先日ご紹介した「Dropbox の新しい検索エンジン Nautilus のアーキテクチャ」では、Droppbox のエンジニアが取り組んでいる、データ検索と機械学習を使った大規模プロジェクト「Nautilusプロジェクト」をご紹介しました。今回は新しい検索エンジンのパフォーマンスと信頼性について掘り下げて紹介いたします。
目次
- インデックス フォーマット
- サービング
- 信頼性
- パーティションの割り当て
- 復元
- シンプルに 1 つのグループから次のグループへと展開していくことで、可用性に影響を与えることなく、新しいコードを本番環境に導入できます。
- グループ全体の追加や削除ができます。これは特に、ハードウェアや OS のアップグレード時に便利です。たとえば、新しいハードウェア上で実行しているグループを追加し、完全に使用できる状態になったら、古いハードウェア上で実行しているグループを廃止できます。
- パーティションに関連するインデックス データを、インデックス レポジトリからダウンロードします。これによって、オフライン ビルド システムから生成されて時間が経っているために古くなっているインデックスをリーフに提供します。
- Kafka キューの古いミューテーションを、インデックス パーティションがビルドされた時に対応するオフセットから再現します。
- ダウンロードしたインデックスに加えて古いミューテーションの適用が終了すると、リーフ インデックスが更新されたことになります。この時点でリーフは供給モードになり、クエリの処理を開始します。
1. インデックス フォーマット
数百もの検索リーフは、それぞれに検索エンジンを実行します。検索エンジンは、ファイルの作成時、編集時、削除時にインデックスの更新(「書き込み」)と、検索クエリ(「読み取り」)を実行します。Dropbox のトラフィックは、書き込みが多数を占めるという興味深い特性を持っています。ファイルが検索される頻度よりも、更新される頻度の方がはるかに高いのです。通常、書き込みは読み取りの 10 倍のボリュームがあります。そのため、検索エンジンで使用されるデータ ストラクチャを最適化する際に、このワークロードを慎重に検討しました。
「ポスティング リスト」とは、トークン(想定される検索語句)を、そのトークンを含むドキュメントのリストにマッピングするデータ ストラクチャです。根本的には、検索エンジンの主要な役割は、転置インデックスから構成されるポスティング リストを維持することです。ポスティング リストは、検索がリクエストされるとクエリが実行され、更新内容がインデックスに適用されるタイミングで更新されます。一般的なポスティング リストでは、トークンとそれに関連するドキュメントの ID に加えて、スコアリングの段階で使用されるメタデータ(例:語句の頻度)を格納するフォーマットになっています。
従来のポスティング リスト フォーマット
このフォーマットは読み取りのみのワークロードには最適です。各検索クエリは、適切なポスティング リスト(ハッシュ テーブルを使った O(1)でもよい)を探し、関連するドキュメント ID を結果セットに追加することのみを必要とするためです。
しかし Dropbox ユーザーの頻繁な更新に対応する必要があるため、私たちはリバース インデックスに「展開」ポスティング リスト フォーマットを使うことにしました。Dropbox のリバース インデックスは、key/value ストア(RocksDB)と、独立した 1 つの行に保存された各タプル `(namespace ID, token, document ID)`によって実現されています。具体的には、行キーのフォーマットが `”“||“”`となります。特定の名前空間にあるドキュメントに対して検索クエリが与えられると、インデックス内で `|` に対する前方一致検索を効率的に実行して、一致する全ドキュメントのリストを取得できます。名前空間の概念をキーのフォーマットに組み込んだことによって、複数のメリットが得られます。まず重要な点として、クエリに対してユーザーがアクセスできる特定の名前空間以外にあるドキュメントを返す可能性を防ぐため、セキュリティ上のメリットがあります。次に、検索対象をパーティション内でインデックス化された大量のドキュメントではなく、名前空間内にあるドキュメントのみに絞るため、パフォーマンスの面でもメリットがあります。このスキームでは、各行の値にはトークンに関連するメタデータが保管されます。
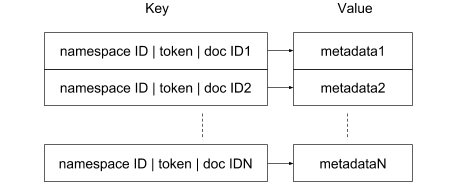
「展開」ポスティング リスト表現
これは、すべてのドキュメント ID がグループ化され、デルタ エンコーディングなどの技術を使ってコンパクト表現で保管できる従来型のフォーマットと比較すると、ストレージと検索の面での効率性は下がります。しかし、「展開」表現の主なメリットは、インデックス ミューテーションを特に効率的に取り扱えるという点です。たとえば、あるドキュメントに含まれるトークンそれぞれに対応する行を挿入することで、そのドキュメントをリバース インデックスに追加することができます。行の挿入は、RocksDB をはじめとするほぼすべての key/value ストアで非常に効率的に実行できるシンプルな動作です。RocksDB はキーのプリフィックス圧縮を適用するため、それほど多くの追加ストレージが必要になるわけではありません。全般的に、展開表現を使用するインデックスのサイズは、従来のポスティング リスト表現を使用する場合と比較すると 15 % ほど大きいだけに過ぎないことがわかりました。
2. サービング
優れた応答性を維持することは、スムーズでインタラクティブなユーザー エクスペリエンスにとって非常に重要です。サービング パフォーマンスを評価するために Dropbox が使用している指標は、95 パーセンタイルおよび 99 パーセンタイルのクエリ レイテンシです。これは、クエリの中でもっとも遅い 5 % および 1 % は、それぞれ 500 ミリ秒および 1 秒より遅くてはならないという意味です(これらは現時点での数値です)。
もちろん、中央値のクエリは、はるかに速くなります。Dropbox では、常にパフォーマンスの測定と分析を行いながら Nautilus システムの開発を進めてきました。システムの各コンポーネントは、全体のレイテンシに対する影響度を判断できるよう実装されています。開発を進める中で、次のような学びを得ました。
2-1. 最適化は時期尚早に行うべきではない
システムの全コンポーネントが全体的なレイテンシにどのように影響するか理解するまで、検索エンジンのパフォーマンス改善を控えていました。大半の時間は検索段階にかかるだろうと予想していましたが、初回のデータを分析したところレイテンシの大部分は、結果を返す前に ACL を再確認したり結果に情報を付与したりする目的でリレーショナル データベースを基盤とする外部システムからメタデータを取得する段階で発生していることがわかりました。結果に付与される情報とは、フォルダ パス、作成者、最終更新日時などです。
2-2. 「死のクエリ」は恐れるべきものである
全体的なレイテンシは、「死のクエリ」とも呼ばれる、いくつかの有害なクエリによって非常に有害な影響を受ける場合があります。これらは多くの場合、人間のユーザーではなく、プログラム的に検索 API を使用するソフトウェア エラーによって起こります。Dropbox では、システム全体を保護するために、こうしたクエリを取り除く遮断器を構築しました。
さらに、割り当てられた所定の時間を超過したら、検索エンジンがクエリに対して候補を取得するのを停止するよう、決められた時間に従う機能を導入しました。これによってパフォーマンスと全体的なシステム負荷は改善できますが、すべての結果候補を返すことができない場合があるという代償も伴います。こうした時間切れは主に、たとえば 1 つのトークンに対して前方一致検索を行うなど、多数の候補に一致する非常に範囲の広いクエリで発生します。こうしたクエリは、検索クエリの自動補完の際によく起こります。
2-3. 複製はテイル レイテンシを改善できる
リーフは、マシンで問題が発生する場合に備え、冗長化のため 2 倍に複製されています。この複製には、テイル レイテンシ(特に遅いリクエストのレイテンシ)の改善に使えるというパフォーマンス上のメリットもあります。クエリをすべての複製に送り、その中でもっとも速い応答を返すという、よく知られた技術を使っています。
2-4. ベンチマーク ツールの構築に投資すべし
具体的なコンポーネントをパフォーマンスのボトルネックとして特定したら、そのコンポーネントの負荷テストを行いパフォーマンスを測定するベンチマーキング ツールを作る方が、システム全体をテストするよりもより速く開発を進め、パフォーマンスを改善できます。
Dropbox の場合は、リーフで実行される中核の検索エンジン用にベンチマーク ツールを作りました。そのツールを使用して、パーティション レベルで合成データに対するエンジンのインデックス作成と検索のパフォーマンスを測定しています。パーティション データは、名前空間、ドキュメント、トークンの全体数や、名前空間あたりのドキュメントの分布、ドキュメントあたりのトークン数といった特性を本番環境に似せて生成されます。
3. 信頼性
多数のユーザーが、業務を遂行するために Dropbox の検索を利用しています。そのため、システムの設計時には、ユーザーが期待するアップタイムを保証できるよう、特に注意を払いました。
大規模な分散システムでは、ネットワークやハードウェアの障害、ソフトウェアのクラッシュはよくあり、避けられないものです。Nautilus は、この事実を念頭に置いて設計し、特にサービング パスにおけるコンポーネントの耐障害性と自動リカバリーに力を注ぎました。
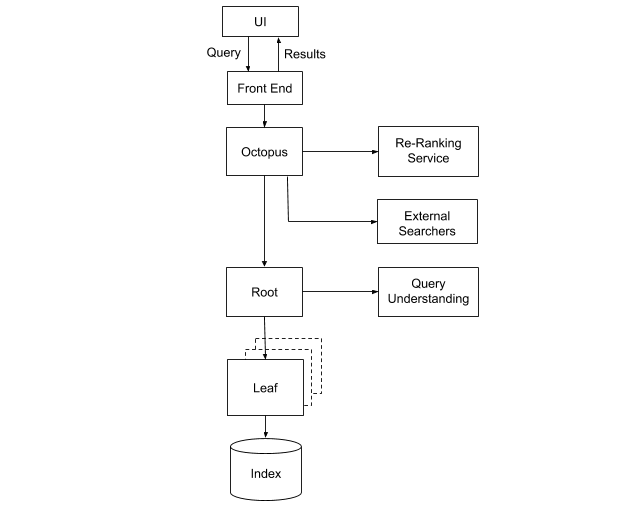
Nautilus サービング システム
一部のコンポーネントは、ステートレスに設計されています。つまり、外部のサービスやデータに依存せずに稼働していることを意味します。これには、結果を統合してランク付けする Octopus や、検索リクエストを全リーフに拡散する検索エンジンのルートなどがあります。そのため、こうしたサービスは、障害発生時に自動で再プロビジョニング可能な複数のインスタンスとともに簡単に展開できます。しかしリーフ インスタンスでは、インデックス データを維持していることから問題はより深刻になります。
4. パーティションの割り当て
Nautilus では、各リーフ インスタンスは「パーティション」と呼ばれる検索インデックスのサブセットを取り扱います。すべてのリーフのレジストリが保持され、別のコーディネーター(Zookeeper によってサポート)を使ってリーフにパーティションが割り当てられます。コーディネーターはパーティションの 100 % を継続的にカバーします。新しいリーフ インスタンスが設定されると、コーディネーターがパーティションに供給するよう指示するまでアイドル状態に留まります。指示を受けると、リーフ インスタンスはインデックスを読み込み、検索結果を受け入れ始めます。
リーフがオンラインになるプロセスの途中で、パーティション内のデータに検索リクエストが行われるとどうなるでしょうか。こうした状態に対応するため、各リーフの複製を維持しています。この複製全体を「リーフ複製グループ」と呼んでいます。1 つの複製グループは、インデックス全体をカバーする独立したリーフ インスタンスのグループです。たとえばシステムに対して 2 倍の複製を保証するには、2 つの複製グループを実行し、それぞれのグループに 1 つのコーディネーターを配置します。複製についての判断をシンプルする以外にも、このセットアップは次に挙げるようなメンテナンスの実行に関する運用上のメリット2つがあります。
どちらの場合も、プロセスの間ずっと、Nautilus はすべてのリクエストに応答できます。
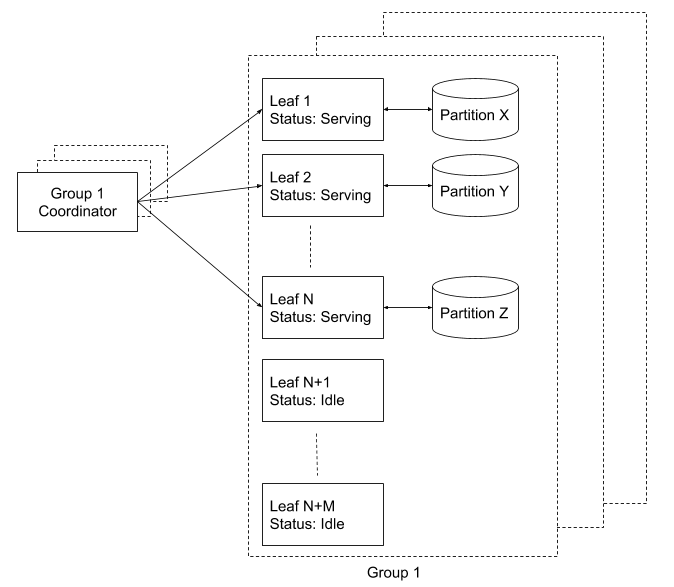
パーティションの割り当てと複製グループ
5. 復元
各リーフ グループは、アイドル状態のインスタンスがスタンバイするプールを設けるために、ハードウェア容量をおよそ 15 % 余分にオーバープロビジョニングされています。コーディネーターがパーティションのカバー範囲低下(アクティブなリーフが突然リクエストの供給を止めた場合など)を探知すると、アイドル状態のリーフを選別して、失われたパーティションに対応するよう指示を出すことで応答します。そのリーフは、次の3つの手順を実行します。
Nautilus によって実現された拡張性、業界最高水準のパフォーマンス、信頼性といった性能はさまざまなアルゴリズム、サブシステムを試行し、時間をかけて少しずつシステムを改善することによってもたらされました。
ワークロード分析の結果から適切なインデックス フォーマットを設計したり、ベンチマーク ツールを構築することによって性能を維持した状態で新しい機能の追加や検索クオリティを向上させるといった新しい開発を進めています。
Dropboxではこうした日々の継続的な改善だけでなく、Nautilus のようにアーキテクチャを定期的に刷新することによって常に数年先までの機能拡張やワークロード増大に対応しています。