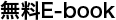
以前の記事で、世界中のユーザーのパフォーマンス向上を目指して当社が導入したグローバル境界ネットワークの概要をご説明しました。この境界ネットワークは、Magic Pocket のメリットを実現する戦略の一環として、2 年がかりで構築したものです。
境界ネットワークと平行して立ち上げたのが、北米の複数のデータ センター同士だけでなく、世界中の境界ノードを結ぶグローバル基幹ネットワークです。この記事では、まずこの基幹ネットワークを構築した経緯を振り返り、次に Dropbox とユーザーの皆様が得られるメリットについてご紹介します。
Dropbox の基幹ネットワーク
この 3 年間で、当社のネットワークはユーザーの増加に合わせて大きく進化しました。Magic Pocket に移行する前まで、当社は早い段階でクラウド テクノロジーを導入し、ストレージとインフラストラクチャのすべてのニーズをまかなっていました。しかし、数百ペタバイトのユーザー データを自社のデータ センターに移行しつつ、増え続けるユーザーにも対応しなければならないという状況では、ネットワークを大幅かつ迅速に拡張する必要に迫られました。
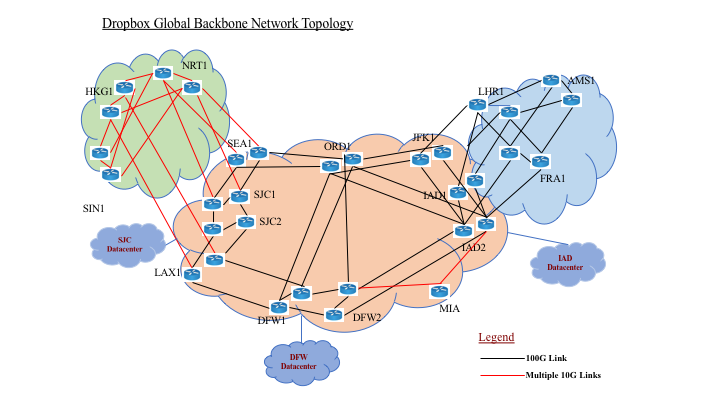
2015 年:新技術の計画と実装の年
2015 年の初めに私たちは、データ収容量を 10 倍にし、99.999% という高い信頼性を実現し、ユーザーのパフォーマンス向上を目指すネットワーク拡張イニシアチブを開始しました。社内の予測で、ユーザー数が増え続け、ネットワーク トラフィックが爆発的に拡大することが指摘されていたからです。ネットワークの拡張計画と同時に、Quality of Service(QoS)、Multi-Protocol Label Switch(MPLS)、IPv6 などの技術の導入にも目を向け、将来の成長を支えるためのルーティング アーキテクチャの見直しについての検討も始まりました。
ルーティング アーキテクチャ
当時のルーティング アーキテクチャは、Interior Gateway Protocol(IGP)として主に Open Shortest Path First(OSPF)を使用し、Interior Border Gateway Protocol(iBGP)設計にはルート リフレクタ(RR)を使用していました。10 倍の拡張と新技術の導入を計画しながら、IGP と BGP 設計の両方で、ルーティング アーキテクチャを再評価しました。
IGP の移行
OSPF の使用を継続する上で特に困難だったのが、IPv6 の導入が複雑だという点でした。当社が元々使用していたのは、IPv4 のみをサポートする OSPFv2 でした。アップグレード後の IPv6 では OSPFv3 が必要です。当時、OSPFv3 の複数のアドレス ファミリーを完全にサポートするベンダーは一部にとどまり、導入も限定的でした。つまり、v4 と v6 をサポートするには 2 つのバージョンの OSPF を実行する必要があり、運用がさらに複雑になるのです。
そこで、OSPF を廃止して IS-IS に乗り換えることを検討し始めました。IS-IS は、OSI のレイヤ 2 で実行されるプロトコル不問のアーキテクチャであり、v4 と v6 を含むすべてのアドレス タイプを簡単にサポートできました。また、IS-IS は Type Length Value(TLV)を使用して情報をリンク状態パケットで運びます。TLV は、さまざまな種類の情報を伝送したり、将来的に新しいプロトコルもサポートできるよう、IS-IS を容易に拡張可能にします。2015 年の第 2 四半期には、基幹ネットワーク全体で OSPF から IS-IS への移行が完了しました。
iBGP 設計
初期の iBGP 設計は、単一階層ルート リフレクタ(RR)モデルをベースとしていました。しかし、iBGP の RR には、パス ダイバーシティが限られているなどの制限事項があります。RR はクライアントからルートを学習すると、単独の最適なパスをピアに対してアドバタイズします。つまり、RR のピアはすべてのプリフィックスでパスが 1 つしか見えなくなるのです。結果、そのプリフィックスのトラフィックは、等コストの複数のネクストホップ全体に分散されず、すべてが 1 つのネクストホップに送信されてしまう可能性があります。
これにより、ネットワーク全体のトラフィックのロードバランシングが不均衡になります。この問題を緩和するため、複数のパスをアナウンスする機能を持つ Add-Path を使用しました。Add-Path はルーティング ベンダーが開発した当時まだ出始めたばかりの製品であったため、テスト時にはいくつものバグが発生しました。その時点で、新しい iBGP 設計を採用し、ルート リフレクタから手を引く決断を下しました。私たちは以下の設計のどれを選択するか、議論を重ねました。
1. すべてのルーターでフル メッシュ iBGP 設計
このシナリオでは、すべてのルーターが互いにフル メッシュの iBGP を持つことになります。この設計では、フル メッシュ iBGP の全ルーターがお互いからのすべてのルートを学習するため、RR で発生していたパス ダイバーシティの欠如という問題が解消されます。これはルーターの数が少ない小規模ネットワークではうまく機能しますが、ネットワークが拡大すれば、ルーターや学習するルートの数は膨大になると考えられました。コントロール プレーンに何百万ものルートがあると、メモリの問題が予想され、ルート チャーン(経路のばたつき)が併発すれば CPU や RIB/FIB のメモリにも問題が及び、動作に深刻な影響を与えるおそれがあります。
2. リージョン内ではフル メッシュ iBGP、リージョン間ではルート リフレクタを使用
2 番目のアプローチでは、基幹ネットワークを小さなリージョンに細分化し、リージョン内ではルーター間にフル メッシュ iBGP を置き、リージョン間では RR アナウンス ルートを置きます。このアプローチでは、フル メッシュ iBGP のルーター数がはるかに少なくなるので、ルート拡張の問題は解決されます。しかしこの設計でも、先述の RR の制限事項は解決できません。
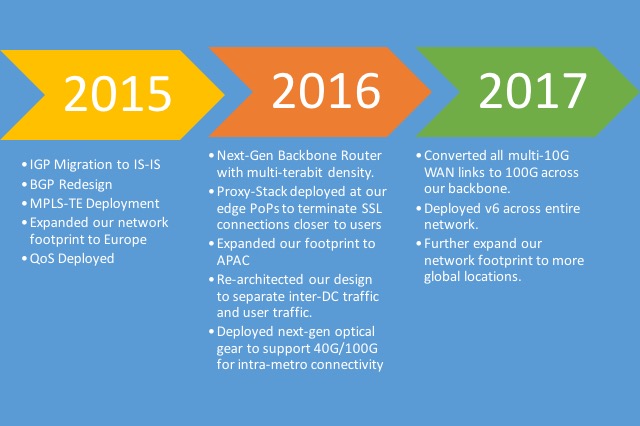
私たちが最終的に選んだのは、この 2 つのハイブリッド アプローチ、つまり、リージョン全体で選択的ルートをアナウンスするフル メッシュ iBGP でした。こうして、ルーター全体でフル メッシュ iBGP を置くだけでなく、基幹ネットワークを異なるルーティング ポリシーを持つ小さなリージョンに分割することになりました。Dropbox のトラフィックの大半は、トランジット プロバイダ ルートが占めるため、トランジット プロバイダからのルートを、それらが発生したリージョンに限定しました。その他のピアリング ルートと内部トラフィックはすべてリージョン全体でアナウンスされます。このアプローチでは RR の制限事項が解消され、フル メッシュ iBGP によるルート拡張問題も解決できます。
米国ネットワークのリージョンへの分割を示すスナップショット。また、欧州とアジア太平洋をそれぞれ個別のリージョンとして扱うため、リージョンは合計 5 つとなります。
MPLS-TE
2015 年の初頭に、MPLS-TE の導入を開始しました。お客様に期待以上のサービスを届けるためには、障害に対応し、需要の急増にも迅速に応えられるネットワークが必要です。ダイナミックに変化する帯域幅の容量と需要に適応させるという課題に対処するため、RSVP を使用する MPLS を実装しました。
MPLS RSVP-TE には、手動介入なしで、トラフィックの突然の急増に対応して調節するしくみがあります。利用可能な帯域幅が十分にある場合、MPLS は、送信元と宛先の間の 2 点間に Label Switch Path(LSP)を確立することで、トラフィックがネットワーク上の最短パスを通るようにします。当社はさまざまな優先順位を持つ複数の LSP を導入しました。ここでは、ユーザー トラフィックは常に優先順位が高い LSP を持ち、内部トラフィックの LSP は優先順位が低くなります。
トラフィックの需要が高まる(または停電が原因でネットワーク容量が低下する)と、RSVP-TE は LSP を、その需要に対処できる十分な帯域幅がある、より大きなメトリック値を持つ別のパスに移動させます。優先順位の異なる複数の LSP を導入しているので、RSVP-TE は下図に示すようにユーザー トラフィックを最短ルートに残したまま、重要性の低い内部トラフィックから先に長いパスに変更できます。これによりネットワーク リソースを有効利用できるだけでなく、ネットワークが冗長化して、オーバー プロビジョニングを避けつつ必要なレベルのサービスを確保することができるのです。
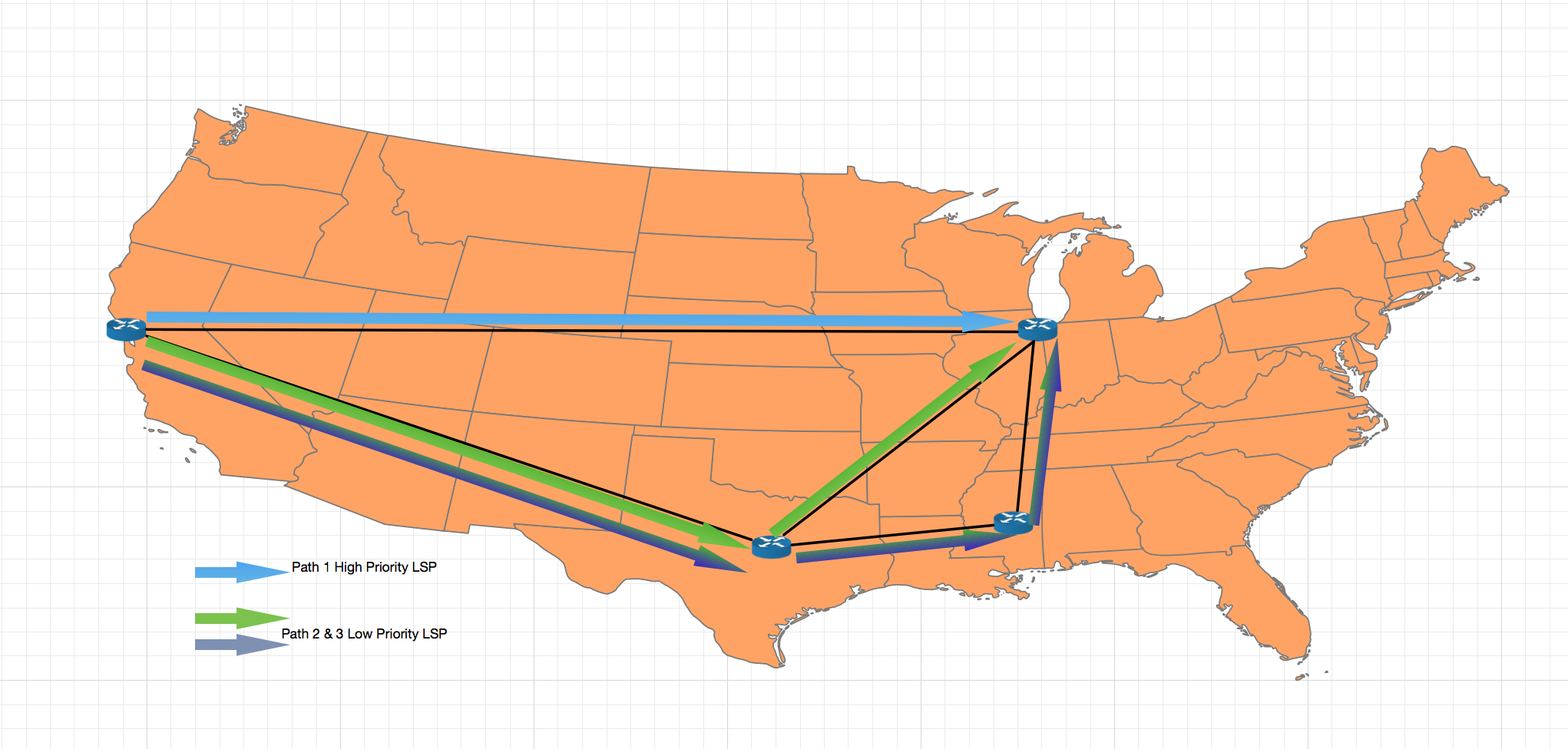
この図は、帯域幅の可用性に応じて LSP が Dropbox 基幹ネットワークを通るパスを示します。
Quality of Service
Quality of Service(QoS)は、重要なアプリケーションのために高いパフォーマンスを確保するための業界標準の規格およびメカニズムです。Dropbox のネットワークでは、遅延に敏感なユーザー トラフィックと、大量のバッチ トラフィック(データの移行とサーバー プロビジョニングによるトラフィックを含む)が混在しています。2015 年に、さまざまなトラフィックの種類を特定し、エンドツーエンドでその種類に応じた適切な対応を行うため、Quality of Service(QoS)プログラムを立ち上げました。QoS により、ネットワーク帯域幅、遅延、ジッター、パケット損失を管理するために必要な技術が得られ、輻輳が発生している間でも重要なアプリケーションにネットワーク リソースを確実に割けるようになりました。
このプログラムを構築するため、当社は Dropbox 内のさまざまなアプリケーション オーナーと連携し、それぞれのサービスの優先順位に基づいて、ホスト マシン上でそのサービスをマークしました。下に示すように、Dropbox のトラフィックすべてを 4 つのカテゴリに分類し、各カテゴリを対応するキューに割り当てました。
1. Network_Control:
すべてのルーティング プロトコルの Hello メッセージやキープアライブ メッセージがこのキューに入ります。この種のパケットが失われるとネットワークの適切な運用に悪影響が出るため、これらのメッセージは最優先となります。
2. Premium:
エンド ユーザーに関連するすべてのトラフィックです。プレミアム キューに入るパケットは、Dropbox ユーザーにとって重要であると見なされ、高優先順位として扱われます。
3. Default:
ユーザーに影響を及ぼすことはないが、内部サービスが互いに通信するために重要であるトラフィックです。
4. Best_Effort:
重要でないトラフィックです。通常、これらのパケットはネットワークが輻輳したときに最初にドロップされるものであり、後で再送信できます。
いつでも全種類のトラフィックをサポートできる十分な帯域幅を確保していますが、予期せず発生するネットワーク障害から重要なサービスを保護しなければなりません。そのために、低優先度のトラフィックを後回しにして、Premium(ユーザー)トラフィックを優先する QoS が役立っています。
2016 年:10 倍の拡張をサポートするための実行の年
2016 年は、ネットワークを再設計し、将来の拡張可能性を支える新しいハードウェアを導入した年でした。
ルーターのタイプ
Dropbox の基幹ネットワークは、以下に示す 3 つの異なる役割を持つルーターで構成されています。
- データ センターのルーター(DR)。データ センターを基幹ネットワークに接続することが主な機能です。
- 基幹ルーター(BB)。長距離回路の終端点として、また、データ センターが配備された地域の DR 用のアグリゲーション デバイスとしても機能します。
- ピアリング ルーター(PR)。Dropbox を外部 BGP ピアに接続し、インターネットへ接続することが主な機能です。
Dropbox のネットワークには以下に示す 2 種類のトラフィックがあります。「ユーザー トラフィック」は、Dropbox と開かれたインターネットの間を流れ、「データ センター トラフィック」は Dropbox のデータ センター間を流れるトラフィックです。以前のアーキテクチャでは、ネットワーク レイヤが 1 つで、両方のトラフィック タイプが同じアーキテクチャを使用して同じデバイスを通過していました。
以前のアーキテクチャ
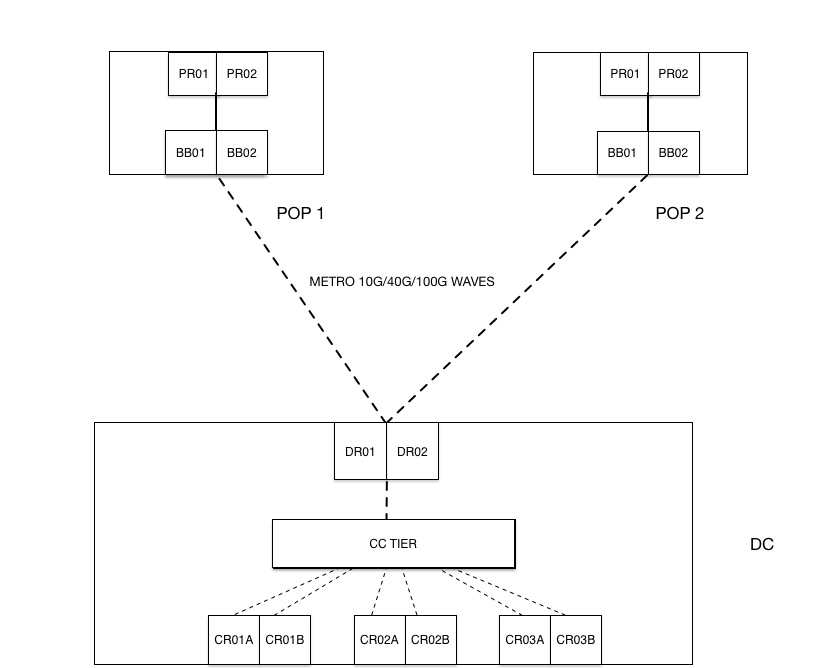
以前の基幹アーキテクチャ
最初は、3 つの役割すべてに同じハードウェア デバイスを使用していました。しかし、事業が大きく拡大し始めるとともに、既存の設計とプラットフォームはその限界に達しました。水平方向に拡張することで同じパスを使用し続けることもできましたが、費用がかさみ、運用が複雑になると考えられました。その代わりにアーキテクチャを見直すことを決定し、これが新しい 2 層アーキテクチャの発展につながりました。
2 層アーキテクチャ:
新しいアーキテクチャでは、ネットワーク ドメインを 2 つ作成し、それぞれがトラフィックを独立して処理するようにしました。また、データ センターに接続するため、DC という新しいルーターを導入しました。新しいデータ センター(DC)層の間にはフル メッシュ MPLS(RSVP)LSP が置かれ、数テラビットの容量まで簡単に拡張できる新しい高密度基幹ルーターがその基盤となりました。以前の DR 層は、主に Dropbox からインターネットへのユーザー トラフィックを伝送するために使用されていましたが、新しい DC 層はデータ センターのトラフィックを運びます。各層には独自の BGP および MPLS LSP メッシュがありますが、それらは同じ基幹(BB)ルーターに接続し、同じ物理的な伝送網を共有します。
当社のデータ センター トラフィックの量はユーザー トラフィックの約 2 倍であり、どちらのトラフィック プロファイルにも異なる特性があります。データ センターのトラフィックの内訳は、データ センター間でのやり取りやデータ コピーを行う内部サービスです。ユーザー トラフィックは必ず DR からポイント オブ プレゼンスに伝送され、プレミアム トラフィックとして扱われます。Dropbox の内部トラフィックを独立した層として分けることで、2 種類のトラフィックを明確に分離することができました。おかげで、トラフィック プロファイルの設定と各タイプに固有のネットワーク トポロジー構築をスムーズに行うことができました。
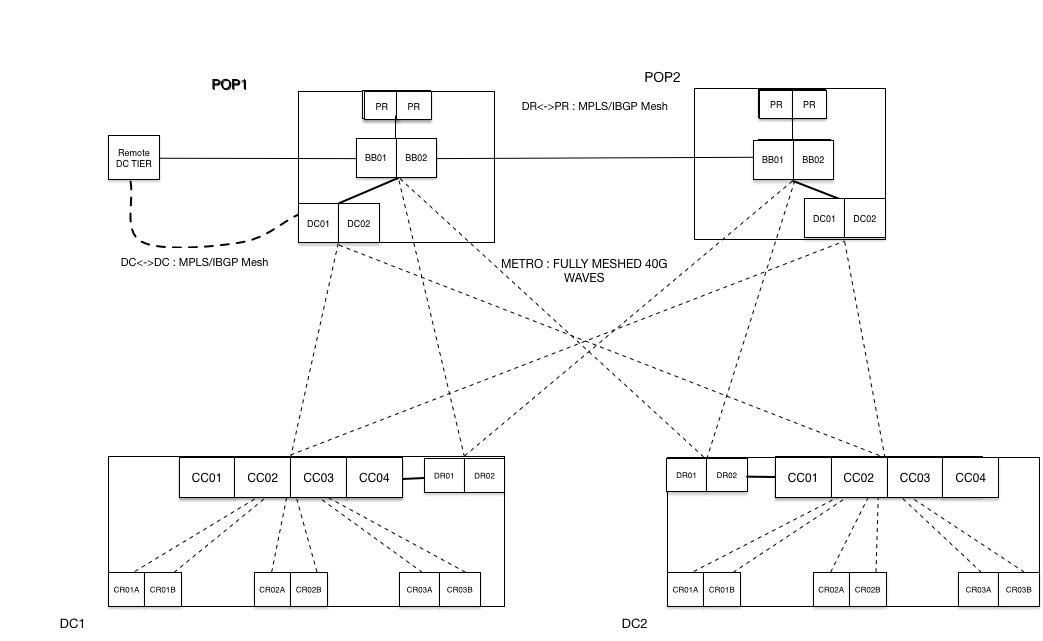
新しい基幹アーキテクチャ
光学系:
飛躍的な成長をサポートし、一貫した SLA を維持するため、私たちはデータ センターを PoP に接続するダーク ファイバーに投資しました。ダーク ファイバーをリースして当社独自の光学系を運用することで、光伝送ベンダーから帯域幅や専用線の容量を購入する場合と比べて、より速いペースで柔軟に容量を追加できるようになりました。これを足がかりに、最新の光学機器を導入し、すばやく簡単に拡張ができるようになりました。
2017 年:将来の成長に備える
100G への移行:
2016 年に、テラビット規模のスループット能力をサポートする拡張性と密度を備えた、最先端のテクノロジーを搭載した次世代の基幹(BB)ルーターの認定を開始しました。8 か月かけてさまざまなベンダーの製品を評価し、最終的に、要件をサポートできる最新技術を備えた製品を使うことに決めました。Dropbox は、本番環境インフラストラクチャでこのプラットフォームを評価し導入した数少ない企業となりました。
基幹ネットワークへの最初の導入では、10G 回路を使用しました。ネットワーク上のトラフィックが増えるにつれ、容量を増やすために 10G リンクを追加し続け、最終的にはこれらの 10G リンクを単独のリンク アグリゲーション バンドル(LAG)に連結しました。2016 年の初めまでには複数の LAG バンドルができ、それぞれに 10 個以上の 10G リンクがあったため、回路のプロビジョニング、管理、トラブルシューティングがより複雑になりました。そこで、複数の 10G 回路を 100G に置き換えることで、アーキテクチャをシンプルにすることにしました。
ネットワーク全体に新しい BB ルーターを展開することで、複数の 10G LAG バンドルからの WAN リンクを 100G に移行することができました。2017 年 6 月までに、大西洋横断リンクを含む米国および EU のすべての WAN リンクをすべて 100G に移行させました。これにより、WAN の累計容量は約 300% 増加しました。
IPv6
2016 年の第 4 四半期には、ネットワーク全体で IPv6 の導入を開始しました。設計目標の 1 つは、ルーティングとフォワーディングの両方で、IPv4 と IPv6 の間にパリティを持たせることでした。この導入の一環として、さらに v4 と v6 の両方で一貫したルーティングを実現するため、マルチトポロジーではなく、IS-IS シングルトポロジーを選択しました。v6 トラフィックのフォワーディングでは、v4 トラフィックのトンネリングに使用したものと同じ MPLS-TE LSP セットを使用することを意図していました。これは、rfc3906 で定義されている IGP ショートカットを使用することで実現できました。IGP ショートカットの実装により、v6 と v4 の両方のトラフィックが、基幹ネットワーク全体で同じ MPLS-LSP を使用するようになりました。2017 年第 1 四半期の末までには、データ センター、基幹ネットワーク、境界ネットワーク全体で v6 の導入が完了しました。
まとめ
Dropbox は、数百ギガビットのトラフィックを管理し、現在も速いペースで成長を続けています。この勢いに後れを取らないよう、Dropbox のネットワーク エンジニアリング チームが提唱しているのが、常に「拡張性をもたせる」ことです。拡張性をもたせるとは、ネットワーク容量、ノード、デバイスを追加することではありません。アーキテクチャを定期的に刷新し、現在の運用の 10 倍の規模にネットワークを成長させて運用する方法について常に考えることです。
このような考え方をすることで、常に 2 ~ 3 年先を読んで計画することになり、現在の運用の 10 倍の容量での運用をサポートするすべてのツール、自動化、監視機能を配備できます。データ センター、基幹ネットワーク、境界ネットワークを問わず、同じ原則がネットワーク全体に適用されます。