企業が扱うデータが急増していますが、その大半は非構造化データを占めているのをご存知でしょうか。いまや非構造化データは、ビッグデータ活用やDXを進める中で欠かせないものになっています。しかし、中には非構造化データについてイマイチ理解しきれない人もいることでしょう。そこで非構造化データと構造化データの違い、非構造化データを活用するメリット、活用方法について解説します。
非構造化データって何? 構造化データとの違いは?
非構造化データとは、「ネイティブな形式のまま保存された」データを指します。企業で使うメールのデータや、顧客が自社のホームページに書き込んだコメント、SNSで収集した不特定多数の書き込み、請求書や納品書のPDFデータ、業務の現場で撮影した画像など、非構造化データの種類を挙げればキリがありません。最近のビジネストレンドの例でいうと、IoTシステムで収集したばかりの加工前のデータも非構造化データにあたります。
一方、構造化データとは、各種アプリケーションの中やデータベースシステムに蓄積されるデータのことです。具体的にいうと、CRM、ERPなどの業務管理システムで整理されているデータ、Excelなどの表計算ソフトによって「列」と「行」で情報がまとめられているデータを指します。
こうしたアプリケーションによって整理されるデータの中には、コンマ(,)やタブで区切られたテキストデータの形式になっているものがあります。こうしたデータを一般的には「半構造化データ」と呼んでいます。Excelなどの中で処理されることで、コンマ区切り、タブ区切りのデータはどういうものなのかがわかりますが、テキストだけのデータを見てもすぐにはその中身を判断することはできないので、中間的な位置づけにしているのです。
このようして整理すると、非構造化データとは構造化データになる前の、アプリケーションで処理される以前の「生データ」ということになります。
ビジネスの高度化に伴い、非構造化データも増加
企業の中で発生するデータのほとんどは非構造化データだといわれており、毎年増加し続けています。いま企業はさまざまな変革への取り組みを進めており、そのためにより多くの非構造化データが生産され続けているのです。
生産DXを実現すべくIoTシステムを導入する、紙ベースの製品資料をデジタル化する、顧客窓口となる電話対応のやり取りをテキスト化し顧客ニーズを分析する、領収書や請求書、伝票などを電子化しペーパーレス化を推進する、といった取り組みによって非構造化データはどんどん増加していきます。
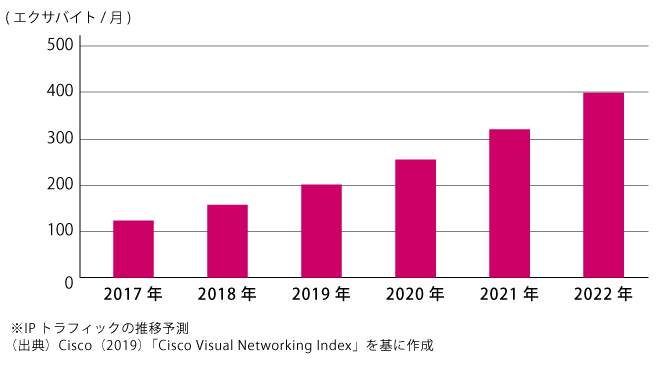
参照:総務省 令和2年版 情報通信白書「データ流通量の推移」
また非構造化データの増加は、5Gの進展によってさらに進むはずです。令和2年版の情報通信白書によると、「月間のIPトラフィックは、2022年までに396エクサバイトに達し、2017年からの5年間で3倍に増加する」と紹介しており、今後のデータ流通量の爆発的拡大を示唆しています。
もはや既存のERPやCRMといった業務システムの中に格納されるデータのみを活用するだけではなく、さまざまなコネクティビティから発生するテキスト、映像、画像などの非構造化データは、欠かせないものとなっています。これらをうまく活用して業務改善を行ったり、顧客サービスを充実させたり、あるいは新規ビジネスを立ち上げたりといったことが求められているわけです。
このように非構造データはビジネスを高度化するうえで欠かせないものになりつつあります。一方で、非構造データをどのように活用していくのかが、多くの企業で課題となっています。
非構造化データの賢い使い方とは?
非構造化データが発生した瞬間からアプリケーションで利活用できるように加工すればいいのですが、実際にはそのような利用方法はコストの面から困難でしょう。
なぜなら、各アプリケーションが利用するストレージシステムは莫大なキャパシティが必要となりますし、データの処理にも時間がかかるからです。また、データ処理能力を拡張するにしてもコストがかかってしまいます。
さらに、データはさまざまな用途があるので、加工したデータだけを残して生データは捨てるという運用は現実的ではありません。やはり、どのように加工していったとしても、元のネイティブな形式のデータは保存し続けなくてはなりません。
例えばIoTシステムで利用する生産管理のデータであれば、用途も限定的で専用システムも用意されているので、ネイティブな形式のデータは比較的に管理しやすいといえます。しかし、動画や画像、音声といった各社員や事業部が記録したデータ、個々人が発生させた領収書、請求書、納品書などの書類は、ファイル形式もバラバラで用途も多岐にわたるため、社内に散在しがちです。
また、個人や部門でこうしたデータを整理し、企業が用意したストレージにきちんと格納するだけでは不十分です。万が一に備え、組織全体でバックアップの仕組みを整えておく必要があります。
さらにいえば、収集した非構造化データの全社活用も求められてきます。その際に、データの収集元の部門に管理を一任し、要請に応じて他部門にデータを渡すといったルールでは経営判断が遅くなってしまいます。いつでもどこでも、必要に応じてデータを素早く活用できる体制づくりが今後求められてくるでしょう。
まとめ
このように、増加の一途をたどる非構造化データを、より簡単に保管するにはどうすればいいでしょうか。
この課題に対し、Dropboxの導入が有効です。Dropboxを活用することで効率的なコンテンツ管理が可能になり、大規模な投資をすることなく、非構造化データを迅速、安全に保管、活用することができます。
もし組織内の既存のシステムでデータ管理ができているという場合でも、バックアップ先として簡単に利用することが可能です。IoTデータなども、加工前のデータはすべてDropboxにバックアップしておく、ということもできます。また部門ごとに保管しているデータも、すべてDropbox内の同じシステム内に保管することができるので、権限設定を一時的に変更することで、全社的に個別のデータを利用することもすぐに実現できます。
このようにDropboxを利用すると、非構造化データを簡単に、そして暗号化によって安全に保管することができるようになります。さらにそのデータを利活用する場面においても、シンプルに共有できるため、加工プロセスに移行するのが容易になります。
またコラボレーション機能も充実しており、各種アプリケーションを数クリックで利用できる環境を提供しています。データの所在場所もすぐに分かる仕組みがありますし、高度な分析のためのデータ加工も外部のデータウェアハウスやBIシステムなどと連携して実行できるため、導入することでデータ活用のスピードアップが実感できるはずです。
全社的なデータ活用にお困りの方はぜひDropboxをご検討ください。