Dropbox の同期エンジンのコードを完全に書き換えるのは、困難な道のりでした(その目標と決断までの詳細については、以前の投稿をご覧ください)。コードの書き換えとは、運用中に膨大な数のユーザーのマシンで稼働している Dropbox を支えるエンジンを入れ替えることです。正しくコードを書き換えるには、テストの自動化に本腰を入れる必要がありました。私たちが策定したテスト戦略のおかげで、コードを書き換えている間、いつでも正しい方向に向かっていると確信が持てました。このおかげで現在も、短いリリース周期で新機能の開発と出荷を続けることができます。
ここでは、最初に新しい同期エンジン「Nucleus」の設計に反映したテスタビリティの検討事項と、テストしやすいアーキテクチャ上に構築したランダム化テスト システムの一部について説明していきます。
目次
-
- テスタビリティ
1-1. プロトコルとデータ モデル
1-2. 同時並列モデル - ランダム化テスト
- CanopyCheck
3-1. Planner
3-2. 初期化
3-3. 実行時
3-4. 不変条件
3-5. 最小化 - Trinity
4-1. モッキング
4-2. 同時並列性のシミュレーション
4-3. 制限
- テスタビリティ
1. テスタビリティ
コードの書き換えに着手したときに、1 つ明確だったのは、確固としたテスト戦略を立案するには、新しいシステムのテストが容易でなければならないということでした。関連するテスト フレームワークを導入していない早い段階からテスタビリティを重視することは、適切にアーキテクチャを構築するうえで不可欠でした。ところで、テスタビリティとは何を意味するのでしょうか。
それを知るには、レガシー システムである Sync Engine Classic について考えてみるとよいでしょう。この古いシステムのテストが困難だった理由、このシステムでリグレッションの発生の抑制と正確性の維持が困難だった原因、また、新しいシステムのアーキテクチャを構築する際に活かせる教訓とは、どのようなことだったのでしょうか。
1-1. プロトコルとデータ モデル
その答えの 1 つは、Sync Engine Classic のサーバー – クライアント プロトコルとデータ モデルは、今よりも単純な時代に、まだシンプルだった機能に対して設計されたことです。当時 Dropbox には共有やコメント、注釈の機能はなく、千人規模の企業チームで Dropbox が使用されることもありませんでした。Dropbox は、最初のシステムを開発してから 12 年あまりで急激に進化し、製品に対する要求も大きく変わりました。
Sync Engine Classic のクライアント – サーバー プロトコルでは、多くの場合、可能な同期状態の組み合わせが寛容すぎるために、テストを効率よく実行できませんでした。 たとえば、クライアントは「/baz」で親ディレクトリを受信する前に、「/baz/cat」にあるファイルに関するメタデータをサーバーから受信できます。これに合わせて、クライアントのローカル データベース(SQLite)は、この孤立した状態を表す必要があり、また、ファイルシステムのメタデータを処理したコンポーネントも、この孤立した状態を表す必要があります。その結果、さまざまなタイプの重大な不一致(孤立したファイルなど)なのか、クライアントが取りうる一時的な状態なのかを区別できないことになります。
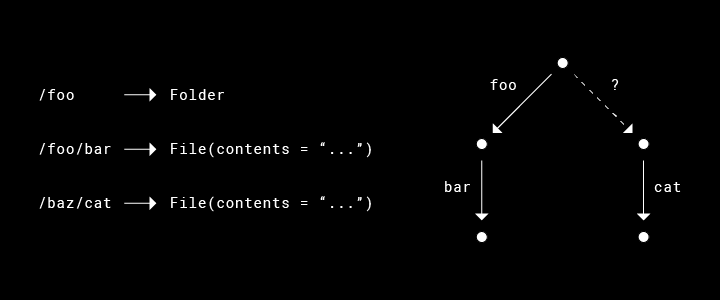
Nucleus では、初めからプロトコルによって、この状態に陥らないようにします。実際、私たちの中核となるアーキテクチャ原則の 1 つに「無効なシステム状態を排除する設計」があります(今後の投稿で、Rust タイプのシステムを活用してこの原則を実現する方法について説明します)。このように孤立した場合、クライアントがこの状態に陥る前に、プロトコル レベルで重大なエラーをレポートします。永続化されたデータ モデルと高レベルのコンポーネントでは、このような可能性を考慮する必要はありません。これらはより厳格なため、テストしやすい新しい不変条件を使用できます。データベースには(一時的であっても)親ディレクトリがないファイルとフォルダは存在することができません。
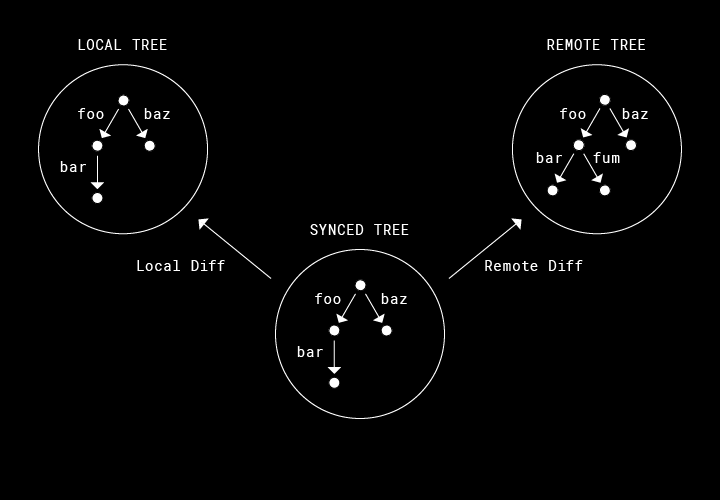
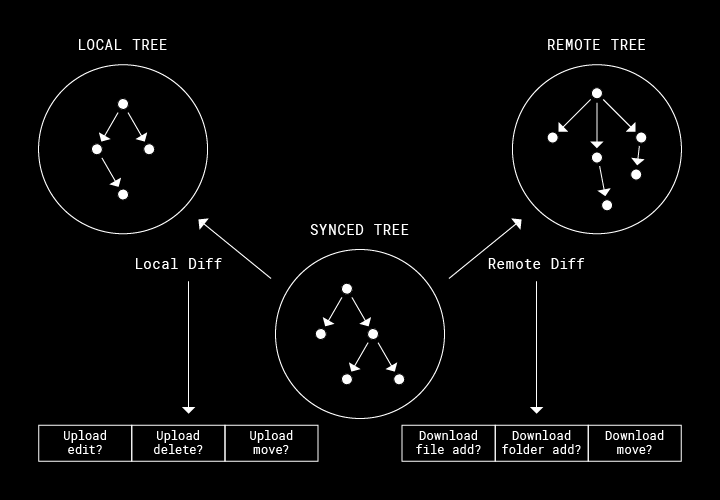
Sync Engine Classic と Nucleus では、データ モデルが基本的に大きく異なります。前者のレガシー システムは、各ファイルまたはフォルダをディスクに同期するために、未処理の作業を持続する必要がありました。たとえば、任意のファイルをローカルに作成する必要があるか、またはサーバーにアップロードする必要があるかについて情報を格納します。一方、Nucleus では観察を持続します。未処理の同期アクティビティをそのまま表すのではなく、3 つのツリーのみを維持します。以下のように、それぞれのツリーが、一貫性のあるファイルシステムの状態を表し、その状態から適切な同期処理を導き出します。
- リモート ツリーは、クラウドにあるユーザーの Dropbox の最新状態。
- ローカル ツリーは、ディスクにあるユーザーの Dropbox の観察された最新状態。
- 同期済みツリーは、リモート ツリーとローカル ツリー間で、直近に認識された「完全に同期済み」の状態を表現。
[Sync Engine Classic のデータ モデル]
[Nucleus データ モデル]
この同期済みツリーは、明確に正しい同期結果を導き出すことができる重要なイノベーションです。バージョン管理に例えるなら、同期済みツリーの各ノードはマージ ベースにあたります。マージ ベースによって、変更の方向を導き出すことができます。つまり、「ユーザーはローカルのファイルを編集したのか、それとも dropbox.com のファイルを編集したのか」の答えがわかります。上の図では、パス「/foo/fum」のファイルがリモートで追加されていることが分かります。その理由は、ローカル ツリー(ディスク上)が、同期済みツリーによって表されているマージ ベースと一致するためです。この同期済みツリーがなければ、この状態を、ユーザーが実際にローカルで「/foo/fum」を削除した場合と区別することはできないでしょう。
私たちがこのデータ モデルを採用したのは、このモデルが極めてテストしやすいからです。このデータ モデルでは、システムの主要な目的を簡単に表現できます。つまり、3 つのツリーがすべて同じ状態に収束するということです。ユーザーのローカル ディスクが dropbox.com と同じ状態(ローカル ツリーがリモート ツリーと一致する状態)であれば、同期は完了しています。このモデルでは、厳格な不変条件を適用できます。たとえば、テストの開始時に 3 つのツリーがどのような設定であっても、すべて収束する必要がある、といった条件を適用できます。
Nucleus データ モデルでは、ノードは一意の識別子によって表されます。この点は、フル パスでノードをキー化していた Sync Engine Classic とは大きく異なります。そのため、このレガシー システムのデータベースでは、ファイル名の変更は、元のパスでの削除と宛先での追加として表現されます。つまり、フォルダの場合、1 回の移動は、すべての子孫に対する O(n) 回の削除と追加に分割されます。そのため、ディスク上では、連続した削除と追加が何度も実行されます。1 つのディレクトリの子孫すべてに対して(1 度に 1 回ずつ)削除と追加が実行されるまで、ユーザーには一貫性のない 2 つのツリーが表示されます。
システムとしては、Nucleus のほうが厳格です。ノードは一意の識別子を使用して表されるため、移動はデータベース内の移動対象となるノードの属性に対する更新にすぎません。この更新は、単一の原始的な移動によってファイルシステムに複製され、テストで適用される追加の不変条件を提供します。つまり、移動されたフォルダは、どれも 1 か所でのみ表示されるという条件です。
1-2. 同時並列モデル
Sync Engine Classic は、同時並列モデルであるため、テストは極めて困難でした。これは、次回正しく対処しようと決意していた領域の 1 つでした。
Sync Engine Classic では、コンポーネントは内部で自由にスレッドを分岐することができました。つまり、実行命令に関しては、基盤となる OS に従うのみでした。コンポーネント間の調整は、グローバルなロックを介して実行されていました。タイムアウトとバックオフはハードコードされていて、 想像通り、テストの信頼性は低く、デバッグは煩雑な作業となることがよくありました。このようなテスタビリティの欠点に対処するために、多くの場合、テストでは、ランダムな時間休止するか、半強制的なパッチの適用とモッキングを行うことで実行を手動で直列化しました。
Nucleus では、できるだけ労力の少ない、予測可能な方法でテストを作成できることを目指しました。ほぼすべてのコードが、単一の「制御」スレッドで実行されます。同時並列性のメリットを利用する処理(ネットワーク I/O、ファイルシステム I/O、ハッシュ化のような CPU 負荷の大きい処理)は、専用のスレッドまたはスレッド プールにオフロードされます。テストに関しては、システム全体を直列化できます。非同期のリクエストは直列化して、バックグラウンドのスレッドではなくメイン スレッドで実行できます。これで、煩雑なテストは不要となりました。この単一スレッドの設計は、ランダム化テスト システムの決定性と再現性の鍵となっています。
2. ランダム化テスト
ランダム化テストは、私たちのテスト戦略で最も重要な部分です。どの複雑なシステムでも、基本となるケースをすべてカバーしたかと思うと、基本から外れた別のケースが見つかります。それも、次から次へと見つかります。Dropbox は膨大な数のユーザーのマシンで稼働しており、それぞれの環境は大きく異なります。新しくチームに参加したエンジニアによく話すのは、最も目立たないケースであっても、いずれは姿を現すということです。通常の単体テストと統合テスト、および手動によるテストでは、そのようなケースを削るわけにはいきません。というのも、事前にまれなケースを予測できるほど人間は賢くないからです。ランダム化テストは、私たちのシステムが本当の意味で堅牢であるという確信を与えてくれます。
皆さんは、過去の経験から、「ランダム化テスト」という言葉に良い印象を持たないかもしれません。ランダム化テストの多くは、大きな不満をもたらしています。エラーは断続的にしか発生せず、しかも再現不可能だからです。エラーが簡単に再現できなければ、診断用にログやブレークポイントを追加することもできません。実際、Sync Engine Classic には、このようなシステムがいくつも組み込まれていました。何時間もランダム化テストのログを詳細に調査しましたが、本当に必要としていたログはなく、そのためさらなる調査が妨げられていました。そこで、Nucleus では、私たちが望む範囲を単にカバーできるのではなく、労力の少ない方法でカバーできるランダム化テスト システムを構築するよう決意しました。開発者の生産性の向上は、最優先の課題でした。この目的のために、私たちは次の厳しい要件を自らに課しました。その要件とは、すべてのランダム化テスト フレームワークは、十分な決定性を備え、容易に再現できなければならないということです。
目的とする決定性を実現するために、すべてのランダム化テストは、以下の構成をとります。
1. ランダム化テストの実行開始時に、ランダム シードを生成する。
2. 生成したシードで、疑似乱数ジェネレーター(PRNG)をインスタンス化する(個人的には、その名前からこの PRNG が気に入っています)。
3. すべてのランダムな判断については PRNG を使用して、テストを実行する。たとえば、初期のファイルシステムの状態の生成、タスクのスケジュール設定の生成、またはネットワーク エラーの挿入を行う。
4. テストが失敗する場合は、シードを出力する。
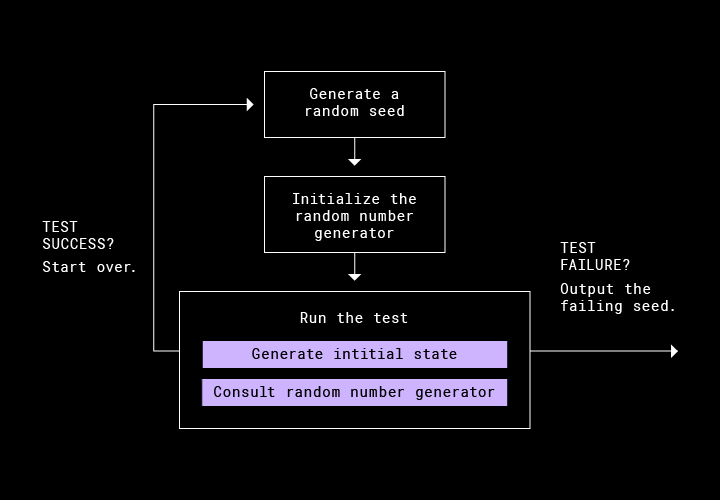
毎晩、私たちは膨大な数のランダム化テストを実行しています。最新のマスターでは、テストが 100 % 合格するのが一般的です。知らぬ間にリグレッションが入り込んでいた場合は、CI はエラーが発生しているシードごとに自動的に追跡タスクを作成します。これには、その時点で最新のコミットのハッシュも含まれます。テスト実行時に発生した現象を理解するために詳細なログが必要な場合、エンジニアはインラインにログを追加し、ローカルでテストを再実行できます。これで、確実に再度エラーが発生します。
このように確実にエラーが発生する状態を維持するために、私たちは、修正した PRNG を入力し、細心の注意を払って Nucleus 自体に十分な決定性を持たせました。たとえば、Rust のデフォルトの HashMap は、内部でランダム化したハッシュ化アルゴリズムを使用し、ハッシュの衝突を強制的に引き起こすことができるサービス拒否攻撃に耐えます。ただし、Nucleus には衝突耐性は必要ありません。敵対者はこのような攻撃で自分自身のパフォーマンスを低下させてしまうからです。よって、すべての動作が再現可能となるよう、私たちは、決定性の高いハッシャーでこの動作を無効にします。シードと並ぶ別のタイプの「テスト入力」として、コミット ハッシュも重要です。コードが変更されると、実行の過程も変わる場合があります。
この記事では、Nucleus を保護する 2 つのランダム化テスト システムについて説明します。1 つは CanopyCheck で、上で述べた 3 つのツリーを同期する機能をテストします。もう 1 つは Trinity で、エンジンの全体的な同時並列性をテストします。
3. CanopyCheck
ランダム化テストを、エンドツーエンドですべて実行する必要はありません。特定のコンポーネントを実行するために、狭い範囲に対応したランダム化テストを構築すると、カバレッジが広がるだけでなく、強力な不変条件をアサートすることもできます。CanopyCheck は、Planner のバグ発見専用のシステムです。
3-1. Planner
Planner は、Dropbox における同期を支えるアルゴリズムです。入力には、Nucleus のデータ モデルのコアである 3 つのツリーを使用します。これらをまとめて「Canopy」と呼びます。先に説明したように、この 3 つのツリーは、サーバー上にあるユーザーの Dropbox の現在の状態、ディスク上にあるユーザーの Dropbox の現在の状態、これまでに実行された同期の進行状況を表すマージ ベースを表します。Planner のジョブは、これらのツリーが段階的に収束していくのに必要な一連の処理を出力します。たとえば、「ディスク上にこのフォルダを作成」、「このファイルへの編集をサーバーにコミット」のような出力になります。Planner ではこれらの処理をバッチとしてグループに束ねて、同時に安全に実行します。たとえば、Planner は、ファイルはその親ディレクトリが作成された後でなければ作成できないが、同時に 2 つの兄弟ファイルを編集または削除しても差し支えないことを認識します。
この計画アルゴリズムを正しくすることが不可欠です。以下の例は、Planner 用に手動で作成した基本的な単体テストです。この例では、テストに労力がかからないよう、Rust のマクロ システムを多用していることもわかります。内部では、「planner_test!」マクロがツリーを初期化し、Planner に従って処理を生成します。引き続き各処理の結果を反映するようツリーを更新し、表示されている最終的な等価プロパティと一部の内部一貫性プロパティをアサートします。

注:上のテストでは、Planner が適切な計画を発行してリモートで追加されたノードをダウンロードすることが確認されます。
おわかりかもしれませんが、私たちはこのようなテストを数百個用意し、3 つのツリーをさまざまな設定に組み込んで、Planner が決定する最終状態が受け入れ可能であることをアサートしています。ただし、小さなツリーに制限したとしても、考えられる重要な一意のツリー設定は、数え切れないほどあります。では、どのようにすれば、考えられるすべての入力を Planner が適切に処理することに確信を持てるでしょうか。それには、CanopyCheck を使用します。
3-2. 初期化
CanopyCheck は、上のような例のテスト ケースを生成するテスト フレームワークです。「初期」ツリーをランダムに生成し、プログラムによって何らかの「最終」ツリー構造のサブセットを推測します。
ランダムな入力の生成は、簡単ではありません。3 つのツリーを個別に生成すると、関心のあるシナリオの実行に失敗するでしょう。つまり、3 つのツリーで、重複しないパスに、共通性のないファイルのセットがある場合、Planner は削除、編集、移動などのロジックをまったく実行しません。代わりに、私たちは最初に 1 つのツリーをランダムに生成し、その後そのツリーにランダムに摂動を加え、他の 2 つのツリーを生成します。こちらの方法のほうが、考えられるすべての同期のケースを大まかに調査できます。同時に、個別のファイルに対するランダム化テストのカバレッジも向上します。
3 つのツリーをランダムに生成したら、計画を開始できます。
3-3. 実行時
CanopyCheck による任意のランダム化テストの実行ループは、以下のようになります。
1. Planner に同時並列処理のバッチを要求する。
2. ランダムに処理のセットを入れ替える(順序が重要ではないことを確認するため)。
3. 各処理では、計画に沿って、更新に先立つ処理を擬似的に実行する。
4. Planner から、これ以上処理がないと通知されるまで繰り返す。
手順 3 では、CanopyCheck は同期プロセスを進めますが、要求された処理を実際には実行しません。つまり、コンポーネントのモッキングや同時並列性の考慮は不要になります。計画どおりにすべてうまくいくと、このループが一定の限られた回数繰り返された後、3 つのツリーがすべて収束して、同期が完了します。
3-4. 不変条件
このフレームワークは I/O または同時並列性など、Nucleus の重要な機能を使用しないため簡単に思えますが、それでも非常に強力です。CanopyCheck を使用すれば、あらゆる種類の不変条件を確認できます。
終了
同期は増分処理です。最初に、処理のバッチを 1 つ実行し、その後に別のバッチを実行します。これを、同期するまで繰り返します。ところで、どのようにして、同期が終了したことがわかるのでしょうか。また、誤ってループすることや、無限に同期することを防ぐには、どうすればよいでしょうか。CanopyCheck では、どんなに入力が不自然または人為的であっても、Planner が無限ループを作成しないことを確認します(経験則により、計画の繰り返しは約 200 回で打ち切られます)。
混乱を引き起こさない
Planner (および Nucleus 全般)では自由に「assert!」し、可能な限り、予防的にすることができます。CanopyCheck では、早期に、総合的にこのようなアサートをカバーし、実行時に混乱を引き起こさないようにします。
Nucleus の開発の早い段階で、このことだけでも大量のバグが検出され、設計上の誤った仮定が浮き彫りとなって、計画からやり直さざるを得なくなりました。実際に、以前のブログ投稿で説明した「Archives/Drafts/January」ディレクトリが循環するバグを発見できたのは CanopyCheck のおかげでした。CanopyCheck によって、ローカルの移動とリモートの移動を一緒に適用すると循環が作成されるという条件を見つけることができました。その後、シードがデータ構造内でアサーション エラーをトリガーし、テストを不合格にしました。
同期の正確性
私たちは、テスト実行の終了時に 3 つのツリーがすべて同じになることを定めました。これが同期の定義です。ただし、この定義だけですと、非常に極端なバグに対しては脆弱です。たとえば、Planner が常に dropbox.com とユーザーのディスクにあるファイルをすべて削除してしまう場合を考えてみましょう。どのような入力であっても、3 つの空のツリーが作成されますが、それでもテストは合格します。そのため、3 つのツリーをすべて収束するだけでなく、正確性に関する追加の不変条件を多数適用します。これらはランダム化テストなので、すべてのケースで適用できるよう不変条件をシンプルにしつつ、かつ矛盾がないよう攻撃的にしなければなりません。通常、この 3 つのツリーのプロパティの一部(理想的にはシンプルなプロパティ)は初期化時に派生し、関連するプロパティはテストの終了時に適用されます。
たとえば、私たちが定めた不変条件の 1 つに次のものがあります。任意のファイルがリモート ツリーのみにあって他の 2 つのツリーにない場合(つまり、ファイルがサーバーにのみある場合)、テスト実行の終了時にそのファイルは 3 つのツリーすべてになければならないという条件です。直感的に、この条件では、サーバーに同期していないデータがあれば、同期によってユーザーのディスクにダウンロードされなければならないということがわかります。このデータを削除すればエラーになります。アップロードについても、対称性のあるローカルの不変条件を定めています。不変条件の別の例は、スマート シンクに関連します。ローカルで追加されたファイルは、「オンラインのみ」フォルダに移動されない限り、ダウンロードされたままであることを確認します。これにより、早まってローカル コンテンツがディスクから削除されることはありません。
3-5. 最小化
「CanopyCheck」という名前は、Haskell のテスト ライブラリである QuickCheck に関係しています。QuickCheck と同様、CanopyCheck は不合格となるテスト ケースを見つけ、次に複雑性を最小化した、エラーを再現する入力を探します。
このテストのシンプルな入力形式(上の 3 つのツリー)では、非常に自然な手法を使用して最小化することができます。たとえば、テスト ケースが、先に説明した正確性の不変条件のいくつかで不合格となるか、またはテスト ケースで実行される繰り返しが多すぎて、無限ループとなる場合を考えてみましょう。このテスト ケースを見つけると、CanopyCheck は、ノードの削除を繰り返すことで最小の入力を検索します。このことによって、ツリーの初期状態を縮小させ、エラーが引き続き発生するかどうかを確認します。
最初にランダムに生成される入力は、非常に複雑なことが多いため、このプロセスは開発者にとって極めて有益です。3 つのツリーで何十ものノードを追跡するのは、人間にとって簡単ではありません。人間の注意は多くの軽微なバグに向けられ、そこに紛れている本当のバグには気付かないからです。最小化は、人間の注意を集中させ、一目で診断できるようにします。たとえば、「リモートで削除された親ディレクトリにユーザーがノードを追加するケースに対応していない」ことに気付くようになります。
4. Trinity
CanopyCheck は計画アルゴリズムをテストするうえで大きな効果を発揮しますが、それ以外にも Nucleus にはテストでカバーする必要がある領域があります。ここで、必要になるのが Trinity です。
同期において最も扱いにくいバグは、わかりにくい競合条件によって引き起こされます。このようなバグは、特に問題を起こしやすいタイミングまたは順序と処理が重なるという、まれな状況でのみ発生します。以下はその例です。
- 共有フォルダで、Ada は自分のマシンにある foo を削除。
- Grace の同期エンジンは、foo を削除する必要があることを認識。
- 同時に、Grace は自分のパソコン上に新しいデータをいくつか書き込み。
- Grace の同期エンジンが誤って foo を削除し、最近の変更が失われる。
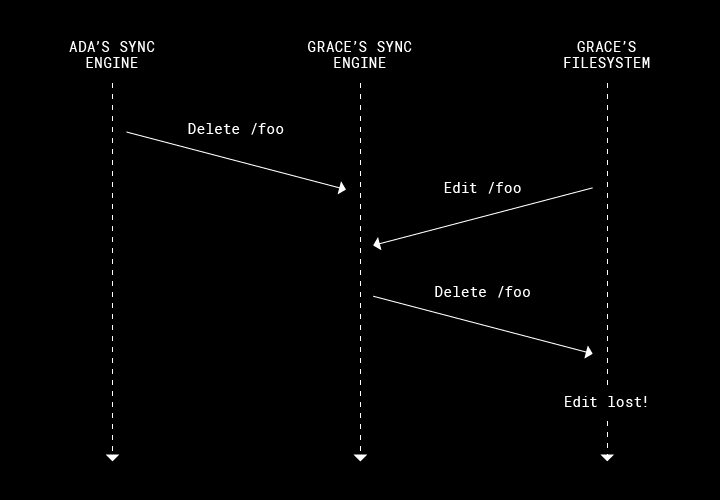
ユーザーが Dropbox と同期しようとしていたデータが失われることは、絶対に避けなければなりません。Trinity では、このような競合をユーザーに Dropbox を導入する前に発見できます(もちろん、これよりも複雑な競合も発見できます)。
初期化
実行の開始時に、Trinity はバックエンドの状態(dropbox.com にあるユーザーの Dropbox)とファイルシステムの状態(ディスク上の Dropbox フォルダ)を初期化します。ここでは、Nucleus のデータ モデルを直接初期化しないで、Nucleus が観測し、同期するシステムの外部状態を初期化することに注意してください。次に Trinity は Nucleus をインスタンス化します。これは、ユーザーが Dropbox デスクトップ クライアントを接続して、以前にディスク上に存在していた Dropbox フォルダを選択することに似ています。
実行
Trinity は交互に Nucleus のスケジュール設定とそれ自体のスケジュール設定をメイン スレッドで行います。Nucleus によって、Nucleus が同期済みの状態になったことがレポートされるまで、Trinity はシステムに対して頻繁に摂動を加えます。そのために、ローカルとリモートのファイルシステムの変更、Nucleus の非同期リクエストを捕らえて、レスポンスを並べ替え、ファイルシステム エラーとネットワーク エラーの挿入、クラッシュのシミュレーションを行います。
確認
Nucleus によって Nucleus が同期されたことがレポートされると、Trinity はシステムが一貫した状態にあることをアサートします。さらに、(同じシードで)同じテストを再実行し、同じ最終結果を再現することをアサートして、その決定性を確認します。
4-1. モッキング
Nucleus はコンパイル時の依存関係でパラメータ化され、初期化時に Trinity がファイルシステム、ネットワーク、およびタイマーのラッピングされたバージョンを渡せるようにします。Trinity はこれらのラッピングされた実装を使用して、非同期のリクエストを捕らえて、応答を直列化します。Trinity はリクエストを受け入れることを選択すると、基盤となる具体的な実装に対してリクエストを代理で送信します。
ファイルシステム
Trinity はネイティブのプラットフォーム ファイルシステムをインメモリのモックで置き換えます。このモックにより、Trinity はあらゆるファイルシステムの処理にエラーを挿入し、リクエストを並べ替え、任意の順序でリクエストを解決します。また、ファイルシステムの以前の状態のスナップショットを取得し、復元することでシステム クラッシュをシミュレートします。中でも最も重要なのは、インメモリのファイルシステムを使用することで、パフォーマンスを大幅に高速化できる点です。これにより、テスト実行の数は約 10 倍に増加できるため、より多くのランダムなテストを実施できます。
ネットワーク
メタデータ データベース、ファイル コンテンツ ストレージ、通知サービスなどのサーバー バックエンド全体が、Rust のモック用にスワップ アウトされるため、Trinity はランダムにサーバーに対する RPC を並べ替え、遅延させ、エラーを引き起こすことができます。モックは、Nucleus が利用する、サーバー側のすべてのサービスをエミュレートし、可能な限りプロダクション環境での動作を模倣します。
タイムアウト
Nucleus のコードベースでは、汎用的でモッキングが可能なタイマー オブジェクトを使用しています。たとえば、Nucleus がオンラインのみのプレースホルダをダウンロードするために、5 分間のタイムアウトを要求すると、Trinity はそのリクエストを傍受して、ランダムに時間を早送りし、不定期にタイムアウトを起動します。
4-2. 同時並列性のシミュレーション
このようにモッキングすることで、Trinity はシステムですべての非同期アクティビティに関与します。Trinity はメイン スレッドで Nucleus を稼働させ、モッキングされた各コンポーネントに対する数多くのリクエストを捕らえてしバッファに保存します。その後しばらくしてから、Nucleus は Trinity に制御を戻しますが、その時点で Trinity はこれらのリクエストを受け入れるかどうか、または(上の「実行」で説明したように)システムの外部状態に摂動を加えるよう独自にアクションをとるのかをランダムに選択します。
ここで、Trinity はどのようにしてメイン スレッドでそれ自体と Nucleus のスケジュールを設定するのでしょうか。Nucleus 自体は Rust の Future で、Trinity は本質的には、この Future を実行するカスタムの機能です。Trinity を使用すると、追加されているカスタムのロジックを追加して、Future の実行をインターリーブすることができます。Rust の Future について習熟されていない場合は、このセクションで詳細を調査する前に、こちらの優れた概要説明や最新の公式ドキュメントを参照しておいてください。
Future は、他の Future から構成されるため、Nucleus 自体を 1 つの巨大な Future と考えることができます。内部的には、数多くの他のワーカー Future から構成されています。これらの Future もさらに多くの Future から構成されていて、ツリー構造を作成しています。たとえば、「アップロード ワーカー」は、Dropbox サーバーにファイル コンテンツを転送する Future です。アップロード ワーカーは、内部的には、順序のない Future のセットを管理し、アップロード ワーカーが発行する同時並列のネットワーク リクエストを表します。
Rust の Future トレイトは、関数 poll() を介した実行を表します。この関数は、Future が処理を進めてから、その後処理を完了したどうかを返すようにします。Future が Poll::Ready(result) を返すと、出力 result で完了します。Future が Poll::Pending を返す場合は、子の Future のいずれかでその Future はブロックされており、子の Future のいずれかが処理を進めたときに、外部の機能が poll() を再度呼び出す必要があります。最上位の Nucleus Future には、impl Future
テスト中、Trinity は最上位の同期エンジン Future へのポーリングを行う外部の機能となります。そのメインの実行ループで、Trinity は交互に独自のコードを実行します。その際、Nucleus で poll() を呼び出し、すべてのモッキングされたファイルシステムと捕らえたネットワーク リクエストで poll() を呼び出します。1 つ以上の未処理のリクエストで Nucleus がブロックされると、Trinity は、成功または失敗させるリクエストをいくつか選択します(通常どおり PRNG によって進められます)。これは、プロダクション環境で Nucleus に要求される同時並列処理をシミュレートするだけでなく、まれな実行順序を発生させる可能性を高めます。
4-3. 制限
Trinity は、さまざまなコンポーネント間で内部から Nucleus への予期しないやり取りを検出するのに効果的ですが、決定性に欠ける多くの外部ソースをモッキングするには代償が伴います。
ネイティブ ファイルシステムのやり取り
ネイティブ プラットフォーム レイヤーは、権限の管理、ファイルの拡張属性の変更、スマート シンク プレースホルダへの入力などを行う OS 固有のロジックなどを含み、それ自体がかなり複雑になっています。Trinity をインメモリのファイルシステムのモックに対して実行すると、この領域をカバーできなくなります。コードベースのこのレイヤーを網羅するには、Trinity を「ネイティブ」モードでも実行して、プラットフォームの実際のファイルシステムをターゲットにします。ただし、ネイティブのファイルシステムに対して実行すると、パフォーマンスが大幅に低下します(約 10 分の 1)。つまり、ネイティブの Trinity ではテストに使用するシードの種類が少なくなります。
再現性を確保するために、Trinity ではネイティブ プラットフォーム API に対する呼び出しをすべて直列化し、システムコールをインターリーブする OS の決定性が低いという特徴を避けるようにしています。実際に、ユーザーは希望するときにシステム コールを実行できるため、このようなインターリーブが競合を引き起こす条件となる可能性は十分にあります。
最後の点として、プラットフォームの一部の動作には対応していません。Trinity は、実際にはテスト中にマシンを再起動することはできないため、すべての適切な場所で fsync を使用して、各プラットフォームでクラッシュに対する耐久性を確認することはできません。
ネットワーク プロトコル
Dropbox のサーバー アーキテクチャのすべてをモッキングすると、実際のクライアント – サーバー通信プロトコルのバグは、いくつでも隠せる可能性があります。当社のプロダクション環境は複雑であるため、モックの動作が現実と合わなくなるリスクは高くなります。一方、ネットワークをモッキングすると、Trinity をすばやく実行することができて、接続の問題からの影響を受けません。
プロトコルのテストには、Heirloom という名前の別のテスト スイートを使用しました。Heirloom は、決定性の高いランダムな同じシード原則で動作し、クライアントの実行を制御します。一方で、ネットワーク上で実際の Dropbox サーバーとやり取りする必要があるため、決定性が高いことによってもたらされる一部の利点とのトレード オフが発生します。また、この方法のオーバーヘッド(つまり、複数の言語境界を越え、バックエンド スタック全体を介して通信すること)によって、Heirloom の実行速度は Trinity の約 100 分の 1 になります。Heirloom の動作の仕組みについては、今後のブログ投稿で取り上げます。
最小化
この他にも Trinity で発生するトレード オフがあります。Trinity がモッキングするシステムの機能は CanopyCheck よりも少ないため、不合格となるテストケースを最小化するのが、CanopyCheck よりも難しくなります。Nucleus の複雑で緊急性の高い動作を数多く検証するほど、Nucleus の動作の影響を受けずにテストの入力に摂動を加えることが難しくなります。3 つのツリーの初期状態に対する変更が小さくても、その後のネットワーク リクエストのスケジュールの順序を変更し、不合格となるランダム シードを無効にしてしまう可能性があります。CPU 時間を何日も費やして、ようやく結果が得られるのです。現在、私たちは、この問題の解決方法について検討しています(たとえば、グローバル PRNG を複数の独立した PRNG に分離することなどを検討しています)。しかし、現時点では、デベロッパーが自身でシナリオの分析と新しいログの挿入を行い、grep フィルタを調整してトレースで最も重要な部分に焦点を当てる必要があります。
結局、どのような確認作業でも、テスト対象のカバレッジがある程度制限されます。当社の CI では、この他にも高い抽象度で稼働するテスト スイートを複数用意しています。Trinity ほどの使いやすさとパフォーマンスは得られませんが、Trinity が対象としていないすべての機能をエンドツーエンドでカバーします(Trinity ほど機能は強力ではありません)。Nucleus 自体のテストについて言えば、Trinity のおかげで、Sync Engine Classic のときよりも大きな確信を持って、正式ビルドを展開できます。
Nucleus 開発の初期段階からテスタビリティに焦点を当てることで、CanopyCheck と Trinity のような、十分な決定性を備えたランダム化テスト システムを構築できるようになりました。書き換えの対象となったのは、10 年以上かけて安定させたコードです。つまり、10 年分以上のバグ修正を復活させないようにする必要がありました。しかし、この投稿で紹介したテスト フレームワークによって、安全に書き換えを成し遂げることができました。現在、Dropbox の同期を支える中核コードは、かつてないほど強固になっています。❤️
この記事に貢献してくれたベン・ブルーム、スジェイ・ジャカル、コメントとレビューを寄せてくれたジェフ・ソン、ジョン・レイ、リーアム・ウィーラン、ゴータム・グプタ、ユリア・タマスをはじめ、同期チームの全員に深く感謝いたします。また、Nucleus の開発に貢献してくれた、これまでのすべてのチーム メンバーにも、この場を借りてお礼申し上げます。
※本ポストは、2020年5月9日(太平洋標準時)に公開したテックブログの抄訳です。