大部分を構築(またパイプラインの多くの部分を改善)したイアン・ベイカー、ML のイテレーション作業の大部分を主導したエルモ・ウェイを、特に称えます。
すべてのチームで人材を募集していますので、こうした課題に関心があればぜひご応募ください。