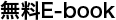// クリシェル・ハードソン=ハーレイ、ロス・デリンガー、トン・ファム
※本ブログは、2022 年 4 月 25 日に公開されたブログ “That time we unplugged a data center to test our disaster readiness” の翻訳版です。
目次
2021 年 11 月 18 日の木曜日。この日、Dropbox がダウンすることはありませんでした。何もない普通の日なら、これは Dropbox がいつもどおり順調に稼動しているサインです。しかし実際は、いつもと違う何かが起きていたのです。太平洋時間の午後 5 時、サンノゼにあるデータセンターを Dropbox の全ネットワークから遮断するよう指示が出たとき、Dropbox の社員たちは息をひそめて Zoom ミーティングに集まっていました。 この日は、ディザスタ レディネス(DR)チームが 1 年以上かけて取り組んできた集大成を迎える日であり、Dropbox としても、6 年以上の歳月をかけた全社的な取り組みが実を結んだ日でした。
ますます多くの自然災害が発生している昨今、Dropbox のデータセンターに対する自然災害リスクについて検討することは重要です。Dropbox のコアバリューは、お客様の信頼に足る存在になることです。ディザスタ レディネスの視点からこれを考えるなら、物理的な場所に対するリスクを評価することに加え、そうしたリスクを軽減する戦略を導入することも重要と言えます。
2015 年に AWS からの移行を果たした後、Dropbox はサンノゼに多くのリソースを集約していました。ユーザーのメタデータについては長らく他のリージョンにもレプリケートされていましたが、それでもサンノゼは Dropbox のサービスの多くがホストされ開発される場所になっていたのです。またサンアンドレアス断層に近いため、地震によって Dropbox がオフラインにならないようにすることが重要でした。災害対策の度合いをお客様に示すために使った方法の 1 つが、RTO(復旧時間目標)という指標です。RTO が示すのは、Dropbox が約束できる、大規模災害から復旧までにかかる時間です。地震を含むあらゆる種類の災害に備え、推定 RTO を徐々に短縮するためにいくつものプロジェクトが何年にもわたって進行してきました。
2020 年と 2021 年に DR チームが主導した、部門の枠を越えた大規模な取り組みは、サンノゼのデータセンターをオフラインにするテストの実施に至りましたが、そこまでの過程で、Dropbox は RTO を驚くほど短縮することに成功しました。この記事では、不可能を可能にするまでのストーリーを紹介します。
1. スタートは Magic Pocket から
RTO の大幅短縮を成功させるための課題に前向きに取り組むには、Dropbox のアーキテクチャがどのように設計されたかを理解することが大切です。
Dropbox には主要なサービス スタックが 2 つあります。1 つはブロック データ(ファイル)用で、もう 1 つはメタデータ用です。Dropbox テクニカル ブログの熱心な読者ならご存じかと思いますが、Magic Pocket とは、ブロック ストレージを実現するソリューションで、信頼性を高めるためにマルチホーム構成を採用しています。マルチホームとは、複数のデータセンターからサービスを提供できる構成のことです。
また、Magic Pocket は、いわゆる「アクティブ/アクティブ」構成のシステムです。つまり、マルチホームであるだけでなく、複数のデータセンターからそれぞれ個別にブロック データを同時に提供できる構成になっています。その設計にはレプリケーションと冗長性があらかじめ組み込まれていて、リージョン単位での障害が発生した場合でも業務に与える影響を最小限に抑えることができます。この種のアーキテクチャは災害発生時にも高い回復力を発揮できます。データセンターが喪失しても、ユーザーの視点からは目に見える影響がないからです。Magic Pocket の導入後、Dropbox はアクティブ/アクティブ構成の構築を最終目標として、耐障害性に優れたメタデータ スタックを構築するために 3 フェーズからなる計画を実行に移しました。
このプロジェクトの第 1 フェーズは、アクティブ/パッシブ構成を実現することでした。これはつまり、当時のアクティブ メトロ(サンノゼのデータセンター、以降「SJC」)からメタデータを別のパッシブなメトロに移せるようにするために、必要な変更を行うということでした。こうしたプロセスは「フェイルオーバー」と呼ばれます。
私たちは 2015 年に初めてのフェイルオーバーを行い、成功しました。これは、最終的な目標に近づくために行った、1 回限りのテストでした。アクティブ/アクティブなメタデータ スタックに移行すること、つまりユーザーのメタデータを複数のデータセンターから独立的に提供できるようにするという取り組み始めたとき、私たちはこの目標達成がいかに困難かを思い知らされました。
2. 物事を複雑にするメタデータ
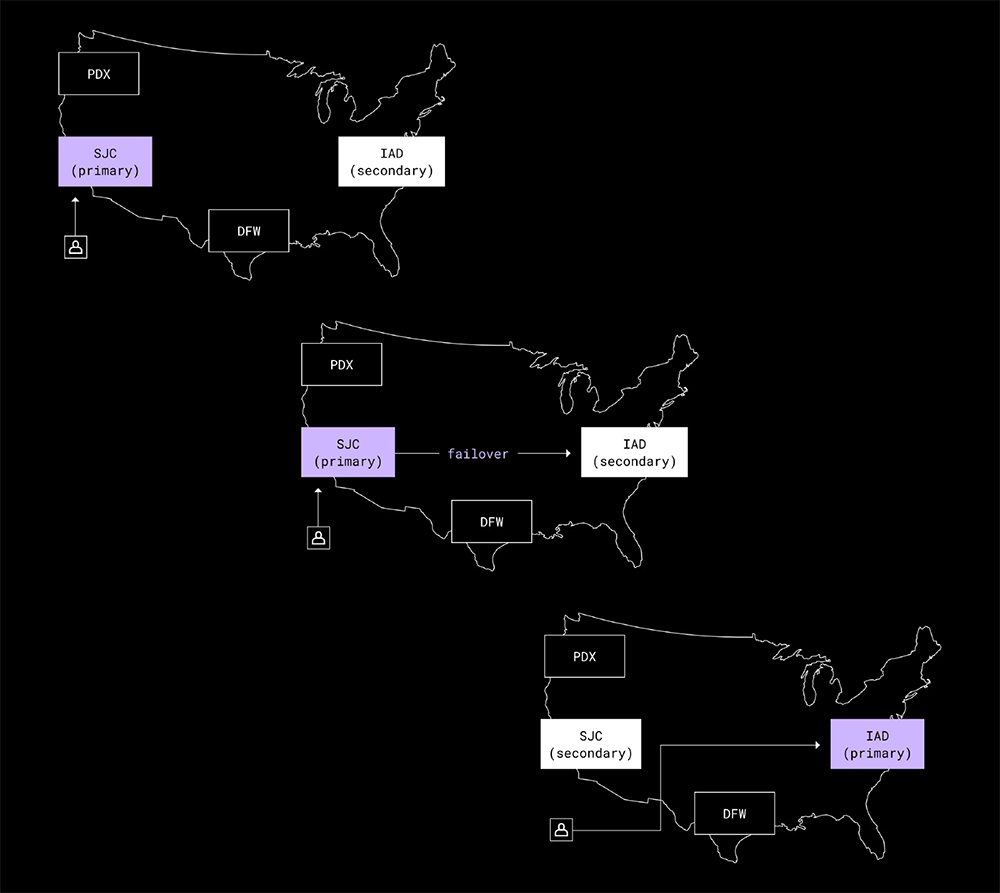
メタデータ スタックは、シャーディングされた 2 つの大規模な MySQL のデプロイメントを基盤として構築されていました。1 つは一般的なメタデータを保存する自社のデータベース Edgestore で、もう 1 つはファイル システムのメタデータを格納していました。1 つのクラスタ内にある各シャードは、6 台の物理マシンに割り当てられています。各コア リージョンに 1 台のプライマリと 2 台のレプリカがあります。
MySQL レイヤーでは、2 つの主要なトレードオフがあり、Edgestore でのデータ モデルの手法も複雑でした。そのため、ディザスタ レディネスの計画は再考を迫られることになりました。
1 つ目の MySQL トレードオフは、レプリケーションの処理方法です。Dropbox では、半同期のレプリケーションを使用することで、データ インテグリティと書き込み遅延のバランスを取っています。ただし、このアプローチを選んでいるために、リージョン間でのレプリケーションは非同期で行われます。つまり、リモートのレプリカはプライマリのリージョンと比べてトランザクション数が常に一定数だけ少なくなるということです。レプリケーションにこうした時間差があるため、プライマリのリージョンに突然の完全停止が起こった場合、対処するのが非常に難しくなります。この点を踏まえて、RTO やもっと大きな観点からディザスタ レディネス計画の全体について再検討しました。プライマリ リージョンがまだ稼動しているが長くは持たないという「障害発生直前」の状況を基準に考えることにしたのです。Dropbox のデータセンターには多くの冗長電源や冗長ネットワーク システムがあり、頻繁にテストもしているため、このトレードオフには納得感がありました。
MySQL の 2 つ目のトレードオフは、整合性レベルについてです。MySQL は READ COMMITTED 分離モードで実行しています。一貫性に優れているため開発者によるデータの取り扱いが簡単になるというメリットがあるものの、データベースの拡張という点では制限が生まれます。拡張するための一般的な方法の 1 つが、全体的な一貫性保証を変更するキャッシュを導入することですが、読み取りのスループットが増加します。Dropbox ではキャッシュ レイヤーを導入しましたが、データベースと高いレベルで一貫性を確保できるよう設計しました。この決定によって設計が複雑になるほか、キャッシュとデータベースの間の許容できる差異に制限が生じることになります。
最後に、Edgestore は多様な目的で使用される大規模なマルチテナント型グラフ データベースであるため、データの所有権が時として複雑になります。このように所有権モデルが複雑であるために、ユーザー データのサブセットのみを別のリージョンに移すことは困難でした。
アクティブ/アクティブ システムの構築という難題に取り組むに当たって、これらのトレードオフは非常に重要です。開発者は最初の MySQL トレードオフによる書き込みパフォーマンスと、2 つ目のトレードオフによる高い一貫性に信頼を置いてきました。総合すると、これらの選択がアクティブ/アクティブ システムの設計を考える際のアーキテクチャ選択を大きく狭めていたほか、完成したシステムの複雑性も大幅に高めていました。2017 年までに、この取り組みは停滞してしまいました。しかし社内には依然として、データセンターで考えられる障害に備えたより堅牢なソリューションを開発すべきだという強い意見がありました。災害発生時にビジネス継続性を確保するため、私たちは方向転換をしてアクティブ/パッシブの障害モデルを優先することにしました。
3. ディザスタ レディネス チームの誕生
アクティブ/パッシブに注力すると決めてからは、フェイルオーバーを頻繁に行うために必要なツールを構築し始めました。2019 年には初めて正式なフェイルオーバーを実施しました。それ以来、四半期に 1 回このフェイルオーバーを実施し、そのたびにプロセスの改善を続けてきました。2020 年は新型コロナウイルスの影響で世界は一変しましたが、Dropbox のディザスタ レディネスにとってもターニング ポイントとなりました。
2020 年 5 月、フェイルオーバー ツールの重大な障害が大規模な機能停止を引き起こしました。その結果ダウンタイムは 47 分にも及んだのです。フェイルオーバーの原因となったスクリプトは、エラー発生時にプロセスを部分的にしか停止しなかったため、「半障害」のような状態のままになってしまいました。この障害によって、私たちのディザスタ レディネス戦略における重大な問題がいくつか浮かび上がりました。
- フェイルオーバーを実施するシステムが安全に停止できなかった。
- 独立したサービス チームは各自のフェイルオーバー プロセスには責任を持っていたが、別のプロセスとは切り離されていた。
- フェイルオーバーの実施回数が頻繁ではなく、このアプローチを練習する機会が少なかった。
最初の問題を解決するために、既存のフェイルオーバー ツールとプロセスの緊急監査を開始しました。ツールが安全に停止できるような変更を行い、フェイルオーバー テストを実施する際の見落としを防ぐためにチェックリストを作り直しました。
2 つ目と 3 つ目の問題に対処するために、フェイルオーバーを専門に扱うチームを編成することにしました。これが、ディザスタ レディネス(DR)チームです。別の業務を抱えずにフェイルオーバーを専門にするチームを作ったことで、テスト実施の頻度を四半期に 1 度から毎月に短縮することができました。頻繁にフェイルオーバーを試すことで、アプローチに対する自信が高まったほか、災害発生時の対応や復旧が以前よりも大幅に速くなりました。
明確な権限が与えられた 7 人のチームは、2021 年の末までに RTO を劇的に短縮するという野心的な目標を掲げました。
4. フェイルオーバー強化の年
2020 年 5 月の停電時に明らかになった主な懸念点は、あるメトロから別のメトロへのフェイルオーバーを処理する際に単一のモノリシックな Go バイナリに依存していたことです。このツールは最初の数回はフェイルオーバーを処理できていましたが、フェイルオーバーの目標が高くなるにつれ管理するのが難しくなってきました。
最終的に、ツールをゼロから開発し直すことになりました。新しいツールは、よりモジュラー型で柔軟に構成できるものを目指しました。私たちが参考にしたのは、Facebook の Maelstrom 報告書です。この報告書では、トラフィックをスマートにドレインすることでデータセンターの災害に対処するシステムについて詳述しています。ただし、私たちの場合はこの基本的な考え方を Dropbox のシステムに応用しながらも、MVP(Minimum Viable Product:実用最小限の製品)を目指して開発することにしました。
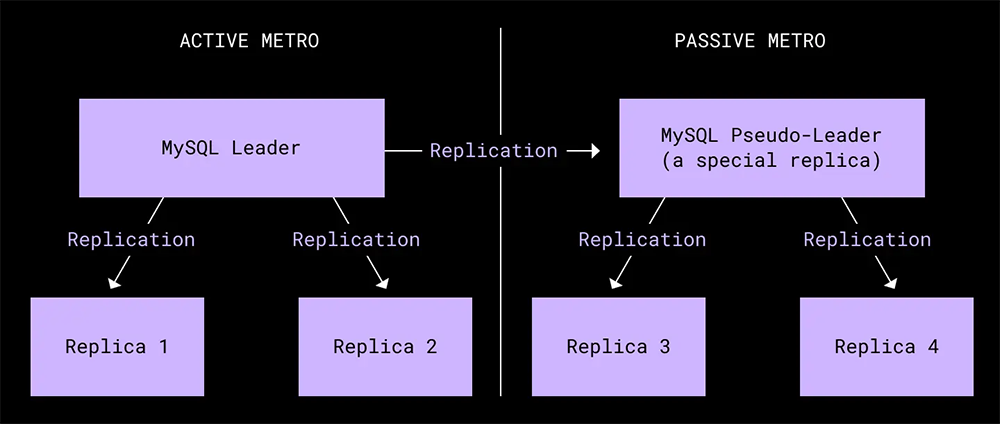
私たちは Maelstorm の「ランブック」という概念を導入しました。ランブックは1 つ以上のタスクで構成され、各タスクで 1 つの具体的な操作が実行されます。すべてのタスクが 1 つの有向非巡回グラフを形成しており、これによって、フェイルオーバー テストの実施に必要な現在の手順を記述するだけでなく、ディザスタ リカバリ テスト全体も記述できます。さらに、解析や編集が容易な構成言語で、フェイルオーバーの実施に必要なランブックを記述することもできます。こうすれば、フェイルオーバー プロセスの変更や更新が構成ファイルの編集と同じくらい簡単になります。
Go バイナリを直接編集するよりもはるかに軽量なプロセスであるだけでなく、異なるランブックでタスクを再利用できるようになります。その結果、一度に 1 つのタスクを定期的にテストするのが簡単になります。
下の図は、あるランブックとそのタスクのステート マシンを表しています。
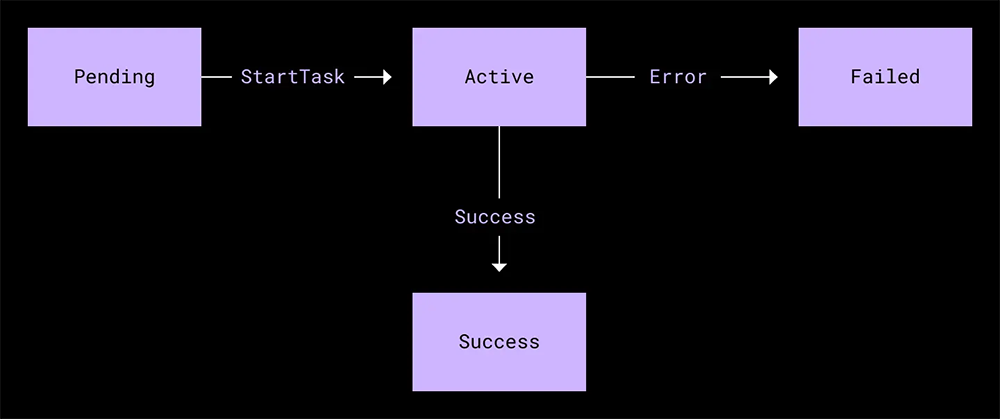
また、自社製のスケジューラー実装を記述しました。これにより、ランブックの定義を受け付け、ワーカー プロセスが実行するタスクに送信できるようにしました。MVP になるよう、スケジューラーとワーカーの両方を同一のプロセス内に置き、それぞれを Go チャネルを通して通信させるようにしました。ただし、アーキテクチャは柔軟で、将来的な使用量の増加に応じてそれぞれを個別のサービスに配置することも可能でした。
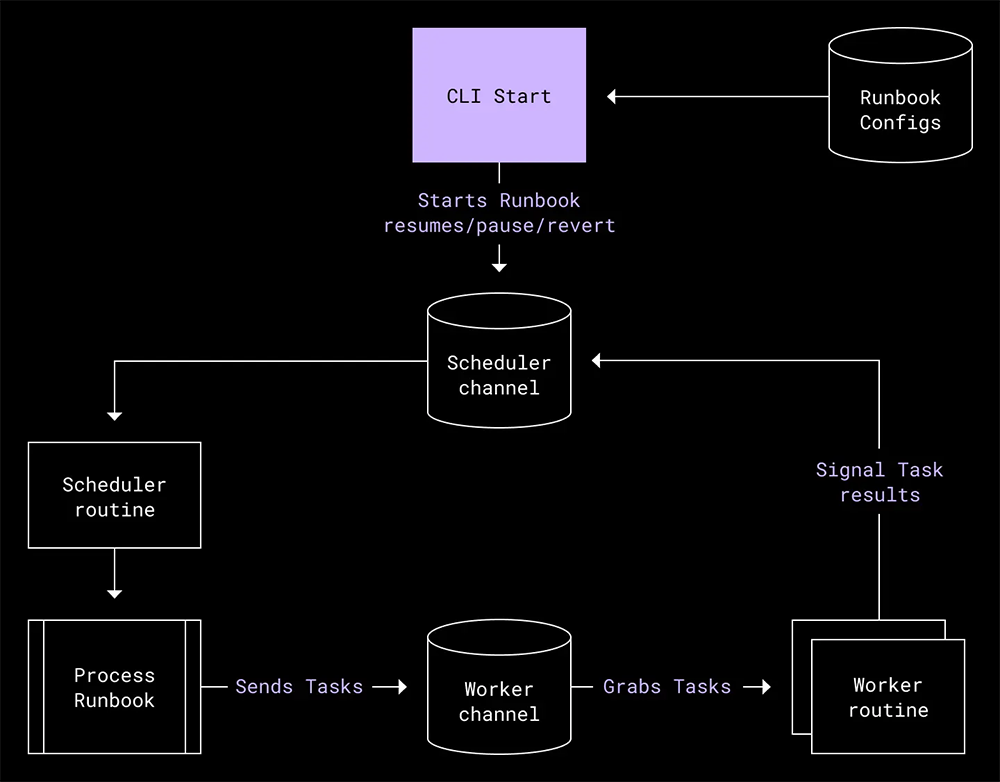
この新しいアーキテクチャでは、フェイルオーバー ランブックの実行ステータスを簡単に把握することができました。どのタスクが失敗していて、どのタスクが成功したのかが、一目瞭然です。明示的なグラフ構造によって、障害発生時にはグリーディな方法でタスクを実行できるようにしつつ、重要なアクションについてはその先行タスクが失敗している場合に実行を阻止できます。他にも、ランブックを簡単に再実行したり、実行済みのタスクや希望しないタスクをスキップしたりするなど、オペレーターが運用面での柔軟性を獲得することもできました。ランブックはどんどん複雑になっていくので、プロシージャを管理可能な状態に維持するうえで、前述のような信頼性が欠かせませんでした。
ツールにおける基礎的な改善以外にも、リスクの低減や顧客第一を実践するために次のような変更を行いました。
- 重要なフェイルオーバー プロシージャのルーティン テスト:
リファクタリングしたツールを使用し、はるかに小規模なスケールでフェイルオーバー タスクを定期的かつ自動的に実行できるようになりました。たとえば、1 つのデータベース クラスタだけでフェイルオーバーを実行する方法や、トラフィックの 1 % だけを別のメトロにフェイルオーバーしたのち、再び元のメトロに戻す方法などです。このような小規模テストが実行できたので、リグレッションの発生を見落としていないかと心配せずに、自信を持って変更できるようになりました。また、フェイルオーバー エラーを引き起こした問題の再発防止にも役立ちました。 - 運用プロシージャを改善:
DR チームは、かつて NASA で行われていた打ち上げ計画の手法を参考にしました。たとえば、正式に定義した GO/NO-GO の判断ポイントや、カウントダウンの前に行うさまざまなチェックを設定しました。また、「ボタンを押す係」や「インシデント管理者」のように明確に定義した役割を導入し、できる限り多くのステップを自動化しました。これにより、フェイルオーバー テストの各回で必要な参加者人数を 30 人から 5 人未満にすることができました。人員を減らしたことで、テストにかかるコストを減らして頻度を高めることができました。 - 中断の条件とプロシージャを明確に定義:
運用面での改善として、中断の条件とプロシージャを明確に定義することで最悪のシナリオに対する計画を策定しました。これにより、中断を要請するタイミングだけでなく、その方法についても把握できるようになりました。可能な限り短時間での復旧ができるようになり、ユーザー エクスペリエンスへの影響も最小限に抑えることができました。 - より頻繁により長時間のフェイルオーバー テストを実施:
より良いツールとプロシージャが手に入り、フェイルオーバー テストの実施内容がより詳しく把握できるようになったので、フェイルオーバーの実施頻度を四半期に 1 回から 1 か月に 1 回へと増やすことができ、1 回のフェイルオーバー テスト時間も徐々に増やすことができました。これにより、フェイルオーバー中に問題を引き起こすことになるコード デプロイメント、構成の変更、または新しいサービスを早い段階で見つけられるので、同時に対処しなければならない問題の数を減らすことができました。1 時間のフェイルオーバーを数回成功させた後、パッシブ メトロからの提供時間を 4 時間、24 時間のように徐々に増やしていきました。最終的には、パッシブ メトロからの実行を一度に 1 か月以上続けることができました。さらに、DR チームには予告なしのフェイルオーバーにも挑戦してもらいました。フェイルオーバーの実施は当日になってからチームと会社に伝え、準備の時間は 1 時間にするというものです。
2020 年の 5 月から続けてきた一連のフェイルオーバーで積み重ねてきた改善は、私たちが目標に向かって正しい道を進んでいることを示していると感じました。さらに、フェイルオーバーの対応や継続的な改善が体に染みついていることを証明することができました。フェイルオーバー サービスによって自動化のレイヤーが追加され、DR チームが行うフェイルオーバー前の作業工程を劇的に減らすことができました。ひいては、フェイルオーバーを実行する際に必要となる手動の準備作業も大幅に削減できました。こうしたツール改善のおかげで、2021 年の初めにはフェイルオーバー 1 回あたりのダウンタイムが 1 か月に 8~9 分であったのが、同年の下半期には 4~5 分へと短縮されました。次に目指すのは、SJC がダウンしてもサービスを継続できるということを証明することです。

5. ブラックホールの年
2020 年から 2021 年にかけてもフェイルオーバーの取り組みを続け、DR チーム内の小規模グループが次の重大なマイルストーンに取り組み始めました。それは、真のアクティブ/パッシブ構成を実現することです。
Dropbox のフェイルオーバー機能はメタデータを提供するスタックをパッシブ メトロに移せることを証明しましたが、依然としてアクティブなメトロ(この場合は SJC)から提供されているクリティカルなサービスがいくつかありました。私たちがたどり着いた最善の検証方法はこうです。アクティブ メトロに一切の依存がないようにするためには、Dropbox ネットワーク全体から SJC を物理的に切り離すというディザスタ リカバリ テストを実施することです。SJC からケーブルを引き抜いても、業務に与える影響を最小限に抑えられることを実証できれば、SJC が災害に襲われた場合でも Dropbox は何時間も問題なくサービスを続けられると証明できます。私たちは、このプロジェクトを「SJC ブラックホール」と名付けました。
マルチホーム
実際のユーザー トラフィックに対応するメタデータとブロックのスタックは SJC ブラックホールの影響を受けないものの、Dropbox のサービスが別のメトロから提供されるようになって内部サービスの質の低下や停止が発生した場合には、大きな問題が発生することが予想されました。こうした問題が発生することで、ブラックホールの最中に発生するかもしれない本番環境の問題を修正できなくなるのでは、という懸念がありました。そこで、SJC で引き続き実行されるクリティカルなサービスをすべてマルチホームにする必要がありました。マルチホーム化ができなかったとしても、SJC 以外のメトロから一時的にシングルホームとして実行できることが最低条件となります。
それまでに行っていた技術的な投資によって、マルチホーム化のプロセスはスムーズに進み、シングルホームのサービスは簡単に特定できました。トラフィック チームも参加してトラフィック ロード バランサーの Envoy を活用し、重要なウェブ ルートのすべてで、POP からデータセンターへと流れるトラフィックを制御しました。Courier の移行によって、私たちは共通のフェイルオーバー RPC クライアントを開発できました。これによって、サービスのクライアント リクエストを別のメトロにあるデプロイメントに振り分けられるようになりました。加えて、Courier の標準的なテレメトリによって、サービス間のトラフィック データが取得できるようになり、シングルホーム サービスの特定に役立ちました。ネットワーク レイヤーでは、Kentik Netflow のデータとカスタム ディメンション タグを活用して、Courier サービスで検出した依存関係を検証し、Courier 以外で残存しているトラフィックをキャッチします。ほぼすべてのサービスは Bazel 構成の中にあります。この構成によって、複数メトロのデプロイメント手法が構築および推進できるようになり、サービスとメトロの間のアフィニティを検証する別のデータ ソースが入手できます。リスクにさらされているサービスが特定できると、DR チームは助言とリソースを提供し、SJC への依存度を下げるサービス アーキテクチャの変更をサービス所有者ができるよう支援します。
場合によっては、別のチームと直接連携して、彼らのサービスを毎月のフェイルオーバーに追加することもできました。SJC のシングルホーム サービスの数を減らしつつ、そうしたサービスを通常のテストに取り入れることで、別のメトロからそれらのサービスを提供できるという自信を高められました。フェイルオーバー リストに追加された大がかりなサービスには、CAPE や ATF があります。どちらも、非同期タスクの実行フレームワークです。一部のチームでは、SJC のみのコンポーネントをマルチホーム化できるようピンポイントでサポートしました。最終的に、ブラックホールの日までに SJC の主要サービスすべてでマルチホーム化のサポートができたので、SJC をオフラインにした際の影響を最小限に抑えることにつながりました。
6. ブラックホールの準備
クリティカルなサービスが、少なくとも SJC 内でシングルホームではなくなったことに確証が持てたので、いよいよ SJC をオフラインにする準備に取りかかることにしました。
SJC ブラックホールの 2 か月ほど前、ネットワーク エンジニアリング チームと共同作業をしながら、この一大イベントに向けて漸次的なアプローチを採ることを決定しました。共同作業では、以下の 3 つを主要な目的に掲げました。
- SJC の完全な喪失を再現する(そして簡単に復旧する)プロシージャを決定する。
- リスクと影響の少ないメトロでこのプロシージャをテストする。
- 一連のテストの結果を踏まえて、SJC ブラックホールに向けて全社的な準備をする。
プロシージャ
当初、メトロのネットワーク ルーターをドレインすることで、SJC をネットワークから切り離すことを予定していました。この方法でもテストはできるものの、最終的には物理的な方法を選択することになりました。実際の災害発生時をより正確に再現できるのは、ネットワークのファイバ ケーブルを引き抜くことなのです。このアプローチに決定してから、当日に実施するアクションの順序を指定する詳細なメソッド オブ プロシージャ(MOP)の記述を始めました。おおまかに、MOP はこのような流れとなりました。
- トラフィック ドレインをインストールして、残存しているトラフィックをすべて別のメトロに誘導する。
- すべてのアラートと自動修復を無効化する。
- プラグを引き抜く!
- 検証を実施する(マシンへの Ping 送信、主要な指標のモニターなど)。
- 30 分のタイマーを開始して待つ。
- ファイバ ケーブルを再接続する。
- 検証を実行する。
- アラートと自動修復を再有効化する。
- トラフィックのドレインを解除する。
プロシージャの大枠を決定したのち、ダラス フォース ウォース(DFW)メトロで行う 2 回のテストに備えることにしました。このメトロを選んだのは、低リスクであるという要件を満たしているからです。クリティカルなサービスが少なく、そのすべてがマルチホームの設計になっていて、障害回復性がとても高かったのです。
DFW メトロは、DFW4 と DFW5 という 2 つのデータセンター施設から構成されていました。初回は 1 つのデータセンターでテストを行い、その次に両方の施設で実施することにしました。
その準備をするため、ネットワーキングとデータセンターのチームは写真を撮影して、ベストな状態にある光ケーブルを記録しました。また、万一の事態に備えて、バックアップ用のハードウェアを手元に用意しました。一方、DR チームは中断の条件を定義するとともに、各チームと協力してサービスをドレインするか、アラートや自動修復を無効化します。
DFW テスト 1 回目
そしてついに、1 回目の DFW テストを実施する日となりました。20 人以上の Dropbox 社員が Zoom に集まりました。画面には MOP が映し出されています。誰もが自分の役割を理解し、準備万端の状態でした。MOP に従って順に進めていき、DFW4 のファイバ ケーブルを引き抜きました。
検証を始めてすぐに、外部可用性の数値が低下していくことに気がつきました。これは予想外の事態でした。4 分ほど待ってから中断を決定し、ネットワーク ファイバを再接続しました。ネットワークの隔離が 30 分に達しなかったので、初回のテストは失敗となりました。
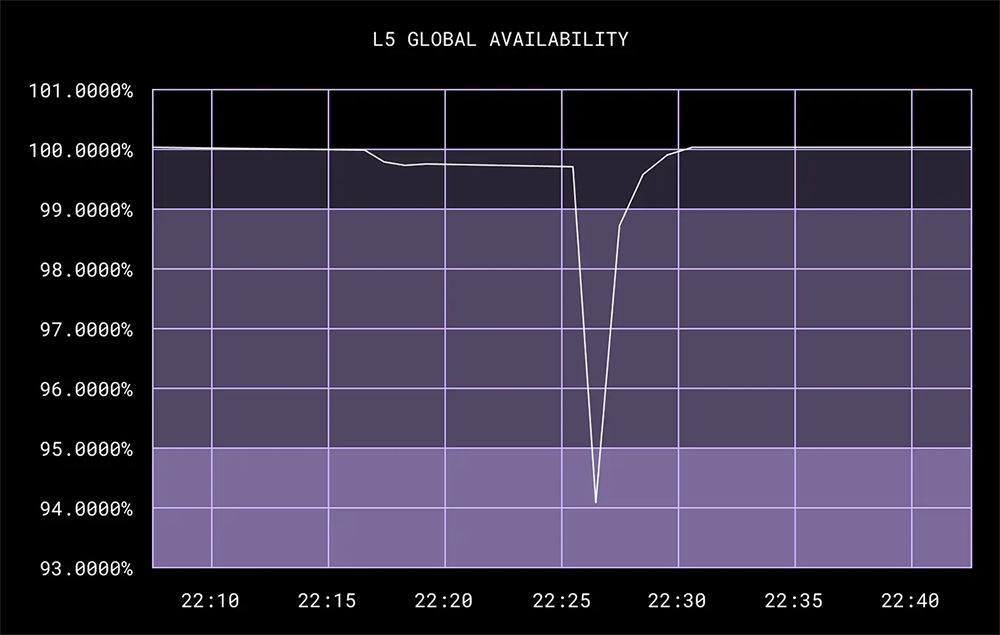
根本原因は、ケーブルを抜いた DFW データセンターである DFW4 が S3 プロキシのホームであったためです。つまり、DFW5 で引き続き実行中のサービスがローカルの S3 プロキシに通信を試みてエラーになると、これらのサービスに問題が発生し、最終的に全体的な可用性に悪影響を与えたのです。
テストに際して、私たちは 2 つの DFW 施設がおおむね同じものだと誤解していました。そのため、片方でケーブルを抜いてももう一方は影響を受けないだろうと考えていたのです。しかし、このテストで明らかになったことは、施設間で多くの依存関係がまだ残っているということです。これらの施設は将来的には独立した障害点として扱う予定ですが、テストの時点ではそうではなかったのです。このため、メトロ全体をオフラインにする場合に比べて、1 つの施設をオフラインにした方が大きな影響が出ることになりました1。
ディザスタ リカバリ テストの全体的な目的は、そこから学びを得ることだということを忘れてはいけません。今回の場合は、DR チームが多くを学んだだけでなく、それ以外のチームでも新たな知見を得ることができました。具体的には、以下のような点です。
- 個別のデータセンター施設ではなく、メトロ全体でブラックホール テストを行う必要があった。
- こうした種類のテストに特化した、より強力な中断条件を必要としていた。
- 現地のサービス所有者と協力して、彼らのサービスをドレインする必要があった。
結果として、以降のテストで使用する MOP には新たに 2 つのステップが追加されました。
- ローカルのサービスがある場合はドレインする(S3 プロキシなど)。
- トラフィック ドレインをインストールして、残存しているトラフィックをすべて別のメトロに誘導する。
- すべてのアラートと自動修復を無効化する。
- プラグを引き抜く!
- 検証を実施する(マシンへの Ping 送信、主要な指標のモニターなど)。
- 30 分のタイマーを開始して待つ。
- ファイバ ケーブルを再接続する。
- 検証を実行する。
- ローカル サービスのドレインを解除して、その健全性を検証する。
- アラートと自動修復を再有効化する。
- トラフィックのドレインを解除する。
DFW テスト 2 回目
得られた知見を生かして、数週間後に再チャレンジしました。今回は DFW メトロの全体でブラックホールを起こします。再び、写真を撮影して、バックアップ用のハードウェアを用意し、初めてとなるメトロ全体のブラックホールに備えました。
まずは、クリティカルなローカル サービスのドレインを行って、その後は通常どおりのステップに進みました。Dropbox 社員が 1 名ずつ各施設に入り、指示に従ってケーブルを抜きました。幸いにも、可用性への影響はなく、ブラックホールを 30 分間、最後まで維持することに成功しました。これは、SJC でこのネットワーク プロシージャが実現できると感じられた、大きな一歩となりました。
DFW テストから得られた大きな収穫は、デプロイメント システム、コミット システム、内部のセキュリティ ツールなど、クリティカルではないサービスの所有者に対して、SJC ブラックホールが各自のサービスにどのような影響を与えるかを深刻に考えさせた点です。SJC ブラックホールの最中にどのサービスが影響を受けるかについて一元的な情報を伝えられるよう、影響についてまとめたドキュメントが作られました。SJC ブラックホール プロシージャにサービスが確実に対応できるようにするため、独自のブラックホール前テストを実施することをサービス所有者に推奨しました。
うまくいった点や改善が見込める点について振り返る中で、もう 1 つの大きなメリットがあることに気がつきました。それは、これらのテストによって、SJC ブラックホールに使用されるプロシージャに関して主要なチームやオンコール担当者を訓練できるということです。これらが SJC に適用するプロシージャと同じであるという事実は、本番もきっとうまくいくという自信になりました。
7. 決行の日
2021 年 11 月 18 日木曜日、いよいよ SJC を遮断する日となりました。SJC にある 3 か所のデータセンターにそれぞれ、3 人の Dropbox 社員を配置しました。今回も写真を撮影しました。繊細なネットワーク ファイバは抜き差しの際に損傷を受ける場合があるため、追加のハードウェアも用意しました。Zoom 会議室には 30 人ほどが待機し、Slack チャネルにはさらに多くの関係者が集まりました。ロケット打ち上げの管制室さながら、手順を 1 つずつ慎重に進めていきました。
太平洋時間の午後 5 時、各施設で 1 本ずつケーブルを抜いていき、すべてをオフラインにしました。2 回目の DFW テストと同じように、全世界のどこでも問題は発生しませんでした。その状態のまま、目標としていた 30 分間の SJC ブラックホールを達成できました。
クライマックスは思っていた以上にあっけないものでした。しかし、静かなディザスタ リカバリこそ大成功と言えるでしょう。一大イベントがひっそりと終わった背景には、私たちの緻密な準備があったのです。
内部サービスに意外な影響が出て、追加でフォローアップしなければならないものもありましたが、このテストは文句なしの大成功でした。もし災害が発生しても、Dropbox には大幅に短縮された RTO を提供できる人員とプロセスがある、Dropbox は他のリージョンから問題なく継続的にサービスを提供できるということを、この強化されたフェイルオーバー プロシージャが証明してくれました。最も重要な点は、今回のブラックホール テストの実施によって、SJC が完全に停止したとしても Dropbox が稼動し続けられることを証明したことです。

8. 災害からの復旧力と信頼性をさらに高めた Dropbox
SJC のトラフィックを 30 分間にわたって完全にブラックホール化できたことは、Dropbox のディザスタ リカバリにとって非常に大きな一歩となりました。メトロ全体を停止させるような甚大な被害をもたらす災害時にも、ビジネスを継続させるために必要なツール、知識、手順が準備できているということを証明できました。また、サービスの信頼性と耐障害性の業界基準で、Dropbox はさらに高い競争力を示すことができました。
SJC ブラックホールは、Dropbox 内の複数のチーム間で綿密な計画と共同作業を必要とする複合的な取り組みでした。Dropbox のサービスと依存関係の複雑さを考えると、リスクに向き合って成功させたフェイルオーバーだったと言えるでしょう。デュー デリジェンスを積み重ね、頻繁にテストを行い、プロシージャを改善してきたことで、今後はこうしたリスクを最小限に抑えることができます。
このテストによって得られた最も重要なポイントは、「筋肉と同じで、トレーニングと実践を行うことでディザスタ リカバリは強くなる」という信念が改めて証明されたことです。ブラックホール テストをさらに頻繁に行い、プロセスの改善を繰り返していくことで、Dropbox のディザスタ レディネスはますます進化していくことでしょう。適切な準備と対処ができていれば、障害発生時でもユーザーは何も気づかずに Dropbox を使い続けることができます。障害からの回復力があり、信頼性に優れた Dropbox こそ、人々が信頼を寄せる私たちのサービスです。
最後に、この偉業達成に尽力した数多くの Dropbox 社員たちに感謝の気持ちを伝えたいと思います。マイルストーンを達成できたのは、皆さんのおかげです。Dropbox ほどの規模で信頼性を確保するためには、全員が主体的に責任を持つ必要があります。華々しい成功の裏には、多くのチームが積み上げてきた数え切れないほどの「小さな成功」があるのです。
– – –