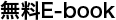ジョーイ・ベイダ、ロス・デリンジャー共同執筆
Dropbox では、インシデント管理は信頼性への取り組みにおける重要な要素だと考えています。実際の障害発生に備えるために、カオス エンジニアリング(Chaos Engineering)などのプロアクティブな手法も採用していますが、インシデントへの対応の仕方がユーザー エクスペリエンスを大きく左右します。サイトの停止や製品の問題が発生する可能性がある場合、ユーザーにとって、それは一刻を争う事態です。
導入されて数年になるインシデント管理プロセスの主要コンポーネントですが、この領域には常に進歩する要素がありました。時間をかけて、技術的にも組織的にも、さらには手続き的にも細かな調整を加えてきました。
この投稿で触れているのは、 Dropbox がインシデント管理で得た教訓の一部について、深く掘り下げて説明します。インシデントにおける指揮命令の体系についての教科書には、おそらくこれらはすべて載っていないでしょう。また、これらの改善点がどの企業にも通用するようなアプローチであると考えるべきではありません(これらがどれだけ有益かについては、技術的蓄積や組織規模といった要素で異なってきます)。そうではなく、組織独自のインシデント対応を体系的に把握し、ユーザーのニーズに合わせて展開するためのケース スタディとして活用いただければ幸いです。
1. 背景
Dropbox でインシデントを管理するための基本的なフレームワークは、SEV(SEVerity=重要度 の略)と呼ばれ、他の多くの SaaS 企業で採用されているものと似ています(このトピックにあまり馴染みがなく、その概要をお知りになりたい方は、かつて Dropbox に在籍していた Tammy Butow によるこのシリーズのチュートリアルをお勧めします)。
可用性 SEV だけが重要なインシデントというわけではありませんが、より詳細に調査する際には有益です。このインシデントの影響を受けないオンライン サービスはありません。もちろん Dropbox も例外ではありません。重大な可用性インシデントは、多くの場合、大多数のユーザーにとって最も大きな混乱を招くものです。頻繁に使用するウェブ サイトや SaaS アプリケーションがダウンしたときのことを考えてみてください。これらの SEV は、Dropbox のタイムリーなインシデント対応に最大の負担になります。そういった状況において、対応にかかる時間を可能な限り短縮することこそが、成功と呼べるものになります。
可用性 SEV に影響を与える時間を厳密に測定するだけでなく、このメトリックには実際のビジネスへの影響もあります。影響が続く限り、ユーザーの不満が増大し、解約が増え、登録が減り、ソーシャル メディアやプレスによるサービス停止の報道が原因で、評判が低下していきます。これ以外に、Dropbox では、特にミッションクリティカルな業界の一部のお客様との契約において、稼働時間に関する SLA を締結しています。これは、ユーザーにサービスを提供するシステムの全体的な可用性に基づいて定義されており、可用性が特定のしきい値を超えて低下した場合、「アップ」から「ダウン」に正式に移行します。99.9 % の稼働時間という SLA の範囲内に維持するには、ダウンタイムを月あたり約 43 分に収める必要があります。社内ではより高い基準を設け、99.95 %(月あたり 21 分)を目標としました。
これらの目標を守るために、さまざまなインシデント防止技術に投資してきました。これらの例としては、カオス エンジニアリング、リスク評価、および稼働要件を検証するシステムが挙げられます。しかし、たとえどれだけシステムの調査と理解に努力をしたとしても、SEV は発生します。そこで登場するのが、インシデント管理です。
2. SEV プロセス
Dropbox の SEV プロセスでは、インシデント対応におけるさまざまな役割が連携して SEV を緩和する方法と、インシデントから知見を得るために実行すべき手順を決定します。
Dropbox のすべての SEV には、いくつかの基本的な特徴があります。
- SEV タイプ:インシデントの影響の分類。よく知られている例としては、可用性、耐久性、セキュリティ、機能低下などがあります。
- SEV レベル:0~3 で重要度を示します。0 が最も重要。
- IMOC(Incident Manager On Call):迅速な緩和への陣頭指揮を執り、SEV 対応担当者を調整し、インシデントのステータスを伝達する責任者。
- TLOC(Tech Lead On Call):調査の陣頭指揮を行い、技術的判断を行う担当者。
顧客に影響を与える SEV では、必要に応じた最新情報の社外への提供と、エンジニアリング以外の業務機能を統括する BMOC(Business Manager on Call)も関係することになります。シナリオによっては、最新状況ページの更新、顧客との直接のやり取り、まれに規制に関する通知などが含まれる場合があります。
Dropbox には独自のインシデント管理ツールが組み込まれており、DropSEV と呼ばれています。Dropbox 社員であれば誰でも SEV を宣言できます。それによって、上記の役割の割り当てが開始され、インシデントを処理するために一連のコミュニケーション チャネルが作成されます。これらには、リアルタイムのコラボレーション用の Slack チャンネル、より広範なアップデート用のメール スレッド、アーティファクトとデータ ポイントを収集するための Jira チケット、事前入力された事後分析ドキュメントが含まれます(このドキュメントは振り返りで使用します)。社員は、特定の Slack チャンネルやメール リストに登録して、作成された一連の新しい SEV を確認することもできます。ここで、モバイル アプリの軽微な可用性インシデントを宣言するための DropSEV エントリの例を示します。
 DropSEV エントリの例
DropSEV エントリの例
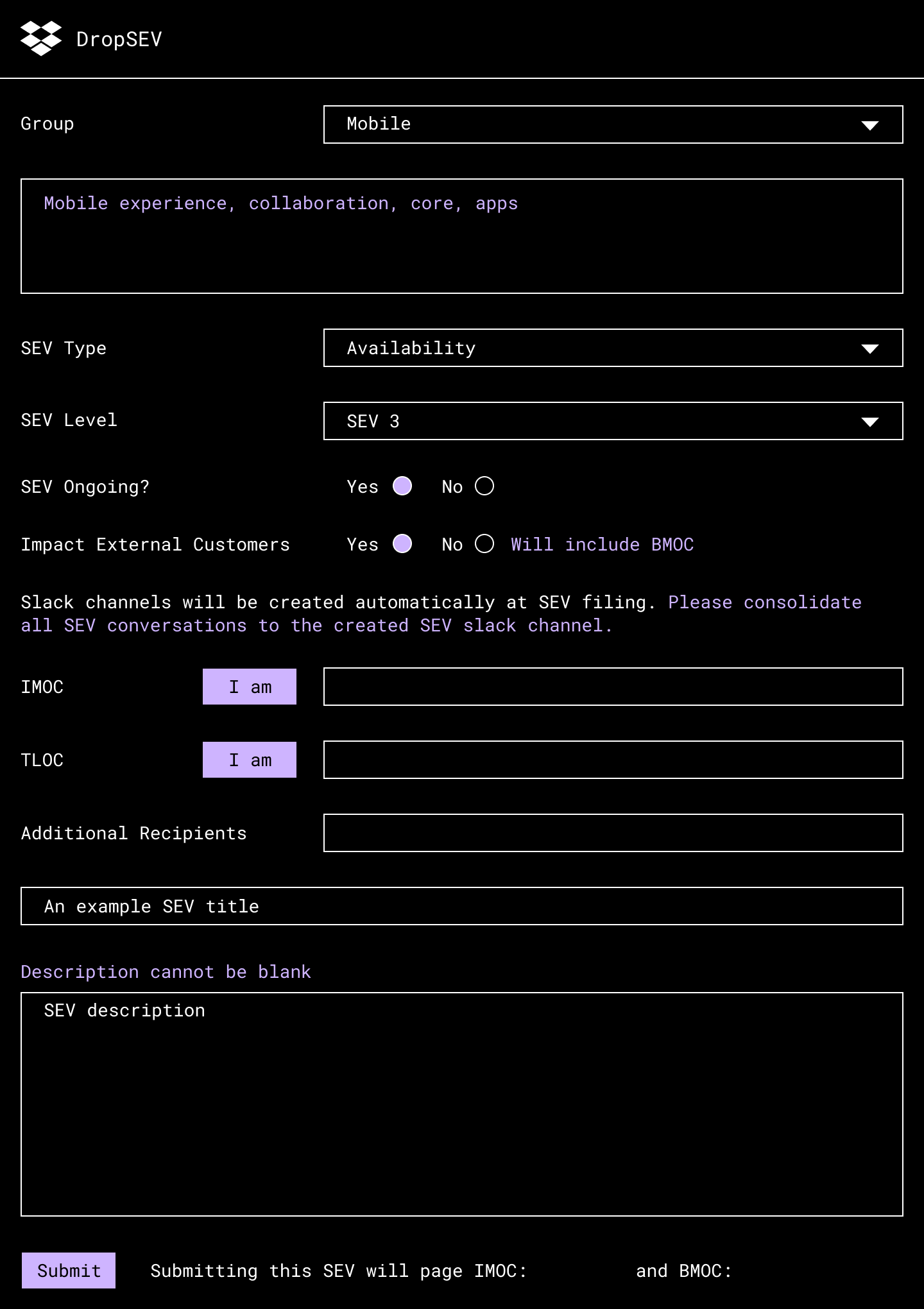
ユーザーが DropSEV でインシデントを作成すると、SEV プロセスによりその後の基本的なステージが決定されます。
 SEV プロセスの基本的なステージ
SEV プロセスの基本的なステージ
効果的なアクション アイテムを使用して有益な事後分析を生成する後半のステージでは、それぞれに微妙な違いが多くありますが(Google の SRE ワークブックの「Postmortem Culture」を参照)、この投稿では、ユーザー エクスペリエンスが影響を受けている最中で、SEV が緩和される前の期間により焦点を当てています。単純化するため、この期間を全体として 3 つのフェーズに分けます。
- 検出:問題の特定と対応担当者への警告に要する時間
- 診断:対応担当者による問題の根本原因の特定や、解決方法の特定に要する時間
- 復元:解決方法が得られた後、ユーザーが直面している問題の緩和に要する時間
月あたりのダウンタイムの目標を最大 21 分としたのを思い出してください。これは、複雑な技術的問題の検出、診断、復元に要する時間としては十分とは言えません。これを実現するためには、3 つのフェーズすべてを最適化する必要があることがわかりました。
3. 検出
問題の特定と対応担当者への警告に要する時間
3-1. 信頼性の高い効率的なモニタリング システム
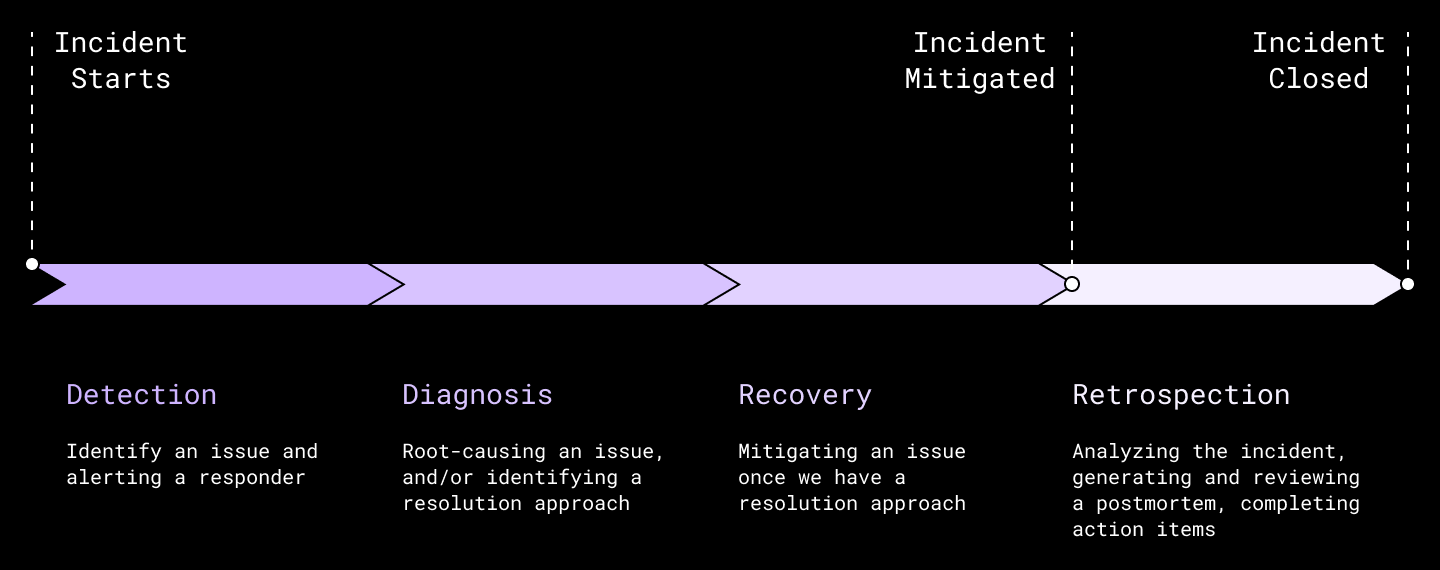
Dropbox での問題の検出に関して言えば、モニタリング システムが重要なコンポーネントになります。当社では、何年にもわたり、インシデントの際にエンジニアに信頼されるシステムを複数構築し、改良してきました。その中で最初に挙げるとしたら、何をおいても Vortex でしょう。これは、サーバー側のメトリックとアラートを行うシステムです。Vortex には、秒オーダーの収集待ち時間、10 秒のサンプリング レート、および独自のアラートを定義するサービス用のシンプルなインターフェースが用意されています。
これらの機能は、実稼働環境での問題の検出までの時間を短縮するための鍵となります。以前のブログ投稿では、Vortex の設計の技術面に関して書きました。以下はそのリンクです。
 Vortex アーキテクチャの概要。Vortex について詳しくは、ブログ投稿の詳細をご覧ください。
Vortex アーキテクチャの概要。Vortex について詳しくは、ブログ投稿の詳細をご覧ください。
Dropbox の信頼性への取り組みの基礎となるこのシステムを再設計したのは 2018 年でした。月あたりダウンタイムの内部目標を 21 分としたことを思い出していただければ、その理由をご理解いただけると思います。対応担当者への通知は、インシデント発生から数十秒以内である必要がありました。そのシグナルは Vortex によって受信され、PagerDuty を介して適切な対応担当者に警告されます。Vortex の信頼性が低かったり、処理が遅かったりすると、始める前にすでに対応が妨げられていることになります。
Dropbox のように自社開発のモニタリング システムを使用されていないとしても、そのシグナルによってどのくらいすばやくインシデントへの対応が開始されるかを想像してみてください。
3-2. メトリックとアラートの最適化
Vortex は迅速に問題を警告する上での鍵ですが、警告するための明確に定義されたメトリックがなければ使い物になりません。いろんな意味で、これは一般的に解決するのが難しい問題です。なぜなら、ユース ケース固有のメトリックは常に存在し、チームが自身で追加する必要があるからです。
自由に使用できる豊富なサービス セット、ランタイム、ホスト メトリックを用意することで、サービス所有者の負担の軽減に取り組んでいます。これらのメトリックは、RPC フレームワークの Courier とホストレベルのインフラストラクチャに組み込まれています。多数の標準メトリックに加えて、Courier には、インシデントのトリアージをさらに支援するための分散トレースとプロファイリングも用意されています。Courier には、Dropbox で使用されるすべての言語(Go、Python、Rust、C++、Java)に同じ一連のメトリックが用意されています。
これらのすぐに利用できるメトリックは非常に有益なものですが、無意味なアラートの発生も共通の課題であり、ページが実際の問題に関するものかどうかを判断するのが困難なことはよくあります。これを軽減するのに役立ついくつかのツールが用意されています。最も強力なのは、アラート依存関係システムです。このシステムを使用すると、サービス所有者はアラートを他のアラートに関連付け、問題が何らかの共通の依存関係にある場合にページをミュートすることができます。これにより、チームが対処できない問題についてのページングが回避され、よりすばやく真の問題に対応できるようになります。
3-3. インシデントのファイリングからの人的要因の排除
当社のチームでは、システムの健全性に関し、PagerDuty からさまざまなアラートを受信しますが、これらすべてが「SEV に値する」わけではありません。これまで、これが意味するのは、ページを受信した Dropbox の初動対応者が問題の修正だけでなく、SEV をファイリングして正式なインシデント管理プロセスを開始する価値があるかどうかについても懸念する必要があったということです。
こうした判断は、特にチームのオンコールとしての経験が少ない担当者には理解しづらいかもしれません。判断を容易にするため、DropSEV(前述のインシデント管理ツール)を改良して、SEV 定義をユーザーに直接表示するようにしました。たとえば、DropSEV の SEV タイプとして「Availability」を選択した場合、次のような包括的な可用性への影響の程度が SEV レベルにマッピングされたテーブルがポップアップ表示されます。
 SEV レベルによる包括的な可用性への影響の程度を示した表
SEV レベルによる包括的な可用性への影響の程度を示した表
これは一歩前進でしたが、「SEV をファイリングするか」という判断が、まだ対応担当者の処理ペースを落としていることがわかりました。Magic Pocket(データ ブロックの Get リクエストと Put リクエストの処理を担う、社内のエクサバイト級のストレージ システム)のフロントエンド コンポーネントに関してオンコールされたとします。ページを受信したら、一連の質問について検討することになります。
- 可用性が低下しているか?
- どの程度か?
- 可用性全体に上流による影響を及ぼしているか?(そのためのダッシュボードはどこにあるのか?)
- どの程度か?それは SEV テーブルとどのように一致しているか?
高度な訓練を受けたオンコール担当者でも、以前に相応の SEV を見たことがなければ、これはすばやく済ませられる手順ではありません。どれだけ手際よく行えても、停止の際、その重要な 21 分のうちの数分を費やすことになります。SEV がファイリングすらされなかったことが何回かあります。技術チームが可用性の復旧に取り組んでいる間、IMOC と BMOC が関わる機会を逃したことになります。
そのため、この夏、すべての可用性 SEV の自動ファイリングを開始しました。サービス所有者は引き続き、自身のシステム アラートを受信することになりますが、DropSEV では SEV に値する可用性への影響を検出し、正式なインシデント対応プロセスを自動的に開始します。サービス所有者が SEV のファイリングに気を取られる必要はもうありません。また、すべてのインシデント対応の役割が関われると確信しています。そして重要なのは、可用性 SEV ごとの対応を数分短縮していることです。
では、自身のインシデント対応フローの中で人間が行う意思決定を省くことができるのはどこでしょうか?
4. 診断
対応担当者による問題の根本原因の特定や、解決方法の特定に要する時間
4-1. 一般的なオンコールの基準
診断フェーズでは、アラートの最初の受信者以外に、対応担当者を加えて支援しなければならないことがよくあります。社内のサービス ディレクトリに[Page the on-call]ボタンを組み込むことで、必要に応じて効率的に別のチームに人を派遣できるようになりました。これは、PagerDuty を長年使用してきたもう 1 つの方法です。
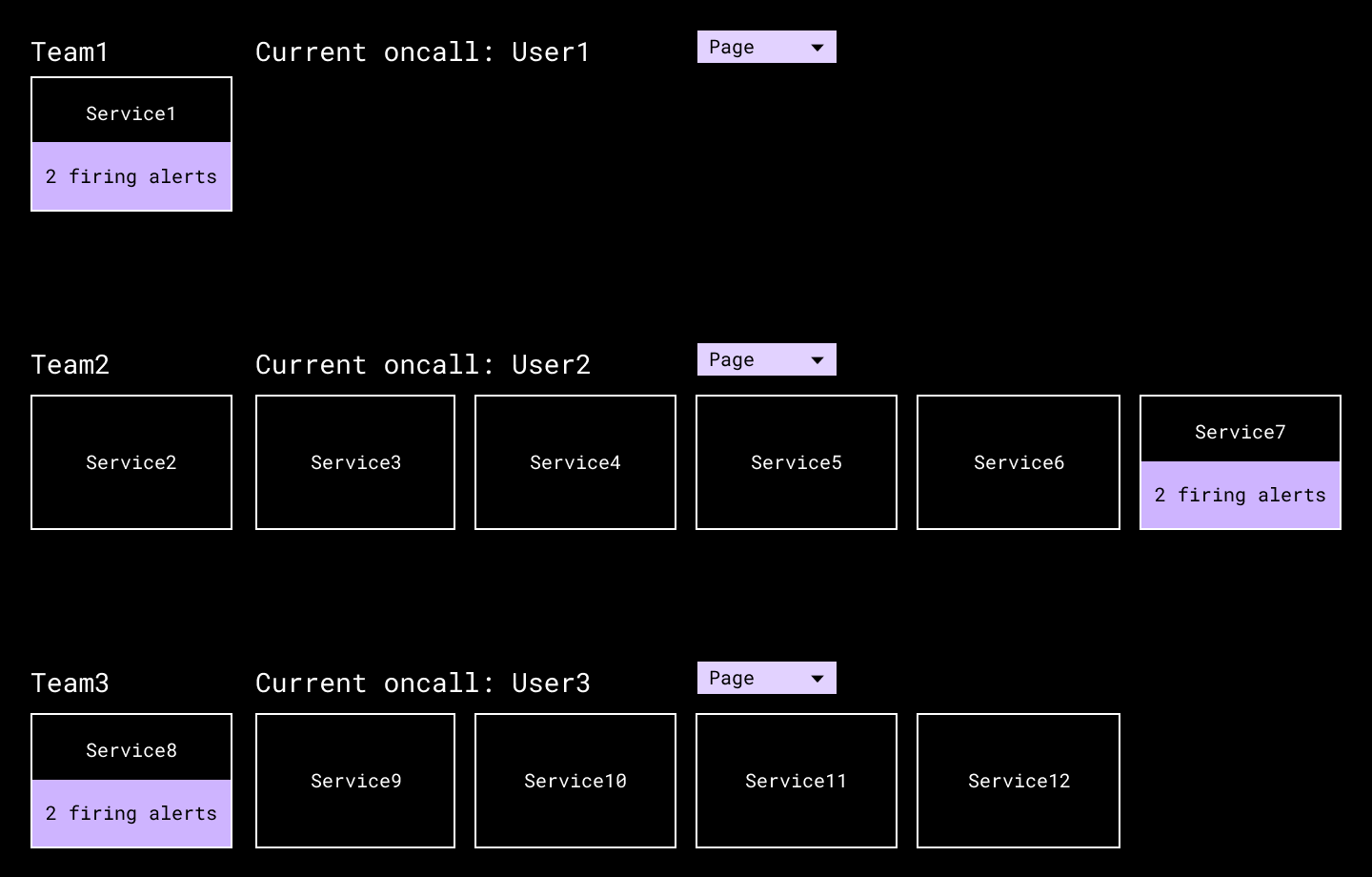 技術サービス ディレクトリには、各チームのオンコールへの参照と、緊急時に必要に応じてすばやくページを表示するためのボタンがあります。
技術サービス ディレクトリには、各チームのオンコールへの参照と、緊急時に必要に応じてすばやくページを表示するためのボタンがあります。
しかし、重要な不確定要素が見つかり、停止を 21 分未満に常時維持できなくなりました。それは、チームの PagerDuty セットアップの構成方法の違いです。その後、Dropbox のチームが、次のような質問に対して大きく異なる判断を行ったことがわかりました。
- エスカレーション ポリシーにレイヤーはいくつ必要か?
- 各エスカレーション間にはどのくらいの時間が必要か?エスカレーション チェーン全体にわたるか?
- PagerDuty 通知をオンコールでどのように受信すべきか?プッシュ、SMS、または電話の設定、またはそれらの組み合わせが必要か?
いくつかの SEV のこれらの不整合に対処した後、各チームの PagerDuty セットアップを共通のガイドラインに照らして評価する一連のオンコール チェックを開始しました。PagerDuty API を照会し、必要なチェック ロジックを実行し、違反があればチームに連絡する内部サービスが構築されました。
こうしたチェックを例外なく厳密に実施するという難しい決断が下されました。これは困難な変革でした。なぜなら、チームはある程度の柔軟性があることに慣れていたからです。しかし、上記の質問に一貫して回答することで、インシデント対応の予測可能性が大きく切り開かれることになりました。当初の構築後、さらなるチェックを繰り返し追加するのは簡単でした。そして、当初のセットをよりきめ細かくする方法(チームのサービスの重要度に応じた異なる基準など)を見つけました。また、独自のオンコール ガイドラインは、組織内のインシデント対応のビジネス要件の機能になるはずです。
この投稿の公開時点で、PagerDuty は、プラットフォーム内で複数の同様のチェックを実行できる On-Call Readiness Report(一部のプラン向け)をリリースしました。対象は Dropbox が社内で構築したものと同一ではありませんが、ある程度の整合性をすばやくとりたい場合は、開始するのにうってつけの場所になるかもしれません。
4-2. トリアージ ダッシュボード
dropbox.com を操作するアプリケーションなど、最も重要なサービスに対し、すべての高レベルのメトリックを収集し、調査の焦点を絞り込むための一連の道筋を提供する一連のトリアージ ダッシュボードを構築しました。これらの重要なシステムにとって、トリアージにかかる時間の短縮は最優先事項です。これらのダッシュボードを使用することで、一般的な可用性ページから障害のあるシステムを検出するために必要な労力が軽減されました。
4-3. 共通的な根本原因に対応したすぐに利用できるダッシュボード
インシデントやバックエンド サービスが同じものは二つとありませんが、特定のデータ ポイントがインシデント対応担当者にとって常に有用であることがわかっています。以下にいくつか例を挙げます。
- クライアント側およびサーバー側のエラー率
- RPC の待ち時間
- 例外的な傾向
- 1 秒あたりのクエリ数(QPS)
- 外れ値のホスト(エラー率が高いホストなど)
- 上位のクライアント
診断時間を短縮するため、これらのメトリックを最も必要なときにすべてのチームが利用できるようにする必要があります。そうすれば、根本原因を示すデータを探すのに貴重な時間を無駄にしなくて済みます。それに向けて、上記のすべてと、それ以上をカバーする、すぐに利用できるダッシュボードを構築しました。Dropbox での新しいサービス所有者が行う構築作業は、ページをブックマークする以外は何もありません(また、サービス所有者には、チーム固有のメトリックに対応した、よりきめ細かいダッシュボードの構築も奨励しています)。
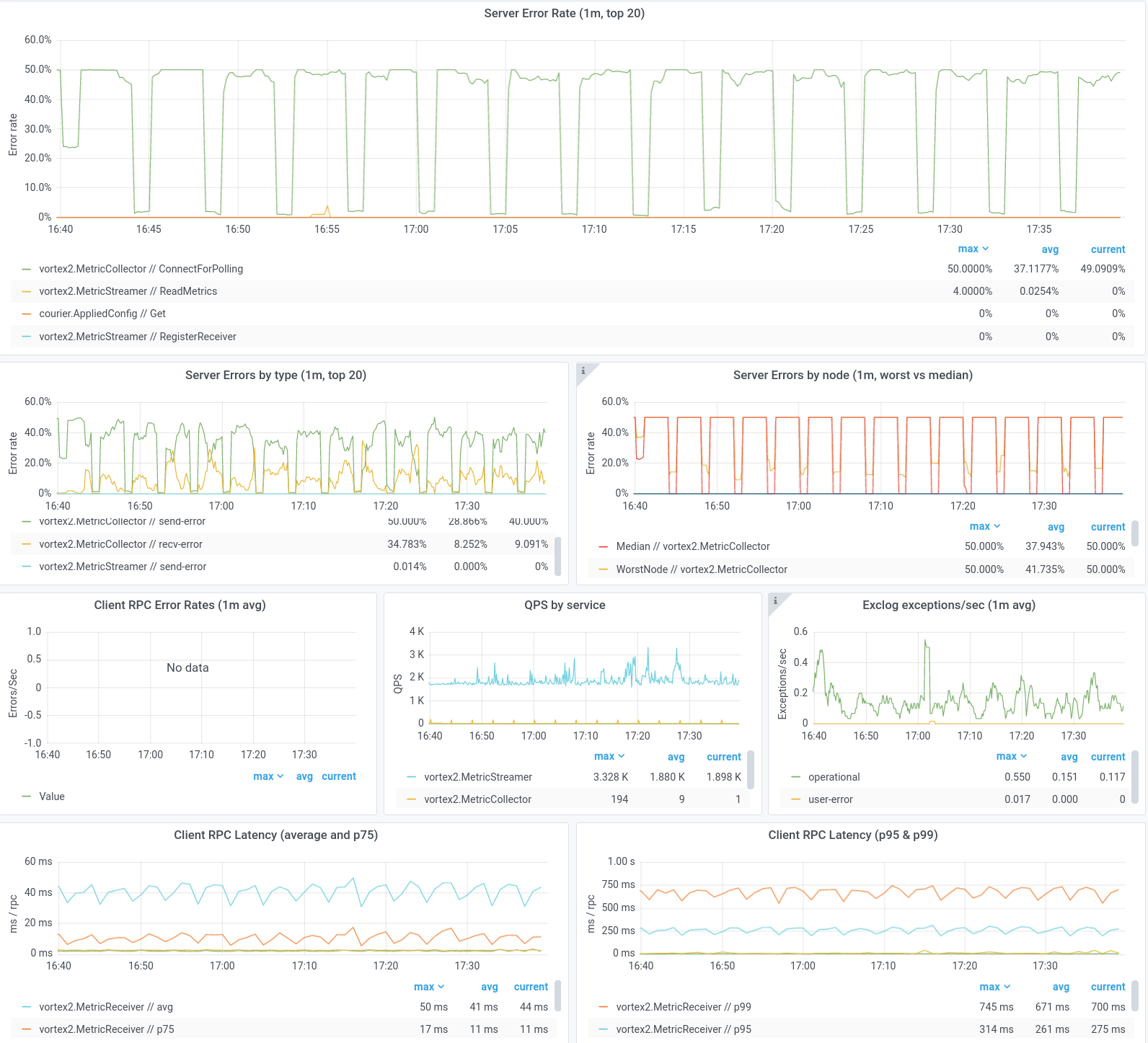 サービス所有者がすぐに利用できる Grafana ベースの Courier ダッシュボードのセグメント
サービス所有者がすぐに利用できる Grafana ベースの Courier ダッシュボードのセグメント
こうした共通のプラットフォームがあるという強みは、長期にわたって容易に一貫性を維持できることです。インシデントの根本原因の新しいパターンが見えてきました。そのデータを表示するパネルを共通のダッシュボードに追加できます。また、Grafana に注釈を追加することにも投資しています。Grafana は、主要なイベント(コード プッシュ、DRT など)をメトリック上に重ね合わせ、相関のあるエンジニアを支援するものです。こうした各々の繰り返しによって、会社全体で診断時間が少しずつ短縮されるのです。
4-4. 例外トラッキング
問題を診断するために Dropbox にある最高のシグナル ツールの 1 つが、例外トラッキング インフラストラクチャです。これを使用すると、Dropbox のあらゆるサービスでスタック トレースが中央のストアに出力され、有用なメタデータでタグ付けできるようになります。フロントエンドでは、開発者は容易に、サービス内の例外的な傾向を確認して調査できます。例外データを深く掘り下げて傾向を分析するこうした機能は、大規模な Python アプリケーションでの問題の診断の際に非常に役立ちます。
4-5. インシデント管理者の役割:注意散漫の解消
停止やその他の重要なインシデントが発生すると、SEV チームの問題診断の間は、現状把握に多くの関係者の手が取られます。
- 顧客対応チームは、解決のためにアップデートと ETA を提供する必要がある。
- 影響を受けるシステムの範囲にいるサービス所有者は、技術的な詳細を知りたがっている。
- 信頼性と経営目標に責任があるシニア リーダーは、緊急性を伝えたいと考えている。
- そして、特にシニア エンジニアリング リーダーは、気を引き締めて診断作業に参加したいと思うかもしれない。
さらに困ったことに、2020 年、対応担当者が在宅勤務を開始し、対面での共同作業ができなくなったため、インシデントの Slack チャンネルでの行き違いが拡大した可能性があります。
Dropbox では、インシデント中に上記のあらゆることが発生しました。しかし、IMOC の役割の重要な要素、つまり SEV チームがこういったことで注意散漫にならないように、これまでも取り組んできました。IMOC は大抵、トレーニングを受けたおかげで、SEV プロセス、関連する用語とツール、および事後分析とインシデント レビューに期待されることを理解していました。しかし、彼らはどうやって作戦室を動かし、SEV 対応の効率を最適化するのかを必ずしも知っているわけではありませんでした。エンジニアから寄せられた声は、IMOC から必要な最前線のサポートが提供されておらず、注意散漫によって問題の診断が遅くなっているというものでした。
IMOC の役割のこうした側面を明確にしていなかったこと、そして「何をすれば優れた IMOC になるのか」というグループ内で共有される知見が時間とともに薄れてきたことに気付きました。最初のステップは、緊急性の設定、注意散漫の解消、およびコミュニケーションの一極集中を重視するようにトレーニングをアップデートすることでした。今では、新しい IMOC が最初のシフト前にこれらの概念を実際にゲーム的に実践できる SEV シナリオに取り組むようになりました。最終的には、一連のより幅広い分野の IMOC を関わらせる机上訓練の頻度を増やすことを計画しています。そうすれば、グループが準備状況全体を定期的に評価できるようになります。
加えて、最も重大なインシデントに参加可能な上級の IMOC および TLOC のバックアップ対応チームを設立しました。彼らには、インシデントの状態を評価し、所有権を譲渡すべきかどうかを既存の IMOC/TLOC で判断するための明確な戦略を与えました。こういった上級担当者に、必要に応じて明確で周知された役割を与えることで、Slack における追加の意見といったものではなく、貴重なサポート体制と言えるものになりました。
ここでの重要な教訓:インシデント対応プロセスは、机上と実際では異なることに注意が必要。
5. 復元
解決方法が得られた後、ユーザーが直面している問題の緩和に要する時間
5-1. 緩和シナリオの想定
最初は、復元段階での確実な方法を見つけるのは難しいように思われるかもしれません。すべてのインシデントで異なる緩和戦略が必要な場合、この部分をどのように最適化したらよいでしょうか?これを実現するには、システムがどのように振る舞っているのか、最悪の(ただし対応可能な)シナリオでインシデント対応担当者がどのような手順を踏まなければならないのか、といった多くの洞察が必要です。
Dropbox では 99.9 % の稼働時間という SLA を追求していたため、四半期ごとの信頼性リスク評価の実行を開始しました。これは、システムが SEV に関与する可能性が高いインフラ チームやその他のチーム全体でのボトムアップのブレインストーミング プロセスでした。復元時間の最適化が必要であることを認識しつつ、ある簡単な疑問に集中するようチームに促しました。「システムのどのインシデント シナリオが緩和するのに 20 分以上かかるのか?」
これにより、さまざまな可能性を持った多様で理論的なインシデントが表面化しました。これらのいずれかが発生すると、ダウンタイムの目標内に収まる見込みはほとんどありませんでした。インフラストラクチャのリーダーに報告するリスク評価の結果をまとめながら、投資する価値のあるものを並べ、複数のチームがこれらのシナリオの排除に着手しました。以下にいくつか例を挙げます。
- モノリシック バックエンド サービスのプッシュ時間が 20 分を超えていた。サービス所有者は、導入パイプラインを 20 分未満に最適化し、プッシュ時間を悪化させないように定期的な DRT の実行を開始した。
- シングルラックの障害時にプライマリ レプリカが十分でなくなった場合、スタンバイ データベース レプリカを昇格させるのに 20 分以上かかることがあった。メタデータ チームは、データベース システムのラックの多様性を改善し、データベースの昇格を処理するツールを強化した。
- 実験と機能ゲートの変更は特定が困難であり、コア チームは緊急時にこれらの変更をロール バックできず、実験に関連した問題の解決に 20 分以上かかることがあった。そのため、実験チームは、変更に対する可視性を向上させ、すべての実験と機能ゲートに明確な所有者がいるようにし、中央のオンコールにロールバック機能とプレイブックを用意した。
これらのシナリオなどへの対処によって、長時間の可用性インシデントの数が大幅に減少することがわかりました。発見した新しいシナリオに対する測定の目安として「20 分ルール」を引き続き使用します。議論の余地はあるかもしれませんが、時間の経過とともにこのしきい値を厳しくすべきです。
ご自身の組織やチームでも同様の方法を採用することも可能です。処理に最も時間がかかる可能性のあるインシデントを記録し、可能性に応じてランク付けして並べ、リストの一番上にあるインシデントを改善します。次に、インシデント対応担当者向けの DRT やアクシデント発生訓練によってシナリオが実際にどのように実行されるかをテストします。こうした改善によって、復元時間はビジネスで許容できるレベルまで短縮されましたか?
5-2. 99.9 の維持
SLA が厳しいため、うまくいかなかったときに対応する時間は限られていますが、技術的蓄積は水面下で絶えず変化しています。次のリスクはどこに現れ、投資を集中させるのはどこなのでしょうか?
先ほど挙げたプロセスの変更に加え、現状を維持できるように、次の 2 つの領域に信頼できるデータ ソースを構築しました。
- SLA とインシデントに影響を受けた内容に関して 1 つにまとめた信頼できる情報源
- クリティカル パスでのサービスの相対的な影響を追跡するダッシュボード
SLA に関する信頼できる情報源が 1 つにまとまっていると、計画を立てやすくなります。これにより、内部 SLA などの各チームの寄与がどのようにお客様の保証に反映されるかについて、組織全体での混乱は生じなくなります。
 クリティカル パスに何があるのかを判断するためにトレースを使用
クリティカル パスに何があるのかを判断するためにトレースを使用
また、分散トレースを使用して、クリティカル パスでのサービスの影響も追跡します。トレース インフラストラクチャは、各サービスの重み付けの計算に使用されます。この重み付けは、特定のサービスが Dropbox 全体にとってどれほど重要であるかを概算したものです。サービスの重み付けがしきい値を超えると、その運用を厳密化するための追加の要件が課されます。
これらの重み付け(および関連する自動化)には、2 つの目的があります。1 つ目は、リスク評価プロセスの別のデータ ポイントとしての役割を果たすことです。サービスの相対的な重要性を認識することで、さまざまなシステムにおけるリスクを比較する方法への理解が深まります。2 つ目は、クリティカル パスにサービスが追加されたときに不意を突かれないようにすることです。Dropbox の規模のシステムでは、新しいサービスをすべて把握しておくことは困難なため、クリティカル パスを自動的に追跡することで、すべて捕捉できるようになります。
5-3. ユーザーへの影響の推定
「この SEV がお客様に与える損失はどれほどの大きさなのか?」
こう質問を投げかけても復元は早まりませんが、これにより、BMOC と 「信頼ガイド」を通じてユーザーと積極的にやり取りができます。これが、当社の第一の企業価値です。繰り返しになりますが、インシデント発生中の 1 秒は、ユーザーにはとても大きな意味があります。
この質問は、Dropbox での可用性 SEV に対して特に一筋縄ではいかないことが証明されています。上記でお気付きかもしれませんが、可用性 SEV レベルの定義は、可用性が低いほど深刻であるといういささか単純な仮定から始まります。この定義は、会社の規模が大きくなる前まではある程度単純でしたが、長期的には役に立ちませんでした。可用性に急激なダメージを与えてはいるものの顧客への影響がほとんどない SEV に遭遇しました。一方、可用性へのダメージが軽微でほとんど SEV と見なされないものの、dropbox.com を完全に使い物にならなくするようなものにも遭遇しました。後者の事例では、徹夜を余儀なくされました。なぜなら、ユーザーへの対応不足とコミュニケーション不足が発生しないようにする必要があったからです。
戦術的な修正として、デスクトップ アプリやモバイル アプリに比べトラフィックが少ないウェブ サイトをゼロから開始させました(つまり、ウェブ固有の可用性の問題は数字の上ではあまり目立たない場合があるということです)。エンジニアリング部門全体のチームと協力して、重要なウェブ ページとコンポーネントに対応する最大 20 のウェブ ルートを特定しました。これらの個々のルートに対する可用性のモニタリングを開始し、これらのメトリックをダッシュボード、アラート、および SEV 基準に追加しました。IMOC と BMOC に対し、このデータをどう解釈するか、可用性の低下を特定の影響にどうマッピングするか、顧客にどう伝えるかについてトレーニングし、机上訓練を行いました。その結果、その後のウェブ サイトに影響を与えるインシデントでは、主要ユーザーのワークフローが影響を受けているかどうかにすばやく気付けるようになり、その情報を使用して顧客と関わりを持てるようになりました。
私たちは、この分野でまだやるべきことがあると確信しています。9 秒の測定からカスタマー エクスペリエンスの測定に方向転換できる他のさまざまな方法を模索しています。そして、これらに伴う技術的なチャレンジを行えることに喜びも感じています。
- プラットフォーム全体のすべてのルートを、対応チームに警告を出す重要度ベースのバケットに分類できるか?
- エンジニアリングの対応をすばやく開始するために、顧客への影響についての直接的なシグナル(ヘルプ ページやステータス ページへのトラフィック、顧客によるチケットの流入、ソーシャル メディアの反応など)をどのように使用するか?
- 当社の規模で、可用性インシデントの影響を受けるユニーク ユーザー数をリアルタイムで効率的に推定するにはどうすればよいか?インシデント後に影響を受けた母集団(地域、SKU など)に関するより正確なデータを取得するにはどうすればよいか?
- カスタマー エクスペリエンスをエンドツーエンドで測定するうえで、クライアント側の機器から最も恩恵を受けるのはどこか?
6. 継続的な改善
Dropbox のインシデント管理は完璧なものではありません(もちろん完璧なところなどどこにもないのですが)。Dropbox では、会社が置かれている状況でうまく機能する SEV プロセスから始めましたが、組織、システム、ユーザー基盤の成長とともに、絶えず進化しなければなりませんでした。この投稿で概説した教訓は何もせずに手に入ったものではありません。好ましくない SEV をいくつか経験して初めて、インシデント対応に欠けていたものを理解できたこともしばしばありました。
だからこそ、インシデントの評価のたびにギャップから学ぶことが非常に重要なのです。重要なインシデントの発生を完全に防ぐことはできませんが、同じ要因で再度被害が発生するのを防ぐことはできます。
Dropbox では、これはインシデントの評価において、非難しないという文化から始まっています。インシデント中に対応担当者がミスを犯しても、彼らを非難することはありません。ヒューマン エラーに対し、どのガードレールでツールが不足していたのか、こうした状況に備えるために対応担当者に受けさせるべきトレーニングは何だったか、そもそも自動化によって対応担当者を蚊帳の外に置いていないかどうか、と考えます。こうした文化があるため、すべての関係者は、SEV から学べる難しい教訓に安心して立ち向かえるのです。
SEV の責任を個人に負わせないのと同じように、Dropbox のインシデント管理に対して行った改善を自分の手柄にする者は一人もいません。こうした教訓を取り入れるのには、数年の間の組織全体の努力が必要でした。挙げればきりがありませんが、このブログ投稿で取り上げたトピックについて、信頼性フレームワーク チーム、テレメトリ チーム、メタデータ チーム、アプリケーション サービス チーム、そして実験チームのこれまでのメンバーに、この場を借りてお礼申し上げます。
※本記事は、2021年1月に公開された記事の翻訳です。