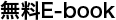目次
- 1. ユーザーには見えない Dropbox の仕組み
- 2. 問題発見までの経緯
- 3. Microsoft とのデバッグ作業
- 4. パケットの並べ替えを発見
- 5. 回避策の選択
- 6. Microsoft による長期的な修正
- 7. 謝辞
- 8. 付録 A. 学術研究
Dropbox は、パフォーマンス向上の方法を見つけるための最良の方法の 1 つに、お客様との緊密な連携があることに気付きました。Dropbox では、お客様のエンジニアリング チームとトラブルシューティング セッションを共有することで、ボトルネックの発見と解消に熱心に取り組んでいます。
その中のセッションで、Windows と Linux でアップロード速度に差があることを発見しました。そこで、Windows コア TCP チームと連携しながら、問題のトリアージを行い、回避策を見つけ、最終的にこの問題を修正しました。この問題の原因は、Windows TCP スタックと、当社が境界サーバーで使用しているネットワーク インターフェース コントローラー(NIC)のファームウェアとの間のやり取りにあることがわかりました。
結果として、Microsoft は Windows TCP の RACK-TLP アルゴリズムの実装と、パケットの並べ替えに対する回復性を強化しました。この問題は解決済みとなり、Windows Insider Program 開発チャネルから入手できる Windows 10 ビルド 21332 以降のリリースで修正プログラムを入手できます。
解決までの過程は、興味深く、多くのことを学ぶ機会となりました。たとえば、Windows には、Linux を中心に経験してきた私たちが知らなかった追跡ツールがあります。また、Microsoft のエンジニアとの連携によって、ユーザーが実施できる回避策を迅速に特定するとともに、Microsoft からの長期的な修正を提供できるようになりました。チームワークが功を奏したのです。今回のお話が、さまざまな会社の間でのコラボレーションを触発し、各社でユーザー エクスペリエンスの向上につながれば幸いです。
1. ユーザーには見えない Dropbox の仕組み
Dropbox は、動画やゲームの制作会社をはじめとする、クリエイティブ業界の多くのスタジオで利用されています。このようなスタジオのワークフローには、24 時間体制で作業が進展するよう、タイムゾーンの異なる各国のオフィスが関与することがほとんどです。通常、こうしたスタジオのワークロードには、地理的に大きく分散されていて、巨大なファイルを高速にアップロードまたはダウンロードする必要があるという特徴があります。
アップロードとダウンロードは、専用のソフトウェアではなく、すべて Dropbox デスクトップ クライアントによって行われます。この転送に使用されるハードウェアは、大きく異なります。たとえば、10 G のインターネット接続を備えた専用サーバーを使用しているスタジオがある一方、平均的な Wi-Fi 接続で何千台もの MacBook を使用しているだけのスタジオもあります。
Dropbox デスクトップ クライアントの設定項目は多くありません。しかしシンプルな UI の背後には、マルチスレッド化された圧縮、チャンクへの分割、ハッシュ処理を行う非常に高度な Rust コードが動いています。最も低いレイヤーでは、このコードは HTTP/2 および TLS スタックが基盤となっています。
ただし、Dropbox デスクトップ クライアントのシンプルな外観は、誤解を招きやすいともいえます。異なるハードウェア、異なるユースケースで、パフォーマンスとリソースの消費のバランスを取るのは、一筋縄ではいきません。
- 圧縮率を高めすぎると、10 G サーバーでアップロードスレッドが不足します。しかし、別の方法で圧縮率を緩めると、低速なインターネット接続で帯域幅を浪費します。
- サーバーへのアップロードを高速化するためにハッシュ化スレッドの数を増やすと、ノートパソコンの CPU/メモリ使用量が大幅に上昇し、ノートパソコンの温度上昇の原因となります。
- ハッシュ化コードのパフォーマンスを高めると、回転ディスクで I/O 待ちが長くなる可能性があります。
最適化のシナリオは無数に存在するため、Dropbox では大量の設定項目を用意してユーザーに最適化の作業を押しつけることはしていません。代わりに、お客様ごとのボトルネックを把握して、その環境に合わせて Dropbox クライアントを自動的に調整しています。
2. 問題発見までの経緯
私たちは、あるお客様に対して、パフォーマンスに関する日常的なトラブルシューティングを行っているときに、アップロード速度が遅いことに気付きました。そこで、いつものように、当社のネットワークエンジニアは、直ちにお客様とのピアリング接続を確立しました。これにより、レイテンシは大幅に改善されたものの、アップロード速度はホストあたり数百メガビットにまで低下したままでした。大部分のユーザーにとっては十分な速度ですが、大容量ファイルを日常的に扱っているユーザーには遅すぎます。
- ここで宣伝:Dropbox ではオープン ピアリング ポリシーを定めています。より直接的な接続でパケット損失を削減する必要がある場合は、当社とのピアリングをお試しください。
調査の過程で、この問題は Windows ユーザーに対してのみ発生していることがわかりました。macOS と Linux では、ともにネットワークのライン レートでアップロードできたのです。そこで、最も近隣にあるクラウド プロバイダーにテスト環境を準備し、管理された環境で Windows での使用量を細かく調査することにしました。
主に Linux バックエンドを専門にするエンジニアである私たちにとって、この機会は興味深く、学びの多い体験となりました。まず、アプリケーション レイヤーで、API Monitor というかなり高度な Windows 用 strace/ltrace analog を使用しました。
 Windows 用 API Monitor
Windows 用 API Monitor私たちは、Dropbox が「アプリに制限されている」のではないかという仮説を立てました。つまり、ソケット バッファに十分なデータが保持されていないために、アップロード速度が制限される可能性があるのではないかと考えたのです。しかし、すぐに、この仮説は正しくないことがわかりました。そうではなく、アプリケーションは、カーネルからの IOCP イベントを待機していたのです。このことは、通常、TCP レベルでのボトルネックを意味します。
これは、私たちの得意な領域です。すぐに Wireshark を使用しました。Wireshark によって、非アクティブな状態が長時間続いているアップロードが即座に特定されました。この間、クライアント コンピュータは、約 200 kb という非常に小さい転送中のデータについて、Dropbox 側からの ACK を待機していました。

Wireshark での結果:送信側が 21 ms(rtt)ACK を待機。その後、直ちにセグメントの新しいバッチを送信。
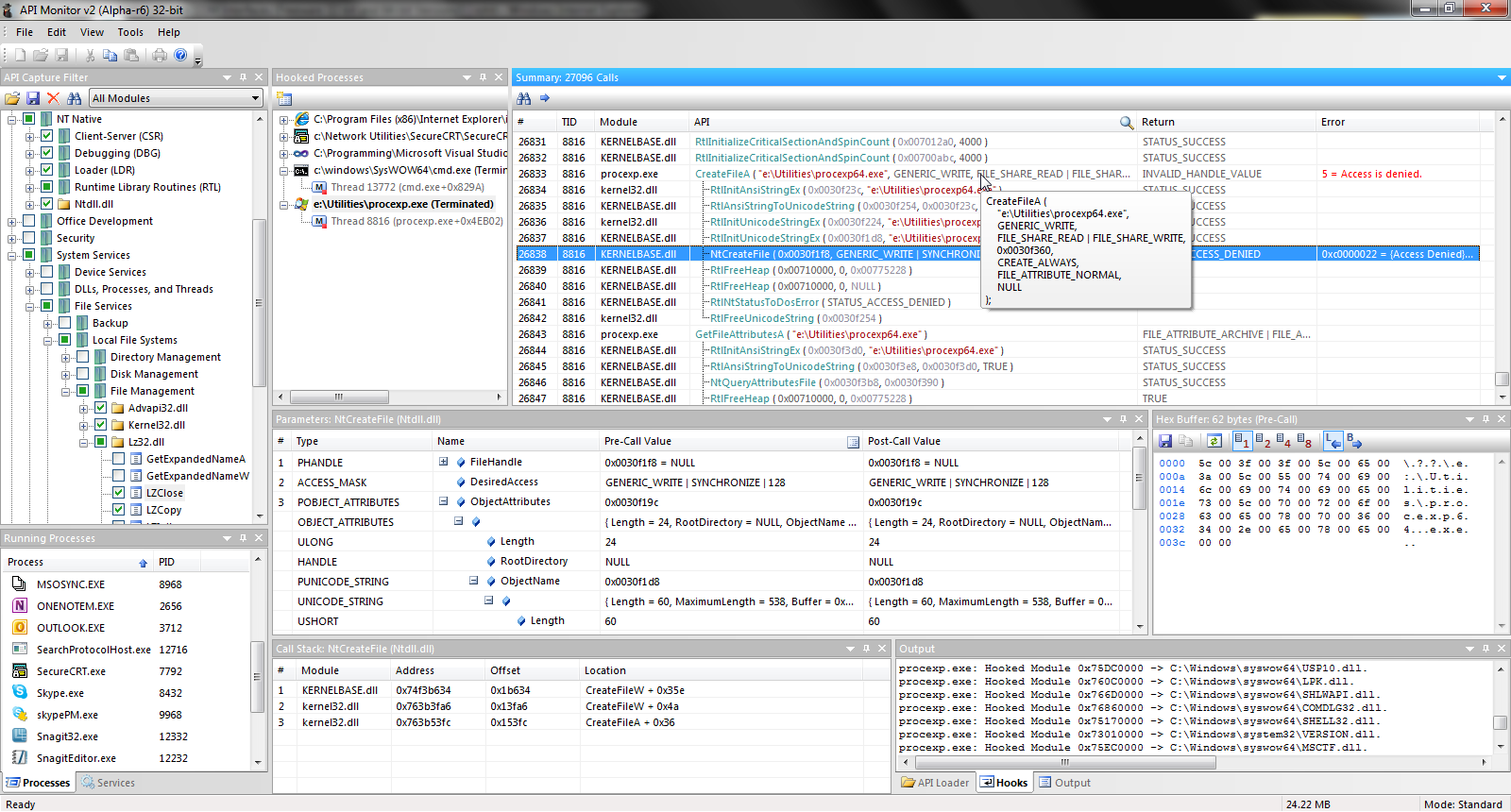
しかし、以下のように、Wireshark の tcptrace analog には、転送中のバイト数が受信ウィンドウ サイズによって制限されていないことが示されていました。 おそらくは、送信側の TCP スタックの内部に、この輻輳ウィンドウの拡大を妨げる何らかの要因があったと考えられます。
青色の線(送信セグメントの実行)の間隔と、緑色の線までの距離(受信ウィンドウ)に注目
この情報が取得できたので、Windows コア TCP チームに連絡し、問題の共同調査を開始しました。
3. Microsoft とのデバッグ作業
まず、Microsoft のエンジニアは、私たちが行っていた UNIX 流のパケット ダンプの収集方法を、Windows に合う方法に切り替えることを提案してきました。
> netsh trace start provider=Microsoft-Windows-TCPIP capture=yes
packettruncatebytes=120 tracefile=net.etl report=disabled perf=no
etl ファイルを pcap に変換する etl2pcapng というツールもあります。それを使えば、Wireshark/ tshark で詳細なパケット分析を実行できます。
これは、私たちにとって驚くべき体験でした。追跡ツールという点において、いかに Linux が遅れているのかということがわかったのです。eBPF の領域で大きな進歩があっても、Linux には、すべてのカーネル サブシステムにわたってトレースを収集するための統一形式はまだありません。 tcpdump は素晴らしいツールですが、得られるのはネットワーク上でのイベントに対する知見のみです。その他のカーネル イベントとその知見を関連付けることはできません。
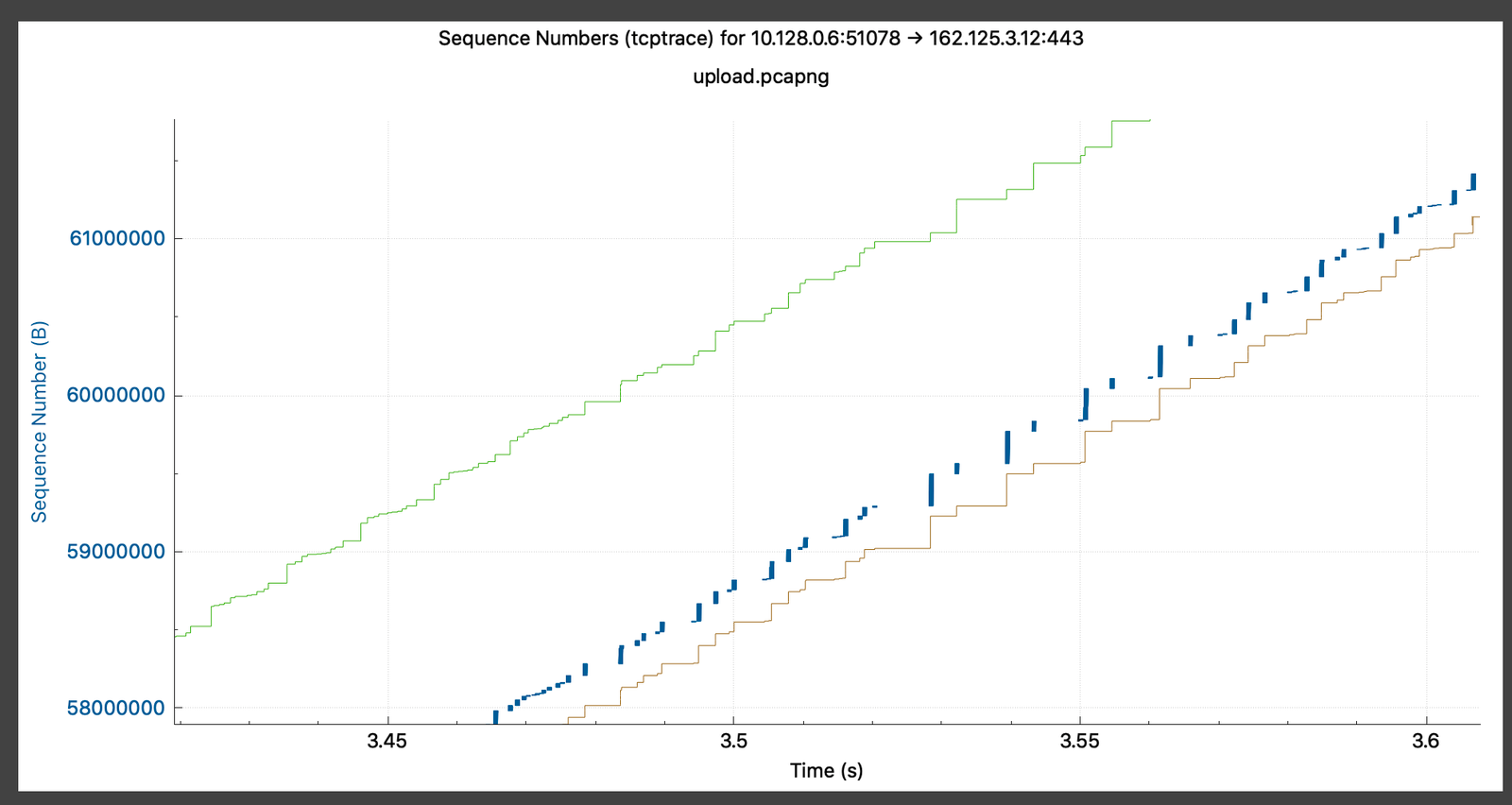
一方、 netsh trace は、ネットワーク上のイベントを TCP レイヤー、タイマー、バッファ管理、ソケット レイヤー、さらには Windows 非同期 I/O サブシステム(IOCP)で発生したイベントと関連付けます。
Microsoft Message Analyzer による netsh trace 出力の解析。tcpdump、perf trace、strace および ss を組み合わせたようなもの。
![]()
メッセージアナライザーを使用すると、小さな輻輳ウィンドウの理論をより深く掘り下げて確認することができました。 (ただし、残念ながら、Microsoft Message Analyzerはすでに提供されていません。おそらくパフォーマンスの問題だと思われます。Microsoftは、現在、パケットダンプとともにログを分析するために、 pktmon の利用を推奨しています。)
4. パケットの並べ替えを発見
この時点で Microsoft のエンジニアは、リンク上に存在するパケットの並べ替えを調査することも提案してきました。
tshark -r http2-single-stream.pcapng "tcp.options.sack_le < tcp.ack" | find /c /v "" 131
彼らは、以下のように説明しました。
このフィルターは、パケットの並べ替えを直接証明するものではありません。これは、並べ替えを示す可能性が高い DSACK をフィルタリングします。DSACK は、誤った再送信の原因になる傾向があります。システムに、並べ替えに対する回復性がすでに備わっていれば、このフィルターは無視できます。
ここからは、Dropbox 側が調査する番です。私たちは、並べ替えの発生場所を発見しなければなりません。パケット キャプチャで確認された SACK によると、トラフィックが当社の境界 L7LB(当社では Envoy を使用)に到達する前のどこかで発生していることが明らかでした。また、L4LB (当社では katran という eBPF/XDP ベースの水平方向に拡張できる高パフォーマンスのロードバランサを使用)における(ミラーリングされた)トラフィックと、L4LB と L7LB 間のトラフィックを比較すると、そのあたりで並べ替えが発生していることが明らかになりました。1~10 秒おきに、フローごとに並べ替えイベントが発生していました。
最近では、Windows は、Linux がデフォルトで使用しているように、CUBIC 輻輳制御を使用しています。100 ms を超える RTT で 10 Gbps に到達するには、損失ベースの CUBIC のパケット損失は 0.000003 % 未満にする必要があります。よって、わずかなパケット損失が認識されただけで、パフォーマンスに大きな影響を与えることがあります。
Microsoft のエンジニアからは、以下のような説明も受けました。
同時に、これまで TCP は「3 つの 重複 ACK」ヒューリスティックを使用していました。これは、パケット数において 3 次以上のネットワークでの並べ替えはすべて損失として認識されるというものです。
並べ替えが発生した場所をおおよそ特定した後、レイヤーを 1 つずつ調査し、パケットを並べ替えそうなエンティティを探し始めました。ただし、そこまで徹底した調査は必要ありませんでした。まず、ネットワークのフラッピングや ECMP 負荷分散に関する問題など、明白なイベントは排除しました。
次に、システム エンジニアは、(少なくとも OS の観点から)パケットの並べ替えが発生するのに十分高度なネットワーク カードを調査しました。これは、ATR(Application Targeted Routing)という、インテルの NIC 機能の副作用です。理論的には、この機能が TCP パケットを、その TCP フローの処理を所有している CPU に送信することで、CPU 使用量を低減します。このため、キャッシュ ミスを減らすことができます。しかし実際には、この機能によって OS が、リンク上に並べ替えがあるという判断をしてしまう可能性があります。
特に、このテーブルにオーバーフローが発生し、テーブルが強制的にフラッシュされた場合に、大幅な並べ替えが発生します。
$ ethtool -S eth0 | fgrep fdir
port.fdir_flush_cnt: 409776
port.fdir_atr_match: 2090843606356
この現象は、学術研究論文で議論されている既知の問題であることがわかりました(以下の付録 A を参照)。
5. 回避策の選択
私たちは、この問題を解決する複数の代替策を検討しました。
- CPU にプロキシ スレッドを固定的に割り当てる:これは、IRQ の固定割り当てと XPS を組み合わせて、1 つのコアから別のコアにジャンプするスレッドを排除することで、並べ替えの可能性をなくす方法です。理想的な解決策ですが、開発の労力が大きくなり、展開も必要になります。今後 2 年間にわたって、境界での CPU 使用量の制限に近づかない限り、このオプションの実施は見合わせることにしました。
- Flow Director を再設定する:以前、10 G インテル NIC(ixgbe)には、Flow Director が使用可能なメモリ量を変更できる FdirPballoc パラメータがありました。ところが、このパラメータは、現在 i40e ドキュメントにも、ixgbe の新しいカーネル バージョンにもありません。よって、すぐにこの方法の採用はあきらめました。私たちは、この切り替え可能なパラメータに何が起こったのかを知りたい「カーネルの考古学者」ではありません。
- ATR をオフにする:どのような形でも ATR を活用できていないため、このアプローチを採用することにしました。
ethtool の「priv flags」機能によって、ATR をオフにすることができます。
# ethtool --set-priv-flags eth0 flow-director-atr off
ドライバーやファームウェアによっては、この機能の一連のフラグが、まったく異なることがあるので注意が必要です。この例では、 flow-director-atr はインテル i40e NIC に固有です。
この変更を単一の PoP に適用した後、サーバー側のパケット並べ替えは、即座に低減されました。

ここでは、データが順番に到着しない場合には、「Challenge ACK」をクライアントに送信したので、受信する並べ替えの代わりに「Challenge ACK」率を使用した。
クライアント側では、これに比例して Windows プラットフォームでのアップロード速度が即座に向上しました。

上の図は、チャンクあたりの平均アップロード速度(前週比)を示している。
その後の確認として、プラットフォームごとに、デスクトップ クライアントのアップロードとダウンロードのパフォーマンスの追跡も開始しました。Dropbox 境界ネットワーク全体にこの修正を導入すると、Windows でのアップロード速度は、macOS と同等にまで向上しました。
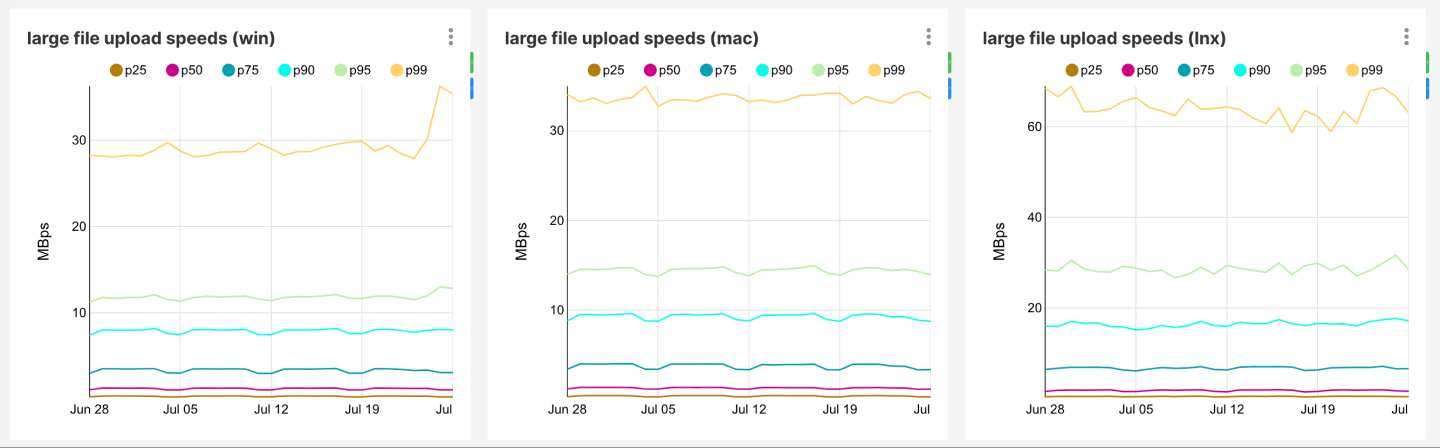
Linux でのアップロード速度は Linux を代表するものではない。Linux ホストの大部分は、多数の CPU、RAID、1 ギガビット/秒以上のインターネット接続が備わったサーバーである。
6. Microsoft による長期的な修正
Dropbox にとっては、今回の話はここで終わりです。その一方で、Windows コア TCP チームは、Windows TCP の RACK 実装が、並べ替えに対して高い回復性を備えるよう、機能強化を開始しました。この機能強化は、先日公開された Windows 10 ビルド 21332 で完了しました。このビルドには、並べ替えヒューリスティックなど、最近公開された標準化過程 RFC「RFC 8985:The RACK-TLP Loss Detection Algorithm for TCP(TCP 用 RACK-TLP 損失検出アルゴリズム)」が完全に実装されています。このヒューリスティックによって TCP はアップグレードされ、ネットワークでのパケット並べ替えのラウンドトリップ時間まで、回復性を高めることができます。
理論的には、並べ替えヒューリスティックの論理的根拠が、今回の Flow Director による副作用をカバーするといえます。Microsoft チームのエンジニアは、以下のように説明してくれました。
「SACK(選択確認応答)が行われたセグメントを示す ACK を受信したときに、送信側は、それが並べ替えの結果であるのか、損失の結果なのかがすぐにはわかりません。この 2 つの違いは、失われたシーケンスの範囲が、後で再送信が行われることなく埋められた場合にだけ、事後的に区別できます。そのため、損失検出アルゴリズムでは、パケット損失とパケット並べ替えの識別を試行できるよう、ある程度の待ち時間(並べ替えウィンドウ)を確保する必要があります。」
実際に、私たちは ATR のオンとオフを切り替えながら、入手可能な最新の Windows 10 ビルド(10.0.21343.1000)で単一の PoP に対してテストを再実行しました。結果として、アップロードのパフォーマンスに劣化は見られませんでした。
7. 謝辞
この固有の問題は当社のインフラストラクチャ ネットワーク スタックの非常に深い部分に関わるものでしたが、トラブルシューティングには、Microsoft および Dropbox の両社から以下の複数のチームにご協力いただきました。
- Dropbox ネットワーキング:アミット・チュダサマ
- Dropbox デスクトップ クライアント同期エンジン チーム:ジェフリー・ソン、ジョン・レイ、ジョシュア・ワーナー
- Microsoft コア TCP チーム:マット オルソン、プラヴィーン・バラスブラマニアン、イー・ファン
- さらに、当社の共有パフォーマンス向上セッションにご参加いただいた、企業のエンジニアの皆様にも感謝いたします。
8. 付録 A. 学術研究
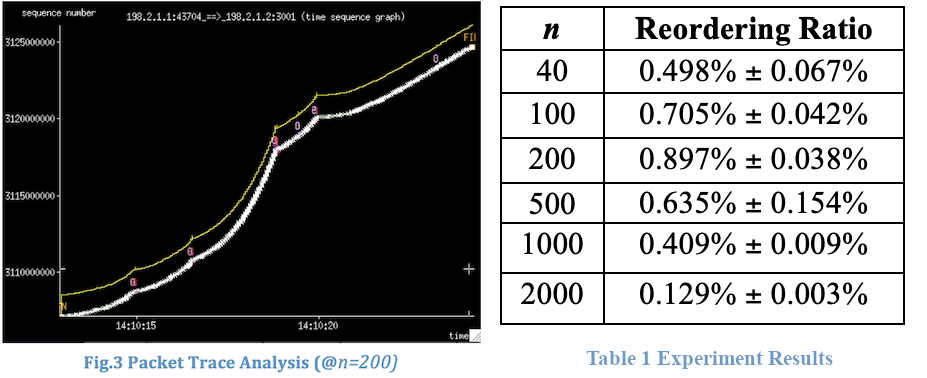
この問題に直面したのは、私たちが最初ではありませんでした。この問題の原因を特定して調査に着手してからすぐに、私たちは、これが HPC クラスターでの既知の問題であることを発見しました。その例として、フェルミ研究所による論文「Why Does Flow Director Cause Packet Reordering?(Flow Director がパケット並べ替えの原因か?)」より、以下に 2 つ関連情報を引用します。
アレクセイ・イワノフ、ディミトリー・マルコヴィッチ共著