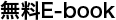
Dropbox は社内向けのエクサバイト級ストレージ システムである Magic Pocket の運用を開始して以来、高い信頼性基準を維持しながらも効率性を高める方法を追い求めてきました。
昨年は、主要テクノロジー企業として初めて SMR ストレージを導入し、ストレージ密度の限界をさらに押し広げました。
この記事では、Dropbox が達成したもう 1 つのストレージ技術革新である、新しいコールド ストレージ層についてご紹介します。これは、利用頻度の低いデータのために最適化されたストレージ層です。このストレージは、利用頻度の高いデータと同様、内部ネットワークを介し SMR ディスクで運用されています。
目次
- 時間経過から見るファイルの特性
- Magic Pocket
- リージョンを越えたレプリケーション
- 要件
- 初期の設計案
- 複数リージョンにまたがる単一の消失訂正符号
- Facebook のウォーム BLOB ストレージ システム
- 新しいレプリケーション モデル
- 耐久性
- コスト削減
- まとめ
1. 時間経過から見るファイルの特性
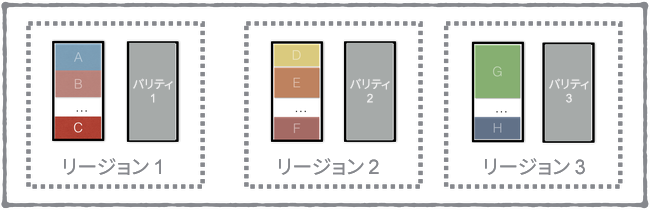
Dropbox に保存されるファイルの利用には、時間の経過に大きく依存した特性があり、アップロードされてから数時間は非常に頻繁に利用されますが、その後は急激に利用頻度が下がります。以下のグラフは、昨年アップロードされたファイルの利用回数を累積分布関数を使って表したものです。
Dropbox で行われるファイル アクセスは、全体の 40 % 以上が前日にアップロードされたデータ、全体の 70 % 以上が前月にアップロードされたデータ、90 % 以上が前年にアップロードされたデータです。この特徴はごく当然といえます。ファイルが新たにアップロードされると、OCR の実行、検索トークンを抽出するためのコンテンツ解析、Office ドキュメントのウェブ プレビュー生成など、ユーザー体験を強化するため多くの内部システムがファイルを取得しようと動作します。ユーザー側でも、新たに作成したファイルは共有する可能性が高く、新しいファイルはアップロード直後に他のデバイスへと同期されることが多くなります。一般論として、ユーザーは前年に作成したファイルよりも、最近のファイルをより頻繁に利用する傾向があります。
Dropbox では、利用頻度が高いデータを「ウォーム」、利用頻度が低いデータを「コールド」と呼んでいます。ウォーム データとコールド データで利用特性が異なることから、これら 2 種類のデータに合わせてシステムを最適化し、コストの最適化を計ろうという機運が生まれました。
2. Magic Pocket
Magic Pocket は、ファイルを保存するための Dropbox のシステムです。Dropbox では、ファイルを最大 4 MB の「ブロック」と呼ばれる塊に分割しています。ブロックは不変であり、あらゆるメタデータ操作や書き換えおよび変更履歴に関する複雑な処理は、上位のメタデータ層で処理されます。Magic Pocket の役割は、こうした大容量ブロックを永続的に保存し、処理することです。
このシステムは、かなり低い利用頻度向けの作業負荷を想定して設計されています。安価で耐久性に優れ、帯域幅が比較的広いという利点のある回転ディスクを利用し、ソリッド ステート ドライブ(SSD)はデータベースやキャッシュのために使われます。
Magic Pocket では、ファイルが作成されてからの経過時間に応じて、データ符号化を使い分けます。Magic Pocket にファイルがアップロードされた当初は、比較的多数のストレージ ノードで n-way レプリケーションを行います。その後、時間が経過するとより効率的な消失訂正符号により古いデータをバックグラウンドで符号化します。
Magic Pocket は、地理上の特定リージョンに限定すれば効率性の高いストレージ システムです。地理的に広いリージョンでデータ レプリケーションを行うことで大規模災害に対する耐性は高まりますが、同時に全体的な効率を大幅に引き下げてしまいます。
3. リージョンを越えたレプリケーション
コールド ストレージ開発について理解するには、Magic Pocket のしくみについて概要を理解しておく必要があります。
Magic Pocket はストレージ リージョン内に非常に信頼性の高い方法でブロックを保存しますが、同時に少なくとも 2 つ以上の別のリージョンにも同じデータを保存します。リージョン内のしくみは非常に複雑ですが、リージョン間のインターフェースはとてもシンプルで、基本的に PUT、GET、DELETE を整備したようなものです。
多くの企業で行っているのは、数十キロかせいぜい数百キロ離れたデータセンター同士でのデータ レプリケーションです。
Dropbox では、リージョン全体が停止した場合の耐久性と可用性を大幅に高めることを目指し、何千キロ離れたデータセンター間でデータ レプリケーションを行っています。大規模災害が発生した場合でも耐えられるよう、2 倍のデータを保存しています。
しかし、ここで発生するオーバーヘッドは長年改善の対象でした。Magic Pocket の誕生以来、考え続けていたことがあります。それは、「高い安全基準を維持したまま、より効率的な方法にシフトすることはできないだろうか」という問いです。
4. 要件
異なるワークロードに合わせてシステムをより適切に調整できるよう、2 種類のストレージ層を運用することに決めました。新たにコールド ストレージ層を構築し、元からあった Magic Pocket システムをウォーム層と呼ぶことにしたのです。データが「コールド」の状態になると、バックグラウンドでデータを非同期で移行するようにしました。コールドでないデータはすべて、ウォームとみなされます。
コールド ストレージ システムに求められる基本的な要件はいたってシンプルで、決して耐久性を損なわないことのみです。たとえ使用頻度が低いファイルであっても、ユーザーは Dropbox を信頼して大切なデータを預けていることを忘れてはいけません。リージョン全体の停止に対する耐性と並行して、残っているリージョンのうち複数ラックの障害に対しても耐性が必要です。可用性の面では、読み取りの可用性については妥協することはできませんが、書き込みの可用性については心配していません。ユーザー側からの書き込み操作はウォーム ストレージ層に書き込まれるため、コールド ストレージ層への書き込みはユーザーに影響を与えずいつでも一時停止できます。
コールド データでのレイテンシ微増は許容できます。これは、インターネット経由でのファイル送信にかかる時間と比べると、Magic Pocket がすでに非常に高速であるためです。それでも高速で信頼性の高いアクセスは必要です。たとえば、10 年前の税務書類を見る頻度はそう高くないにしても、実際に見なければならないときに何分も待たされるのでは困ります。
5. 初期の設計案
リージョン間の完全なレプリケーションを何らかの方法で排除しつつも、地理的なリージョンの停止には対応している必要があります。
各リージョン内で完全な内部レプリケーション コピーを保持するのではなく、異なるリージョン同士でのデータ レプリケーションができれば、ストレージ コストを引き下げることができるかもしれません。
しかしこれは、リージョン単位での停止が発生した場合にファイルを再構築しようとすると、ワイド エリア ネットワークのコストが高まることを意味します。
ただ、ネットワーク コストが高まる可能性と引き換えに、それほど頻繁には取得されないコールド データのストレージ オーバーヘッドが低減するのであれば、賢い選択でした。
残念なことに、最初の挑戦では適切な形で実現することができませんでした。膨大な時間を費やして構築したソリューションでしたが、満足できる結果にはなりませんでした。最終的に実現できた「良い」ソリューションについて詳しく説明する前に、「一見すると良さそうだが、実はうまくいかなかった」というアイデアをいくつか紹介します。
6. 複数リージョンにまたがる単一の消失訂正符号
わかりやすいアプローチとしては、リージョン間の厳格な境界線をなくすというものです。つまり、各リージョンで独自にレプリケーションを行うのではなく、単一のソフトウェア インスタンスを用意して、全リージョンで消失訂正符号化を行うのです。消失訂正符号なら、リージョン単位での大規模災害にも耐えうる、十分な内部冗長性が確保できるはずです。
私たちは実際に、このアプローチで計画をかなり進めていました。新システムのプロトタイプは、比較的早く検証環境に構築し、稼働させることができましたが、次第に多くの問題が発生するようになり、気がつかなかったコストも明らかになってきました。設計が複雑であったため、ストレージ関連のあらゆるチームに積極的に関与してもらう必要が生じ、結果として開発の遅れにつながっていきました。
このアプローチの最大の問題は、耐久性のリスクを完全には抑えられないという点です。システムでは、耐久性を損なわないことが大前提です。純粋な理論上は、当初のシステムと同程度の 100 % に限りなく近い耐久性を実現していましたが、実際の運用では同等の耐久性は保証できませんでした。大規模なリージョン 1 つで単一バージョンのソフトウェアを実行している場合、コピーをいくつ保持していたとしても、たった 1 つのソフトウェア バグですべてが失われる可能性があります。
Magic Pocket の独立リージョン モデルは、エンジニアのミスによるソフトウェア バグやオペレーターのミスによる不適切なコマンド実行など、人的ミスに対してきわめて高い耐性を持っています。2 つのストレージ リージョン間にあった強力な論理的境界線を排除することは、最後の砦を破壊する行為に等しいと言えます。長期的に見れば、データ喪失の可能性を大幅に高めてしまいます。
9 か月以上もこのプロジェクトを積極的に進めた後、ついに取りやめることになりました。エンジニアにとって、長期にわたって取り組んでいたものを諦めるのは容易ではありません。当初の話し合いでは意見が割れることもありましたが、最終的にはプロジェクト中止が Dropbox とユーザーのためになると全員が同意しました。
7. Facebook のウォーム BLOB ストレージ システム
独立した障害領域を克服しようと模索する中で、独立した障害領域に意義があることを再発見した私たちは、ゼロからやり直すことにしました。初期の調査段階で除外されたものの中に、ある興味深いアイデアがありました。このアイデアは、Facebook のウォーム BLOB ストレージ システムから着想を得たものです。
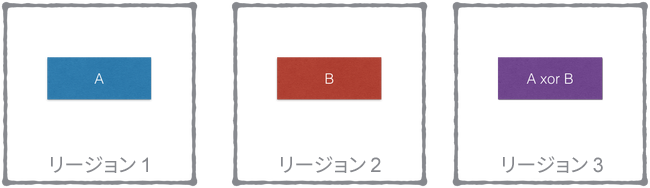
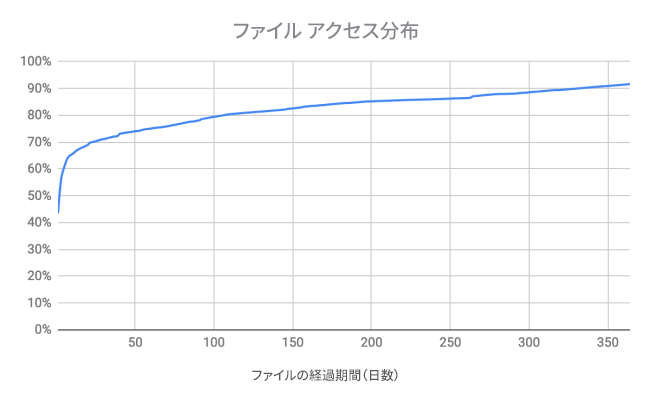
それぞれの `volume/stripe/block` に対して、地理的に異なる場所にある `volume/stripe/block` をペアにします。さらに、第三のリージョンには前述のペアの `XOR` を保存するという方法です。
上記の例では、`block A` をリージョン 1 から取得できます。リージョン 1 が利用できなくなると、リージョン 2 の `block B` とリージョン 3 のブロック `A xor B` を取得して XOR を実行することで `block A` を再構成できます。これは妙案です。Magic Pocket のリージョン内部には何の変更を加える必要もなく、外部のレプリケーション方法を変えるだけでした。
この方法についてさらに深く調査を進めました。しかし、しばらくしてこのアイデアも諦めざるを得なくなりました。こうしたブロックのペアを使って利用可能なデータ構造を世界的に維持するうえで、問題が多数発生しました。Dropbox では予測できない削除パターンが存在するため、ブロックが削除された場合にスペースを取り戻す何らかのプロセスが必要でした。他にも多くの問題が複雑に絡み合っていて、Dropbox への適用としては最適な選択肢ではないという結論に至りました。
8. 新しいレプリケーション モデル
これまでの取り組みがすべて無駄だったというわけではありません。結果的には失敗に終わったとしても、これまでの設計案を形にしようと時間をかけて努力したその経験が、ネットワーク スタックのトレードオフについて貴重な知見を生みました。初歩的なある思い込みに気がついたのです。
それは、「すべてのリージョンが正常に稼働しているベストな状態において、単一のブロックに対するリクエストに対して、単一リージョン内から完全に応答する必要があるのか」という点です。コールド データの使用頻度が低いことを踏まえると、コールド データへのアクセスの際に常に高いネットワーク コストが生じるのも問題はないはずです。「単一のリージョンから応答しなくてはならない」という制限を外したことで、次のような設計案が浮上しました。
3 つのサンプル リージョンとパリティ ブロックを生成するための XOR を使用して、そのしくみを説明しましょう。リード ソロモンの消失訂正符号のようなものを使用してパリティを生成すれば、この方法を一般化してより大きなリージョン群にも適用することができます。
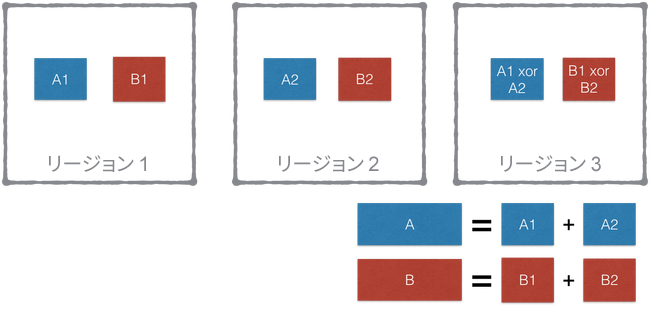
前の設計と同様、リージョン内の内部アーキテクチャには変更を加えないようにしたいと考えました。ただし、近いサイズのブロックを見つけてペアにするのではなく、単一のブロックをフラグメントと呼ばれる複数の断片に分割し、これらのフラグメントを複数のリージョンにわたってストライプ化することにしました。
ブロックの PUT 処理
3 つのリージョンを含む上記の例では、ブロックを 2 つのフラグメントに分割しています。1 つ目のフラグメントをリージョン 1 に置き、2 つ目のフラグメントをリージョン 2 に置きます。そして、両フラグメントの XOR を演算して第三のパリティ フラグメントを生成し、それらをリージョン 3 に置きます。
データは非同期でコールド層に移行するため、いずれかのリージョンが停止しているような複雑な状況を想定する必要はありません。リージョンの 1 つが停止した場合は、3 つの全リージョンが稼働するまで移行を停止すればよいだけです。
ブロックの GET 処理
3 つのリージョンすべてに対して GET リクエストを送信し、最も早く返ってきた 2 つのレスポンスを受信して、残り 1 つのリクエストはキャンセルします。再構成に使用する 2 つのフラグメントについて、優先度はまったく設定していません。ディスクからデータを読み取ってネットワーク経由で送信する操作に比べれば、XOR の計算や消失訂正復号は大変小規模な操作です。
ブロックの DELETE 処理
ブロックが参照されなくなった場合は、すべてのフラグメントを削除するだけです。もう 1 つの便利な特性は、DELETE 操作をリージョンごとに独立して行える点です。つまり、削除を行うソフトウェアを複数バージョン用意したり、削除操作を別々のタイミングで実行したりできるということです。そのため、ソフトウェアのバグが原因で、すべてのフラグメントを誤って削除してしまうことを防止できます。
レイテンシ
このモデルで最も顕著な欠点は、最善の状態であっても複数のリージョンからフラグメントを取得しなければ読み込みを行えないという点です。しかし、これは思っていたほど大きな問題ではありませんでした。むしろ、多くの点で意外なメリットを生むことにもなりました。
新しいストレージ層を導入する際に、さまざまなパーセンタイルで計測したレイテンシが次のグラフです。
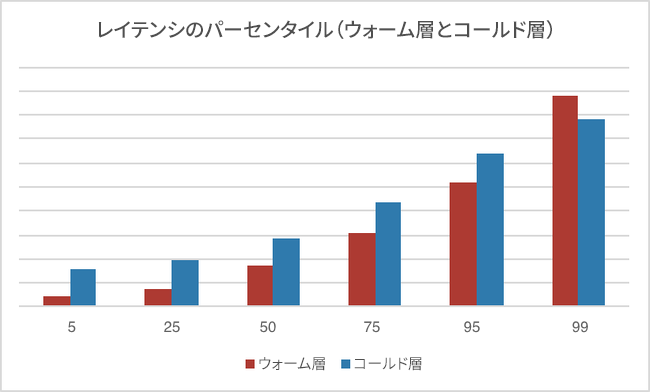
まず、5 パーセンタイルのレイテンシはコールド層で非常に高くなっています。これは、コールド層からデータを取得するためには、リージョン間のネットワーク ラウンドトリップが 1 回以上必要になるためです。25、50、75、95 の各パーセンタイルを見てみると、ウォーム層とコールド層でのレイテンシの差は一定で、およそネットワーク ラウンドトリップ 1 回分となっています。Dropbox のネットワーク スタックはすでに、大容量のデータ ブロックを遠く離れた場所まで転送するために最適化されています。
Dropbox では徹底的に調整されたネットワーク スタックと、Courier と呼ばれる gRPC ベースの RPC フレームワークを使用していて、HTTP/2 トランスポート層でリクエストを多重化します。こうしたしくみによって、大きなウィンドウ サイズのウォーム TCP 接続が可能になり、1 回のラウンドトリップで数メガバイトのデータ ブロックを転送できるようになります。
しかし当初は、99 パーセンタイルの結果を見てとても困惑しました。コールド層でテイル レイテンシがウォーム層より低いという事実に驚きました。この奇妙な現象は、調査を進めていくうちに解き明かされていきました。
コールド層では、3 つリクエストのうち早く返ってきた 2 つのリクエストを使用します。ところが、ウォーム層の再試行ロジックはより素朴です。まず、最も近いリージョンから取得を行い、最初のリクエストが失敗またはタイムアウトになった場合にのみ、別のリージョンにリクエストを送信するというしくみです。大規模な分散システムにおいては、どこかで必ず偶発的な遅延が発生します。ウォーム層はトラフィックの大部分を受け付けているため、より洗練された処理が必要で、並行して 2 つのリクエストを送信することはできません。最終的にウォーム層の仕様を改めることにしました。ウォーム層では、最初のリクエスト試行が指定した予定時間内に到着しなかった場合に、2 つ目のリージョンに結果整合を見込んでリトライを送るという楽観的手法です。これにより、ネットワーク オーバーヘッドの上昇はわずかに抑え、ウォーム層でのテイル レイテンシを引き下げることができました。この技術について詳しくは、Velocity でのジェフ・ディーン氏の講演が参考になります。
コールド層の優れた性質の 1 つに、常に最悪のシナリオを想定して動作している点があります。プラン A とプラン B は用意されていません。リージョンが停止しているかどうかにかかわらず、データを取得するには必ず複数フラグメントからの再構成を必要とします。それまでの設計案ともウォーム層とも異なり、リージョンが停止した場合でもトラフィックが急激に変化したり、残りのリージョンでディスク入出力が増えたりすることはありません。そのため、ピーク時に緊急のフェイルオーバーを行った際でも、予期せぬ容量オーバーを心配する必要がなくなります。
要件ですでに述べたように、レイテンシについては決まった目標を設けず、単に方向性を示しただけでした。全体として、得られた結果は期待を大きく上回るものでした。インターネット経由でファイルを転送している大半のエンド ユーザーには、こうした些細な違いによる影響はありません。この事実は、より積極的に「コールド」なデータを定義して移行させようという動機になりました。
9. 耐久性
耐久性の面で最大の成果は、アーキテクチャを層構造にし、シンプルに保てたことです。以前と同様、各リージョンは独自に稼働でき、ソフトウェア バージョンも異なるものを使用できます。このため、データのすべてのコピーに影響が出る前に、テストで見過ごしそうな問題を発見することができます。発生するまでに長い時間のかかるまれなバグや、リリース プロセスでも見過ごされてしまうようなバグであっても、複数のリージョンにある同一のデータに同時に影響が出ることはきわめてまれです。
このしくみは、事前に予期することのできない不確実性に対して、重要な最後の砦になります。これは定量化することは難しいのですが、非常に高い耐久性が確保されていることで、開発をすばやく進めることができます。
現在でも、個々のリージョン全体でデータが永続化する前に発生しうるレプリケーション ロジックのバグに対する脆弱性はあります。ただし、影響を受ける範囲、危険にさらされるデータの量、関係するコード パスの数は限定的です。コールド層へ移行してすぐにはウォーム層からデータを削除しないようにすることで、バグによる危険性を大幅に低減することができています。また、徹底した検証を複数回行ったうえで、元の場所からデータを消去するようにもしています。
10. コスト削減
ウォーム層のレプリケーション モデルは 1+1 のレプリケーション スキームです。これは当然ながら、1 つのデータ フラグメントに対して 1 つのパリティ フラグメント、これらのリージョン内でのレプリケーションという組み合わせです。3 つのリージョンを使ったコールド層の例は、2+1 のレプリケーション スキームです。これは、2 つのデータ フラグメントに対して 1 つのパリティ フラグメント、そしてリージョン内のレプリケーションという組み合わせです。ウォーム層でのレプリケーション ファクタの合計数は 「2 * region_internal_replication_factor」 となり、コールド層では 「1.5 * region_internal_replication_factor」となります。つまり、3 リージョンの構成を採用することで、ディスク使用量を 25 % 削減できることになります。
すでに述べたように、このアプローチはリージョン数が増えた場合でも適用できます。リージョンを 4 つに設定し、いずれか 1 つのリージョン停止を許容できる場合は、3+1 のモデルとなり 33 % の削減が見込めます。コスト節約と、リージョンで許容可能な同時停止数の兼ね合いに応じて、さらに 4+1 や 5+2 のモデルにも拡張することができます。
11. まとめ
私たちは、コールド ストレージ層を構築するためにさまざまなソリューションを検討する中で、制限を課すことが問題解決のアプローチを大きく左右するということを学びました。たとえば、「独立した障害領域の確保は絶対条件」などの新しい制約を追加すると、調べる範囲が絞り込まれるため、早い段階で採用しない設計案が明確になり、集中的に作業ができることがあります。
一方、「安定した状態でリージョン内からすべての読み取り操作に応答する」など、制約を除外することで、まったく新しい可能性が開けることもあります。
Dropbox ではデータ重視の意思決定を目指してはいますが、時に認識を誤ってしまうということも学びました。決断に必要なすべてのデータが揃うということはまれです。どのようなデータを考慮すべきかがわからない、という状況さえあります。物事を成功させるための唯一の方法は、失敗を恐れずに挑戦することです。間違いに気がついたときに手を引くのであれば、誤った意思決定がもたらす損害もそう大きくはありません。正直に失敗を認め、必要に応じて軌道修正していくことが大切です。
問題解決の方法について知見が得られただけでなく、最後には Dropbox のニーズにぴったりのコールド ストレージ システムの完成にこぎ着けることができました。さらには、耐久性と可用性を損なうことなく、アーキテクチャを複雑にすることもなく、ストレージ コストを大幅に引き下げることができたのです。