Dropbox は、Python のビッグ ユーザーです。Python は、バックエンド サービスとデスクトップ クライアント アプリの両方で最も広く使用されています(Dropbox は Go、TypeScript、Rust のヘビー ユーザーでもあります)。
Dropbox の Python コードは数百万行にも及ぶ規模となっていますが、その動的型付けによってコードが必要以上に理解しにくくなり、生産性に深刻な影響を与えるようになりました。
これを軽減するため、現在私たちは最も普及している Python スタンドアロン型チェッカー、mypy による静的型チェックにコードを徐々に移行しています(mypy はオープン ソース プロジェクトであり、そのコア チームは Dropbox 内に設立されました)。
Dropbox は、この規模での Python 静的型チェックを導入した最初の企業の一つです。最近では、何千ものプロジェクトで mypy が使用され、非常に厳しいテストが行われています。
私たちは長い道のりを経てここにたどり着きましたが、その間もスタートでのミスや実験の失敗を何度も繰り返してきました。
この投稿では、Dropbox で実施した Python の静的チェックを取り上げます。
私の学術研究プロジェクトの一環としてスタートしてから、Python コミュニティの多くの開発者にとって型チェックや型ヒントが一般的になるまでについてお話しします。IDE やコード アナライザーなどのさまざまなツールの登場も、この現状を支えています。
目次
- なぜ型チェックをするのか
- mypy の歴史
- 型を標準化(PEP 484)
- 移行開始
- パフォーマンスの向上
- さらなるパフォーマンスの向上を目指して
- ついに 400 万行に到達
- 実現までの課題
- 次なる目標は 500 万行以上
1. なぜ型チェックをするのか
動的に型付けされた Python しか使用したことがなければ、静的型付けと mypy がなぜ話題になるのか不思議に思うでしょう。Python は、動的型付けを備えているから楽しいという部分もあるかもしれませんが、全体を見通しにくくなる場合があります。静的型チェックの鍵は、規模です。プロジェクトが大きくなればなるほど、静的型チェックの必要性を感じるようになります(最終的には必須になります)。
経験からいえることは、複数のエンジニアが関与する数万行のコードを扱うようなプロジェクトでは、開発者の生産性を保つ鍵はコードの理解にあります。型アノテーションがなければ、関数への有効な引数、または可能な戻り値の型を把握するなどの基本的な推論も難しい問題になります。型アノテーションがないと、以下のような問いへの回答は概して難しいでしょう。
- この関数は 「None」 を返すか。
- この 「items」 引数は何か。
- 「id」 属性の型は 「int」 か、「str」 か、それともカスタム型か。
- この引数はリストにする必要があるか、タプルやセットを指定できるか。
下のコードの一部分は、型アノテーション付きですが、これを見れば上記すべての質問に答えることができます。

- 戻り値の型が 「Optional[…]」ではないため、「read_metadata」 は 「None」 を返さない。
- 「items」 引数は文字列のシーケンスであり、任意のイテラブルにはなり得ない。
- 「id」 属性はバイト文字列である。
もちろんドキュメンテーション文字列(docstring)で文書化されているのが理想的ですが、経験上、そうではないことが多いと圧倒的に言えます。ドキュメントがあっても、その正確さを当てにはできません。ドキュメンテーション文字列があっても、あいまいであるか正確でないことも多く、誤解を招く余地が多くあります。大規模なチームやコードベースにとって、これは大問題になり得ます。
Python は、プロジェクトの初期段階や中期段階では非常に優れていますが、ある時点で、Python を使用して成功したプロジェクトや企業は、次のような重要な判断に迫られることがあります。つまり、「静的に型付けされた言語ですべてを書き換えるべきか?」という判断です。
mypy のような型チェッカーでは、型を記述するための正式な言語を提供し、提供された型が実装と一致すること(また必要に応じてそれらが存在すること)を検証することで、こうした問題を解決します。つまり、検証済みのドキュメントを提供するのです。
他にも利点がありますが、どれも重要と言えます。
- 型チェッカーは大小問わず多くのバグを見つけます。「None」 値などの特別な条件の処理が忘れられているような場合が、よくある例です。
- 型チェッカーは、どのコードの変更が必要かを正確に教えてくれることが多いため、リファクタリングがはるかに簡単です。非現実的な 100 % のテスト カバレッジは不要です。何が誤っていたのかを理解するのに、スタック トレースを深く調べる必要はありません。
- 大規模プロジェクトでも、mypy では、たいていほんの数秒で完全な型チェックを実行できます。多くの場合、テストの実行には数十秒または数分かかります。型チェックによって、迅速なフィードバックが行われ、より高速に反復できます。すばやいフィードバックを得るために、あらゆる状態を模倣してパッチを当てるといった脆弱でメンテナンスが困難な単体テストを作成する必要はありません。
- IDE や、PyCharm、Visual Studio Code などのエディタでは、型アノテーションを利用してコード補完を提供し、エラーを強調表示することで、より適切に定義機能に移行できるようにしています。これらは、型が使えることで利用できるようになる便利な機能のごく一部です。一部のプログラマーにとって、これは最大で最速の利点です。この使用事例では、mypy などの個別の型チェッカー ツールは必要ありませんが、mypy によりアノテーションとコードを最新状態に同期できます。
2. mypy の歴史
mypy のストーリーは、私が Dropbox に入社する数年前、英国ケンブリッジで始まります。博士課程の研究の一環として、静的に型付けされた言語と動的言語を何らかの形で統合できないかと考えていました。Siek や Taha の漸進的な型付けや Typed Racket などの作業に触発され、連続した過程のいかなる時点でも妥協することなく、小さなスクリプトから数百万行に肥大化したコードベースのプロジェクトにいたるまで同一プログラミング言語を使用する方法を模索していました。この重要な点は、型付けされていないプロトタイプから、厳しくテストされ、静的に型付けされた製品へと徐々に成長させるというアイデアでした。これらのアイデアは現在、概ね当たり前のように受け止められていますが、2010 年当時は活発に議論されていた研究課題でした。
型チェックに関する最初の仕事では、Python は対象ではありませんでした。代わりに用いたのは、Alore と呼ばれる独自開発の小さな言語でした。以下は、これがどのようなものかという一例です(型アノテーションはオプションです)。

簡素化されたカスタム言語を使用することは、一般的な研究アプローチです。
とりわけ実験を迅速に行うことができ、研究に不可欠ではないさまざまな懸念を都合よく無視できるからです。製品レベルの言語は大きくなる傾向があり、実装が複雑になるため、実験に時間がかかります。しかし、実用性に欠けてしまう場合があるため、主流ではない言語に基づく結果は多少信ぴょう性に問題が生じる可能性があります。
Alore の型チェッカーはかなり有望に見えましたが、Alore にはない実在のコードで実験を行って検証したかったのです。幸い、Alore は Python に大きな影響を受けていました。Python の構文とセマンティクスに狙いを定めてチェッカーを修正するのはとても簡単で、オープン ソースの Python コードの型チェックを試してみることができました。また、Alore から Python へのソース間トランスレーターを作成し、それを使用して型チェッカーを翻訳しました。
これで、Python サブセットをサポートする Python で書かれた型チェッカーができました(Alore においては意味を持っていた設計上の決定の中には、Python にはあまり向かないものもありました。それらは今も mypy コードベースの中に見られます)。
実際、その時点での言語は、Python ではなく、Python の変種でした。
これは Python 3 型アノテーション構文に特定の制限があったためです。
言ってみれば、Java と Python を混ぜたようなものです。

当時のアイデアの 1 つは、Python の変種を C または JVM バイトコードにコンパイルすることで、型アノテーションを使用してパフォーマンスを向上させることでもありました。プロトタイプ コンパイラの構築までいきましたが、あきらめました。型チェックがそれだけで十分に役立つと思われたからです。
最終的に、サンタ クララで開催された PyCon 2013 カンファレンスでプロジェクトを発表し、それについて Python の BDFL であるグイド・ヴァンロッサム氏と話しました。彼に、カスタム構文はやめて、Python 3 構文一本に集中するよう説得されました。Python 3 は、関数のアノテーションをサポートしているため、次のような有効な Python プログラムを書くことができます。

いくつかの妥協が必要でした(これがそもそも独自の構文を考案した理由です)。特に、その時点では最新であった Python 3.3 は、変数アノテーションがありませんでした。ヴァンロッサム氏とメールでさまざまな構文の可能性について話し、変数に型コメントを使用することにしました。これは役に立ちますが、あまりスマートではありません(Python 3.6 では、はるかに優れた構文が利用できるようになりました)。

型コメントは、型アノテーションの概念がない Python 2 でも便利なものでした。
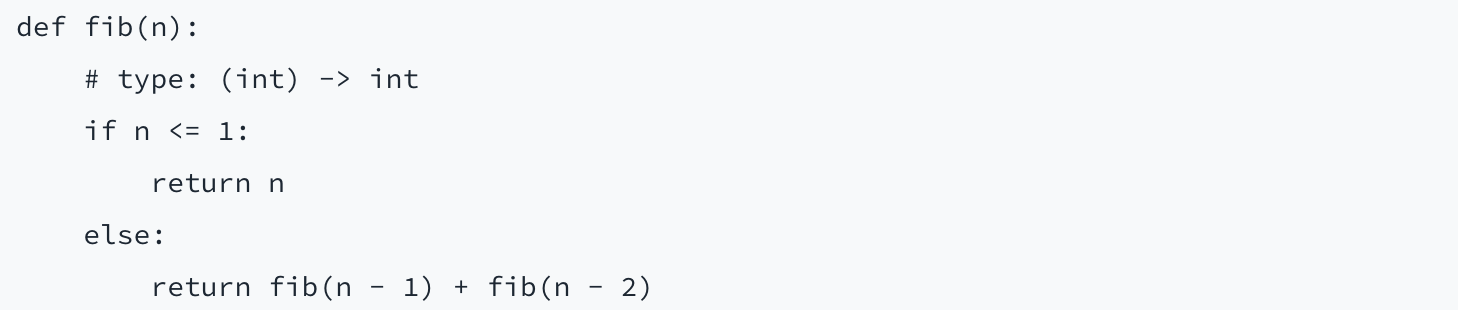
結局、こうした妥協はあまり重要ではないことがわかりました。静的型付けの利点のおかげで、ユーザーは、理想とまではいかない構文のことはすぐに忘れてしまったからです。型チェックされた Python には特別な構文がなくなり、既存の Python ツールやワークフローは引き続き機能し、導入も非常に容易でした。
博士号を取得後、Dropbox に参加するようヴァンロッサム氏に説得され、そして、このストーリーの核心部分が始まるのです。
3. 型を標準化(PEP 484)
ハック ウィーク 2014 の開催中、Dropbox では、mypy を使用した最初の本格的な実験を行いました。ハック ウィークは、Dropbox が主催するイベントで、「何でもあり」の週間です。最も有名な Dropbox エンジニアリング プロジェクトのなかには、ハック ウィークに端を発するものもあります。結論として、mypy の使用は有望に思えましたが、まだ広く導入する準備がきちんと整っていないことが分かりました。
Python で型ヒント構文を標準化するというアイデアは、その頃に浮かんできました。前述のように、Python 3.0 からは Python で関数型アノテーションを書くことができましたが、それらは構文もセマンティクスも指定されていない、単なる任意の式でした。これらは、実行時にほとんど無視されます。ハック ウィーク後、セマンティクスの標準化作業を開始し、最終的に PEP 484 を作成しました(ヴァンロッサム氏、ルーカス・ランガ氏、および私で共同執筆)。
動機は 2 つありました。1 つ目は、Python エコシステム全体に、相互に互換性のない複数のアプローチではなく、型ヒント(型アノテーションを表す Python 用語)の一般的なアプローチが採用されることを望んだことです。2 つ目は、少数の異端者とならないよう、より広い Python コミュニティと型ヒントを使用する方法を率直に議論したかったからです。「ダック タイピング」で有名な動的言語として、コミュニティでは静的型付けに関する疑念が最初は確かにありましたが、オプションのままであることが明らかになったとき(そして実際に有用であると皆に理解されると)、その疑念は最終的に払拭されました。
最終的に受け入れられた型ヒント構文は、mypy が当時サポートしていたものとよく似ていました。PEP 484 は、2015 年に Python 3.5 とともに世に出され、Python は、もはや単なる動的言語ではなくなりました。私はこれを、Python の大きなマイルストーンだと考えています。
4. 移行開始
2015 年後半、mypy に取り組む 3 人のチームが Dropbox で結成されました。メンバーは、ヴァンロッサム氏、グレッグ・プライス氏、デビッド・フィッシャー氏です。そこから、急速に事が動き出しました。mypy の普及に直接の障害となっていたのはパフォーマンスでした。上記のとおり、初期の目標は mypy 実装を C にコンパイルすることでしたが、このアイデアはいったん取り消しました。私たちは mypy のようなツールではあまり高速ではない CPython インタプリタでの実行で行き詰まっていました。(JIT コンパイラによる代替の Python 実装、PyPy も役に立ちませんでした。)
幸いにも、アルゴリズムの改善がありました。実装した最初の大きな高速化は、増分チェックでした。アイデアはシンプルです。モジュールのすべての依存関係が前回の mypy 実行から変更されていなければ、前回の実行からキャッシュされたデータを依存関係に使用でき、変更されたファイルとそれらの依存関係の型チェックをするだけでよいというものです。mypy はそれよりもさらに進んでいます。モジュールの外部インターフェースが変更されていなければ、モジュールをインポートする他のモジュールを再チェックする必要がないことが mypy でわかるのです。
増分チェックは、既存コードに一括でアノテーションを付けるときに非常に役立ちます。これは通常、型が徐々に挿入され洗練されるにつれて、何度も mypy を繰り返し実行しなければならなくなるためです。ただ、最初の mypy の実行は多くの依存関係の処理が必要なため、かなり時間がかかっていました。これを補うために、リモート キャッシュを実装しました。ローカル キャッシュが古くなっている可能性があることが mypy で検出されると、mypy は、コードベース全体の最新のキャッシュ スナップショットを一元化されたリポジトリからダウンロードします。次に、ダウンロードしたキャッシュ上で増分ビルドを実行します。これで、パフォーマンスがさらに向上しました。
Dropbox ではこの期間、採用が自然かつ急速に進み、2016 年末までには型アノテーション付き Python は約 42 万行に達しました。多くのユーザーは、型チェックに熱心でした。mypy の使用が Dropbox のチーム間で急速に広がりました。
事はうまく運んでいるように見えましたが、やるべきことはまだたくさんありました。定期的な社内ユーザー調査を開始して問題点を見つけることにし、優先する作業を把握しました(これは今でも続いている習慣です)。2 つの要望が明らかに上位にありました。型チェック カバレッジの拡大と、mypy 実行の高速化です。パフォーマンス向上と導入拡大作業が完了していないのは明らかだったので、これらのタスクに注力することにしました。
5. パフォーマンスの向上
増分ビルドにより、mypy は速くはなりましたが、依然としてそれほど高速とはいえず、多くの増分実行の所要時間は約 1 分でした。大規模な Python コードベースで作業した経験のある人にとっては驚くことではないと思いますが、
原因は循環インポートです。互いにそれぞれ間接的にインポートする数百モジュールのセットがありますが、インポート サイクル内のいずれかのファイルが変更されると、mypy は、サイクル内のファイルをすべて処理する必要があります。多くの場合、このサイクルからモジュールをインポートしたモジュールも処理しなければなりません。こうしたサイクルの 1 つに、Dropbox で「もつれ」として問題となったサイクルがありました。一時期は数百のモジュールが含まれ、多くのテストや製品機能が直接または間接的にインポートしていたというサイクルです。
私たちは、もつれた依存関係を解消することを検討しましたが、そうするためのリソースがありませんでした。よくわからないコードが多すぎたのです。
そこで、別のアプローチを思い付きました。もつれが解消されていない状態でも mypy が高速に実行される方法です。それは、mypy デーモンを使うことでした。デーモンは、次の 2 つを特徴としたサーバー プロセスです。1 つ目は、コードベース全体に関する情報をメモリに保持するため、mypy を実行するたびに、数千のインポート依存関係に対応するキャッシュ データをロードする必要がないことです。2 つ目は、関数と他の構成概念の間のきめ細かい依存関係を追跡することです。たとえば、関数 「foo」 が関数 「bar」 を呼び出す場合、「bar」 から 「foo」 への依存関係があります。ファイルが変更されると、デーモンはまず、変更されたファイルのみを分離して処理します。次に、変更された関数シグネチャなど、そのファイルの外部から見える変更を探します。
デーモンは、きめ細かい依存関係を使用して、変更された関数を実際に使用している関数のみを再チェックします。通常、この数は少数です。
元の実装では、一度にファイルを処理することに重点を置いていたため、これをすべて実装することは困難でした。クラスが新しいベース クラスを取得したときなど、多くの変更があって再処理が必要となるものに関する多くのエッジ ケースにも対処しなければなりませんでした。たくさんの苦労を重ね、細かい点を突き詰めた結果、ほとんどの増分実行を数秒にまで短縮することができました。これは、まさに大勝利といった気分でした。
6. さらなるパフォーマンスの向上を目指して
前述のリモート キャッシングと合わせて、mypy デーモンは、エンジニアが少数のファイルの変更を繰り返すという増分ユース ケースをほぼ解決しました。とはいえ、最悪のケースのパフォーマンスは、依然としてベストと呼ぶにはほど遠いものでした。クリーンな mypy ビルドを実行するには 15 分以上かかり、満足にはほど遠かったのです。エンジニアは、新しいコードを作成し、既存コードに型アノテーションを追加し続けたため、この状況は週を追うごとに悪化していきました。しかし、ユーザーは依然としてパフォーマンスの向上を切望していたので、私たちもその思いに応えることに喜びを感じていました。
私たちは、mypy の背景にある初期のアイデアの 1 つである、Python を C にコンパイルするというやり方に戻ることにしました。Cython(C コンパイラに対する既存の Python)を用いた実験では、目に見えるスピードアップは得られなかったため、独自のコンパイラを作成するというアイデアを復活させることにしました。mypy コードベース(Python で記述したもの)は、すでに完全に型アノテーションが付けられているため、これらの型アノテーションを使用して処理を高速化する価値があるように思いました。そこで、さまざまなマイクロ ベンチマークで、10 倍以上のパフォーマンス向上を実現する高速の概念実証プロトタイプを実装しました。狙いは、Python モジュールを CPython C 拡張モジュールにコンパイルし、型アノテーションをランタイム型チェックに変換することでした(通常、型アノテーションは型チェッカーによって使用されるだけで、実行時は無視されます)。私たちは mypy 実装を Python から本物の静的型付け言語に移行する効果的な計画を立てていました。これは偶然ながら、見た目は Python とそっくりで動作もほとんど同じです。(この種の言語間移行は習慣になりつつありました。mypy 実装は、もともと Alore で書かれ、後にカスタム Java/Python シンタックス ハイブリッドで書かれました。)
CPython 拡張 API をターゲットにすることが、プロジェクトの範囲を管理しやすくしておくための鍵でした。mypy に必要な VM やライブラリを実装する必要はありませんでした。また、Python のエコシステムやツール(pytest など)はすべて引き続き利用でき、開発中はインタプリタの Python を引き続き使用できたため、コンパイルを待つことなく非常に高速な編集テスト サイクルが可能となりました。これは、まさに一挙両得で、とても気に入っていました。
型解析を実行するためのフロント エンドとして mypy が使用されるため mypyc と呼ぶコンパイラがありますが、これは大成功でした。全体として、キャッシュなしでクリーンな mypy 実行を約 4 倍高速化できたのです。mypyc プロジェクトの中核は、マイケル・サリバン氏、イワン・レフキフスキー氏、ヒュー・ハン氏、および私を含む小さなチームで約 4 か月かかりました。これは、たとえば C ++ や Go で mypy を書き換えるのにかかった作業よりもはるかに少なく、破壊的でもありませんでした。また、私たちは Dropbox エンジニアがコードのコンパイルおよび高速化のために最終的に mypyc を利用できるようにしたいと考えています。
このレベルのパフォーマンスに到達するには、いくつかの興味深いパフォーマンス エンジニアリングが必要でした。コンパイラは、高速で低レベルの C 構造を使用することで、多くの操作を高速化できます。たとえば、コンパイルされた関数呼び出しは、C 関数呼び出しに変換されます。これは、インタプリタでの関数呼び出しよりもはるかに高速です。辞書検索などの一部の操作は、一般的な CPython C API 呼び出しにフォール バックしますが、コンパイル時にわずかに高速になります。解釈用オーバーヘッドを取り除くことはできますが、それによるこれら操作速度の向上はわずかです。
これらの「遅い操作」のうち最も頻度の高いものを見つけるため、プロファイリングを行いました。このデータを用意し、mypyc を微調整してこれらの操作のための高速な C コードを生成することや、高速な操作を使用して関連する Python コードを書き換える試みをしました(時には簡単にできないものもありました)。後者は、多くの場合、コンパイラで同一変換を自動的に実装するよりもはるかに簡単でした。長期的には、これらの変換の多くを自動化したいと考えていますが、この時点では、最小限の労力で mypy を高速化することに注力し、時にはいくつか工程を省くこともありました。
7. ついに 400 万行に到達
もう 1 つの重要な課題(そして mypy ユーザー調査で 2 番目に寄せられた要望)は、Dropbox での型チェック カバレッジの拡大でした。それを達成するため、有機的な成長から、mypy チームの人的介入による集中的な取り組み、静的および動的自動型推論といったアプローチまでいくつか試みました。結局のところ、ここにはシンプルな必勝法はないように見えますが、多くのアプローチを組み合わせることで、コードベースのアノテーションを急速に成長させることができました。
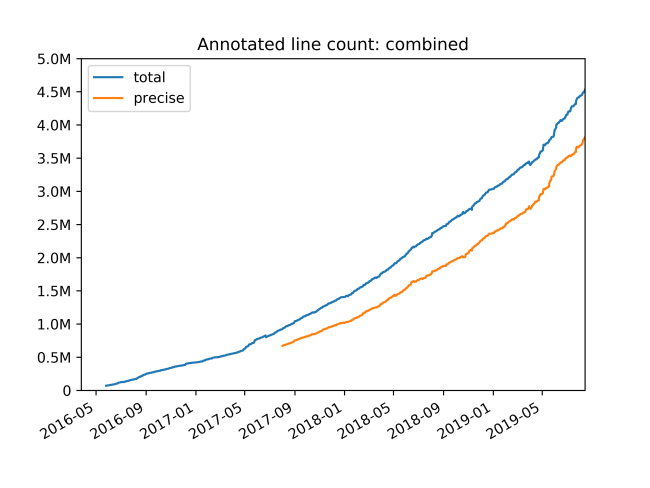
その結果、最大の Python リポジトリ(バックエンド コード用)内のアノテーション付きの行数は、約 3 年で約 400 万行の静的型付けコードまで成長しました。mypy は、さまざまな種類のカバレッジ レポートをサポートするようになり、進捗状況の追跡が容易になりました。特に、明示的で未チェックの 「Any」 型をアノテーションで使用することや、型アノテーションのないサード パーティ ライブラリをインポートすることなど、ソースでの型の不正確さが報告されるようにしました。Dropbox で型チェックの精度を向上させる取り組みの一環として、一元化された Python typeshed リポジトリに対する一部の一般的なオープンソース ライブラリ用の型定義(別名スタブ ファイル)の改善にも貢献しました。
また私たちは、特定の慣用的な Python パターンに対する、より厳密な型を可能にする新しい型システム機能を実装(およびその後の PEP での標準化)しました。注目すべき例は、「TypedDict」 です。これにより、それぞれが個別の値型を持った一定の文字列キーを持つ JSON 型辞書用の型が使用できるようになります。今後も、型システムを継続して拡張していきますが、次の 1 歩はおそらく、Python 数値スタックのサポートを強化することになるでしょう。

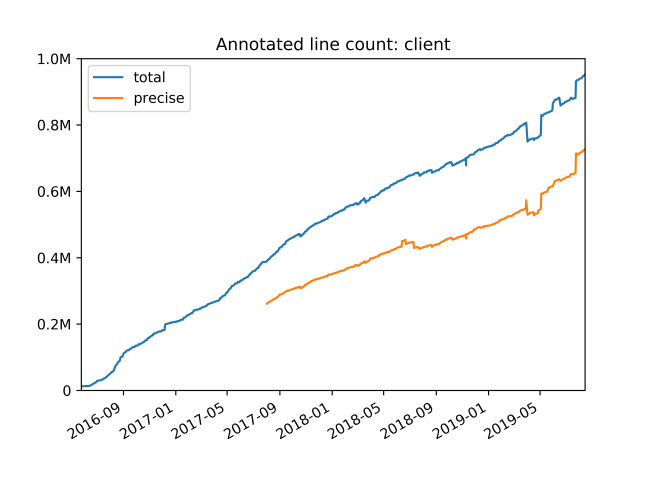
Dropbox でアノテーションのカバレッジを拡大するために行った取り組みの概要は、以下のとおりです。
厳密性
新しいコードに対する厳密性要件を徐々に増やしました。まず、すでにいくつかアノテーションが存在するファイルにアノテーションを記述するようアドバイスする lint ツール(リンター)から着手しました。現在では、新しい Python ファイルやほとんどの既存ファイルで、型アノテーションを必須としています。
カバレッジ レポート
毎週、レポートをチームにメールし、アノテーションのカバレッジに焦点を当て、アノテーション付けの優先順位が最も高いものを提示します。
周知活動
mypy について講演し、mypy を使い始められるようにチームと話し合いました。
調査
定期的なユーザー調査を実施して重要な問題点を見つけ、それらの対処に多くの時間をかけています(mypy をさらに高速化するための新しい言語を考案するまでの間)。
パフォーマンス
mypy デーモンや mypyc(p75 を 44 倍も高速化)を使用して mypy のパフォーマンスを向上させ、アノテーション ワークフローの干渉を減らし、型チェックされたコードベースのサイズを拡大縮小できるようにしました。
エディタの統合
mypy を実行するために、PyCharm、Vim、VS Code など、Dropbox で広く使用されているエディタを統合しました。これにより、レガシー コードにアノテーションを付けるときに、何度も繰り返しアノテーションを記述するという作業がはるかに楽になります。
静的解析
静的解析を使用して関数のシグネチャを推測するツールを作成しました。このツールは、非常に単純なケースにしか対応できませんが、あまり手間をかけずにカバレッジを増やすことができました。
サードパーティ ライブラリのサポート
多くのコードは、SQLAlchemy を使用しています。SQLAlchemy は、PEP 484 型では直接モデル化できない動的な Python 機能を使用しています。私たちは PEP 561 スタブ ファイル パッケージを作成し、それを適切にサポートするために mypy プラグインを作成しました(オープン ソースとして入手可能です)。
8. 実現までの課題
400 万行に到達するのは必ずしも簡単なことではなく、いくつかの問題が発生し、途中でミスをすることもありました。ここで、他の人が同じミスを繰り返さないよう、私たちの失敗例をいくつかご紹介します。
ファイルの不足
mypy ビルドでは、ごく少数のファイルから始めました。ビルド外のチェックは全く実施されず、最初のアノテーションが追加されたときにファイルがビルドに暗黙的に追加されました。ビルド外のモジュールからインポートすると、「Any」 型を持った値を取得しますが、これらはまったくチェックされません。これにより、特に移行の初期に、型付け精度が大幅に低下しました。ビルドにファイルを追加するとコードベースの他の部分の問題が明らかになるという典型的な例にも関わらず、不思議とうまく機能していました。最悪の場合、型チェックされたコードの 2 つの孤立した島がマージされ、2 つの島の間で型の互換性がなくなり、アノテーションに数えきれないほどの変更が必要であることが判明したのです。振り返ってみると、物事をもっと円滑にするために、もっと早く mypy ビルドに基本ライブラリ モジュールを追加すべきでした。
レガシーコードへのアノテーション付け
開始時には、既存の Python コードは 400 万行を超えていましたが、これらすべてにアノテーションを付けるのは簡単ではないことは明らかでした。テスト時に実行時の型を収集し、これらの型に基づいて型アノテーションを挿入できる PyAnnotate というツールを実装しましたが、これはあまり浸透していませんでした。型の収集が遅く、生成された型は、多くの場合、人手による調整が必要でした。すべてのテスト ビルドで自動的に実行するか、動作中のネットワークのリクエストから小規模に部分的な型を収集することを検討しましたが、どちらのアプローチもリスクが高いため、行わないことにしました。
最終的に、コードのほとんどは、コード所有者によって手動でアノテーション付けされました。私たちはプロセスを合理化するために、アノテーションを付ける価値が最も高いモジュールや関数のレポートを提供しています。アノテーション付けは、数多くの場所で使用されるライブラリ モジュールには重要ですが、置き換え予定のレガシー サービスにはそうでもありません。また、レガシー コードの型アノテーションを生成するために、静的解析を使用した実験も行っています。
インポート サイクル
先ほど、インポート サイクル(「もつれ」)により mypy の高速化が困難であったと述べましたが、インポート サイクルから生じるあらゆる種類のイディオムを mypy でサポートできるようにする必要もありました。最近やっと、ほとんどのインポート サイクルの問題を修正する重要な再設計プロジェクトを完了しました。実は問題は、mypy が最初に対象とした研究言語である Alore のごく初期に端を発します。Alore にはインポート サイクルを簡単に処理する構文があり、単純な実装からいくつかの制限を引き継ぎました(Alore では問題ありませんでした)。Python ではステートメントに複数の意味を持つことがあるため、インポート サイクルの処理は容易ではなくなります。割り当てにより、実際にたとえば、型エイリアスが定義される場合があります。mypy は、ほとんどのインポート サイクルの処理が完了するまでに、常にそれを検出できるわけではありません。Alore には、この種のあいまいさはありませんでした。初期の設計上の決定によって、何年も経った今でも苦労することがあるのです。
9. 次なる目標は 500 万行以上
初期のプロトタイプから本番環境の 400 万行の型チェックまでには、長い道のりがありました。この過程では、Python で型ヒントを標準化し、今では、型ヒントに対する IDE やエディタのサポート、長短の異なる複数の型チェッカー、ライブラリ サポートにより、Python 型チェックを取り巻くエコシステムは急成長しています。
型チェックは、Dropbox ではすでに当たり前のことと考えられていますが、依然としてコミュニティでの Python 型チェックは初期段階にあり、今後もさまざまな改良が加えられていくことと思います。もし、あなたが大規模な Python プロジェクトでまだ型チェックを使用していないのなら、今こそ始めるときです。私がこれまで出会った中で、型チェックの導入に踏み切ったことを後悔している人はひとりもいません。大規模なプロジェクトにとって、Python が今よりずっと優れた言語になることは間違いないのですから。