Dropbox では、雑務を減らすために役立つ、人工知能を活用したスマートな機能を開発しています。前回のブログ投稿で解説したコンテンツの提案機能を発表して以来、この機能を強化するために基盤となるインフラストラクチャと機械学習アルゴリズムの改善に取り組んできました。
コンテンツの提案機能を強化するうえで直面した新たな課題は、サポートすべきコンテンツ タイプが多岐にわたるという点でした。Dropbox にはファイルやフォルダの他に、Google ドキュメント、Microsoft Office ドキュメント、Dropbox Paper などさまざまなコンテンツが保存されています。ユーザーが作業をしているコンテンツがどのようなタイプであっても、関連性の高いコンテンツを提案することを目指しました。しかし、こうしたコンテンツ タイプはさまざまな永続ストレージに保存されていて、異なるメタデータが設定されているうえに、ユーザーの種類もその使い方も多岐にわたります。つまり、単独の機械学習パイプラインでは、すべてのパターンをルール化することが難しい状況でした。
Dropbox のファイル システムは、通常のファイルやフォルダ、Paper ドキュメントに加え、Google ドキュメントや Microsoft Office ドキュメントのようなクラウドベース コンテンツなど多様なコンテンツ タイプをサポートしています。ユーザーに適切なコンテンツを提案するためには、これらのタイプすべてに対処できる必要があります。
基盤となるインフラストラクチャの開発が追いつくのを待ちながら、コンテンツ タイプごとに個別に対処することで提案機能をできるだけ早く強化することにしました。今回の投稿では、各種コンテンツ タイプに対処できるように複数の機械学習モデルをトレーニングし改善した方法や、各モデルをどのように統合したかについてお話しします。また、この取り組みの過程で開発し活用したツールの利用方法改善についても触れたいと思います。
目次
1. ファイルの提案機能を強化する
Dropbox のホームページにコンテンツの提案機能を導入したのは 4 月でしたが、その直後から機械学習モデルのパフォーマンス向上に取り組み始めました。このタスクには 2 つの方向からアプローチしました。1 つ目は、「予測精度を高めるためにより多くのシグナルを取り入れるにはどうすればよいか」という点で、もう 1 つは、「得られたシグナルを効果的に活用できるよう、どのようにモデルをトレーニングするか」という点です。
前回のブログ投稿では、予測を立てる際にファイルの種類を考慮したかったと書きました。ファイルの種類を定義し分類する方法はたくさんあります。たとえば、おおまかなカテゴリ(テキスト、画像、動画など)に分類するという方法もあれば、より具体的なカテゴリ(プレーン テキスト、ウェブ ドキュメント、ソース コード、ワープロ ファイルなど)や意味的なカテゴリ(契約書、レシピ、スクリーンショット、提案書)に分ける方法もあります。Dropbox では、まずファイル拡張子に目を向けました。この情報は、トレーニング時にも推測時にも簡単に取得ができるうえ、ファイルの基本的な性質についてある程度のことを伝えてくれるからです。
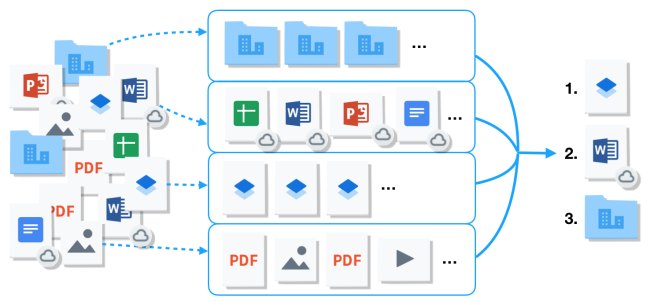
たとえば、ファイル拡張子を One-Hot ベクトルとして単純にエンコードする方法も考えられます。この際、ベクトルの次元数は、考えうるファイル拡張子の総数です。しかし、この方法は 2 つの理由から理想的とはいえません。まず、ベクトルの次元数が極めて多くなり密度が下がることが考えられ、この場合、これらのベクトルから有用なシグナルを抽出できるモデルが必要です。次に、より重要な点として、ファイル拡張子の分布はテール部分が非常に重くなるという点です。つまり、珍しい拡張子はモデルが学習しづらいことを意味します。
収集したデータセット内でのさまざまな拡張子の相対的な分布です。テール部分が長く伸びています。
こうした問題に対処するため、弱教師ありのタスクでトレーニングしたファイル拡張子の埋め込みを作成することにしました。この手法について詳しくは、次回のブログ投稿で解説したいと思いますが、単純に言えば、ファイル拡張子の埋め込みをトレーニングして、Dropbox 内の 1 回のアップロードで 2 つのファイル拡張子が同時に使用される可能性を予測しようというものです。このアプローチによって、意味的に近いファイル拡張子(例:JPEG と PNG)が埋め込み空間内で近接する、次元数の少ない高密度のベクトルが得られました。この手法を採用したことで、不均一に分散されたデータから効果的に学習できるモデルが実現し、オフラインとオンラインの両方でモデルのパフォーマンスを高めることができました。
採用したもう 1 つの重要な情報は、ファイル名です。たとえば、PDF ファイルを扱う場合に、モデルはそれがテキスト文書であることを判断できても、どのような内容のドキュメントであるかはわかりません。ファイル名を取得できれば、そこから何かヒントが得られるかもしれません。まずは、自然言語処理の世界で Bag of Words(単語の袋)モデルと呼ばれる方法にならい、ファイル名を文字の袋として扱い、シグナルとして取り入れました。
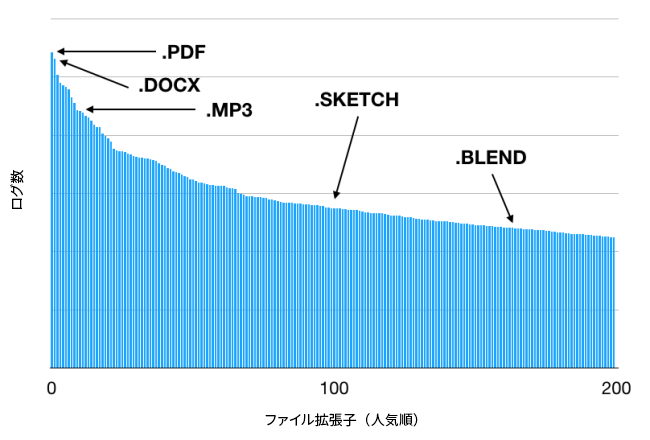
このモデルでは、ファイル名から語義までは抽出できませんでしたが、そのファイルがユーザーによって生成されたものか、システムが生成したものかを区別するには有益で、結果としてオフラインでの評価の質がある程度は高まりました。その後、char-RNN を使用したシーケンシャル モデルに移行しました。この手法ではファイル名を 1 文字ずつ取り込みます。すべての文字を取り込んだ後の char-RNN の状態ベクトルは、ファイル名の埋め込みベクトルとして使用できるようになります。このようなシーケンシャル モデルは、「j8i2ex915ed.bin」 のような一時ファイルの名前を検出するのに効果的です。
char-RNN によって、ファイル名を 1 つの特徴としてコンテンツの提案モデルに取り入れることができます。
2. クラウドベースのドキュメントを処理する
冒頭で述べたように、Dropbox ではさまざまなサードパーティ コンテンツをサポートしており、Dropbox から直接クラウドベースのファイル(Google ドキュメントや Microsoft Office 365 ファイルなど)を作成することが可能です。コンテンツの提案モデルでも、こうしたコンテンツ タイプへの対応を目指しました。
しかし、こうした連携は比較的新しいパートナーシップによるもので、これまで日常的に使用してきた PDF や JPEG と比べるとトレーニング データがかなり不足しているという事実に突き当たりました。そこで、独立したデータセットを作成するという方法を選びました。そして、メインで使用しているファイル提案用データセットにこのクラウド コンテンツのデータセットをマージするのではなく、同じネットワーク アーキテクチャを使用して別のモデルをトレーニングする方法を採ることにしました。
3. フォルダの提案を設計する
コンテンツの提案機能が目指している究極のゴールは、ユーザーが重要なファイルをすぐに見つけられるようにすることです。しかし、簡易的なオンライン テストを行ってみたところ、クリック率ではフォルダを開く割合が明らかに高いことが明らかになりました。このテストは、ヒューリスティックから生成した複数のフォルダに、本来のコンテンツの提案モデル(ファイルのみ)から提示されたファイルの両方を混在させて行いました。ここで私たちはある仮説を立てました。
ユーザーは、目的のファイルにたどり着くため、たとえ 1 クリック余計に操作しても、作業ファイルが置かれているフォルダに素早くアクセスできる方を好むのではないか、というものです。フォルダ 1 つを提案するのは、そこに含まれる複数のファイルを提示するよりも便利ともいえます。そのフォルダ自体はまさに求めているものではないかもしれませんが、目的のファイルに到達するために 1 クリック余計に操作してもかまわないのであれば、その他の候補にたどり着く余地を残しておくという点で、全体的な再現率を高めることができます。
重要なファイルと親フォルダのどちらを提示した方がよいのか、というのは興味深い問題です。この問いに答えるには、ユーザーによるフィードバックを得る必要がありました。そのため早い段階で、ファイルの表示とフォルダの表示を別々に行うという方法に舵を切ることにしました。ファイルとフォルダを分離しても、ファイルの提案機能を強化するために構築していたオフラインのデータとトレーニング パイプラインをフォルダの提案に再利用することは可能でした。別々のモデルをトレーニングし、その後で結合モデルを使用してそれら 2 つの結果候補リストを融合させました。これについては、この記事の後半で解説しています
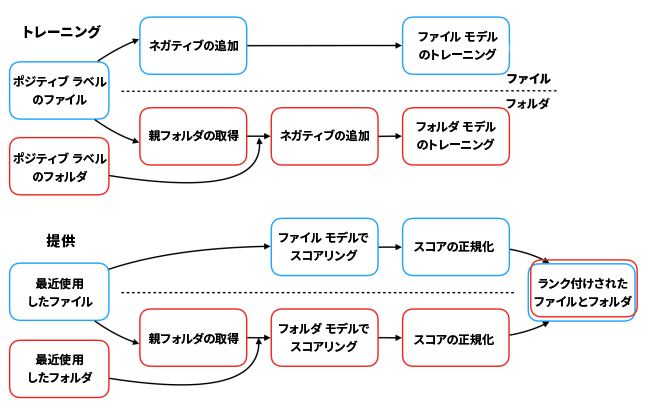
非常によく似たパイプラインを使用して、ファイル用とフォルダ用のモデルをトレーニングし提供しています。
既存のパイプラインを再利用すると同時に、フォルダの処理に適した次の微調整を加えました。
- 候補の生成:ファイルの提案であれば、直近でユーザーによるイベントが確認できるファイルのリストを取得するだけで十分です。しかしフォルダの提案では、イベントが確認できるフォルダに加えて、前述のファイルの親フォルダも取得します。
- シグナルの取得:ファイルの提案では、候補ファイルに対する過去 90 日間のイベントを取得しています。一方、フォルダの提案では、候補フォルダ自体のイベントに加えて、候補フォルダ内に置かれているファイルのイベントも取得します。この方法により、「高重要度」ファイルがごくわずか含まれるフォルダだけでなく、「低重要度」ファイルが多く含まれそうなフォルダも認識でき、どのフォルダに高いランクを付けるかをモデルが判断できます。
- トレーニング データの作成:前回のブログ投稿では、オフライン データセットの実際的な候補を取得するために 2 種類の情報源を使用していると書きました。1 つ目は、ヒューリスティックによるオンライン テストを実施して得たデータにラベルを付けたものです。2 つ目は、Dropbox でのユーザー イベントの教師なしデータセットです。このデータセットから、近い将来ファイルが操作されるかどうかを予測するための教師ありデータセットを作成することができました。2 番目のケースでは、「今後のファイル操作」の定義を変更し、フォルダに対する直接操作とフォルダ内のいくつかのファイルに対する操作をどちらも対象にしました。
オフラインのパイプラインにこうした変更を行ったことで、ファイルのスコアリングと同じ方法でフォルダをスコアリングするようにモデルをトレーニングできました。
4. 補足:トレーニング インフラストラクチャの強化
私たちが使用していたニューラル ネットワークはそれほどディープなものではありませんでしたが、ここまで述べてきたように、テストでは多くの新しいシグナル、データセット、微調整を試しました。そのため、テストを繰り返し実行し、ハイパーパラメーターを調整する業務が何度も必要で、煩雑でした。とりわけハイパーパラメーターのセットは非常に大規模で、たとえばネットワークの深さや幅、オプティマイザの選択、学習レート、有効化機能や正則化機能などが多岐にわたりました。それまで、こうしたハイパーパラメーターの最適化には素朴なグリッド検索を使用していましたが、グリッド検索はコストが高く非効率であることがよく知られています。
トレーニング ジョブを効果的に実施するため、Dropbox の機械学習インフラストラクチャ チームは dbxlearn というツールを新たに開発しました。dbxlearn は、機械学習のトレーニングを行うための柔軟で拡張性に優れたコンピューティング環境で、ハイパーパラメーターの調整にベイズ最適化などのより高度なアルゴリズムを使用することができます。dbxlearn を使用したことで、オフライン テストでの調整作業を多数実施することができました。また、さまざまなシグナル、データ、モデルを圧倒的に早いサイクルでテストすることもできました。その結果、ベストなモデルを導き出し、コンテンツの提案に最適なユーザー エクスペリエンスの構築に成功しました。
5. Paper ドキュメントの処理
先週、Paper ドキュメントは Dropbox ファイル システムに統合されました。しかし、コンテンツの提案モデルはこの統合よりも前に開発されていたため、当時ユーザーの Dropbox 環境に統合されていなかった Paper ドキュメントを一時的にサポートすることが必要になりました。そこで、クラウドベース ドキュメントに対して行ったのと同じように、Paper ドキュメントを処理するために別のデータセットとヒューリスティックを新たに作成し、その結果をインテリジェントにマージすることにしました。詳しくは次のセクションで解説します。
6. 各モデルの融合
ここまでは、コンテンツ タイプごとに個々のモデルを開発した経緯をお話ししました。次に取り組むべき課題は、これらのサブモデルが返した候補を比較してランキングを付けることです。これを実現するため、各サブモデルが生成したスコアを、以下のプロパティを使用するブラックボックス関数としてモデル化しました。
- サブモデルごとに関数 f を定め、サブモデルが生成したスコアを、そのスコアの提案アイテムに対して予測される CTR にマッピングします。
- f は、連続性のある単調関数です。
各サブモデルにこうした f があれば、サブモデルから生成されたスコアを f によってマッピングすることで、予測される CTR を取得でき、サブモデル間で定量的な比較が可能になります。すべてのサブモデルから出された全候補の予測 CTR を取得した後は、その CTR を基準に候補をランク付けできます。
実際には、f が 3 次スプラインであるという仮定をさらに設けました。このように仮定することで、f の式を離散化することができました。数列 {(s_i, l_i)} において、s_i がサブモデルのスコアで、l_i がクリックまたは非クリックに対応する指標変数である場合、所定の f の数列における対数尤度は次の式で表されます。
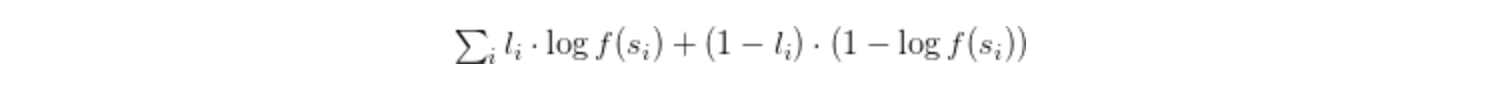
次に、f に対して制約を適用すれば、対数尤度を最大化する f のスプライン パラメーターを回復することができます。
サブモデルから生成されたランク付けされたアイテムのデータセットを与えることで、観測から帰納的に導かれる確率が最大になる関数を見つけることができます。この関数を 3 次スプラインとしてモデル化し、未加工のスコア分布に沿ってサンプリングしたうえで、問題を離散化します。
こうした正規化関数を解くには、特定のスコアのアイテムがどれくらいの確率でクリックされるのかを測定できるオンライン テストを最初に実施する必要があります。この問題を自力で解決するため、まずは実稼働環境のモデルでシャドウとしてサブモデルを実行しました。つまり、ユーザーには結果を見せずに、候補とスコアを生成したのです。次に、結果として得たスコアのヒストグラムを並べて、スコアの単純なアフィン変換を導き出し、これを基に初期の複合モデルを作成しました。この複合モデルをその後、ユーザーに表示される新しいオンライン テストで使用して、前述の説明で必要なスコアやラベルを得ることができました。この正規化関数によって生成された新しい複合モデルにより、全体的な CTR が向上したことを確認しています。
7. まとめ
この記事で解説した個々の機能強化と各種技術の組み合わせについては、統計的な有意性が得られるまで、ホームページにログインしたユーザーに対してオンラインの A/B テストを行って検証しました。また、その他の実験的なアイデアも得ることができました。実施したテストの中には、有益でない結果を生み出すものもあり、そうした手法は実稼働モデルに採り入れませんでした。最終的には、提案コンテンツが 1 回以上クリックされるユーザー セッションの割合を 50 % 以上も増やすことができました。この結果に自信を得て、実稼働モデルを大々的に導入することになりました。
AI を活用した機能を Dropbox の全ユーザーに導入することは、多くのチームの協力があってこそ実現できた一大プロジェクトでした。機械学習エンジニアの取り組みはもちろん、ML インフラストラクチャ チームの働きも、AI による提案に関するユーザー エクスペリエンスの構築に携わったチームも、ユーザーに価値を提供するうえで等しく重要な役割を果たしています。